Investigating the Impact of Choice on Deep Reinforcement Learning for Space Controls

0
🤿
Sign in to get full access
Overview
- Traditional control methods are commonly used for space applications
- As the number of space assets grows, autonomous operation can enable rapid development of control methods for different space-related tasks
- Reinforcement Learning (RL) is a promising method for developing autonomous control, but it may not be realistic or practical for space tasks that prefer an on/off approach for control
- This paper analyzes using discrete action spaces, where the agent must choose from a predefined list of actions, for space-related tasks
Plain English Explanation
When it comes to controlling and operating space-related equipment and vehicles, traditional control methods are often used. However, as the number of space assets continues to increase, there is a growing need for more autonomous control methods that can be rapidly developed and adapted for different space-related tasks.
One approach that has shown promise in this area is Reinforcement Learning (RL). RL allows an agent to learn how to control a system by interacting with it and receiving feedback on its actions. This has been successful in many complex tasks, but it may not be the best fit for some space applications.
Many space-related tasks, such as inspecting or docking with another spacecraft, traditionally prefer an on/off approach to control, rather than the continuous control that RL agents often learn. This paper explores the use of discrete action spaces, where the agent must choose from a predefined list of actions, for these types of space-related tasks.
The researchers conducted experiments to see how the number of choices provided to the agents affected their performance during and after training. They looked at two specific tasks: an inspection task, where the agent must circumnavigate an object to inspect points on its surface, and a docking task, where the agent must move into proximity of another spacecraft and dock with a low relative speed. In both cases, a key objective is to minimize fuel usage, which motivates the agent to regularly choose an action that uses no fuel.
Technical Explanation
The paper explores the use of discrete action spaces for RL agents in space-related tasks, as opposed to the more common continuous control approach.
In the experiments, the researchers tested how the number of discrete actions available to the agents affected their performance on an inspection task and a docking task. For the inspection task, the results showed that a limited number of discrete choices led to optimal performance, while for the docking task, continuous control led to better results.
The key reason for this difference is the nature of the tasks themselves. The inspection task favors an on/off approach, where the agent can choose from a predefined set of actions to navigate around the object. In contrast, the docking task requires more precise control over the spacecraft's movement, which is better suited to a continuous control approach.
Additionally, both tasks shared a common objective of minimizing fuel usage, which motivated the agents to regularly choose an action that consumed no fuel. This highlights the importance of aligning the control approach with the specific requirements and objectives of the space-related task at hand.
Critical Analysis
The paper presents an interesting exploration of the role of action spaces in RL agents for space-related tasks. However, it is important to note that the experiments were conducted in simulation, and the findings may not directly translate to real-world space applications.
One potential limitation is the simplification of the tasks and the environment. In reality, space-related tasks often involve complex dynamics, environmental factors, and unexpected events that may not be fully captured in the simulated scenarios. Further research is needed to [assess the performance of these approaches in more realistic, adaptive and challenging settings.
Additionally, the paper does not explore the potential trade-offs between the discrete and continuous control approaches, such as the computational complexity, training stability, or the ability to handle uncertain or changing environments. These factors may also play a crucial role in the real-world feasibility and applicability of the techniques discussed.
Conclusion
This paper presents an interesting exploration of the use of discrete action spaces for RL agents in space-related tasks, such as inspection and docking. The results suggest that the choice of action space can have a significant impact on the agent's performance, depending on the specific requirements and objectives of the task.
The findings highlight the importance of carefully considering the control approach when developing autonomous systems for space applications, where traditional methods may not be sufficient. By understanding the strengths and limitations of different RL approaches, researchers and engineers can work towards more robust and efficient control solutions for the growing number of space assets and missions.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤿
0
Investigating the Impact of Choice on Deep Reinforcement Learning for Space Controls
Nathaniel Hamilton, Kyle Dunlap, Kerianne L. Hobbs
For many space applications, traditional control methods are often used during operation. However, as the number of space assets continues to grow, autonomous operation can enable rapid development of control methods for different space related tasks. One method of developing autonomous control is Reinforcement Learning (RL), which has become increasingly popular after demonstrating promising performance and success across many complex tasks. While it is common for RL agents to learn bounded continuous control values, this may not be realistic or practical for many space tasks that traditionally prefer an on/off approach for control. This paper analyzes using discrete action spaces, where the agent must choose from a predefined list of actions. The experiments explore how the number of choices provided to the agents affects their measured performance during and after training. This analysis is conducted for an inspection task, where the agent must circumnavigate an object to inspect points on its surface, and a docking task, where the agent must move into proximity of another spacecraft and dock with a low relative speed. A common objective of both tasks, and most space tasks in general, is to minimize fuel usage, which motivates the agent to regularly choose an action that uses no fuel. Our results show that a limited number of discrete choices leads to optimal performance for the inspection task, while continuous control leads to optimal performance for the docking task.
Read more5/22/2024

0
Deep Reinforcement Learning Behavioral Mode Switching Using Optimal Control Based on a Latent Space Objective
Sindre Benjamin Remman, Bj{o}rn Andreas Kristiansen, Anastasios M. Lekkas
In this work, we use optimal control to change the behavior of a deep reinforcement learning policy by optimizing directly in the policy's latent space. We hypothesize that distinct behavioral patterns, termed behavioral modes, can be identified within certain regions of a deep reinforcement learning policy's latent space, meaning that specific actions or strategies are preferred within these regions. We identify these behavioral modes using latent space dimension-reduction with ac*{pacmap}. Using the actions generated by the optimal control procedure, we move the system from one behavioral mode to another. We subsequently utilize these actions as a filter for interpreting the neural network policy. The results show that this approach can impose desired behavioral modes in the policy, demonstrated by showing how a failed episode can be made successful and vice versa using the lunar lander reinforcement learning environment.
Read more6/4/2024
🤿
0
Deep Reinforcement Learning in Parameterized Action Space
Matthew Hausknecht, Peter Stone
Recent work has shown that deep neural networks are capable of approximating both value functions and policies in reinforcement learning domains featuring continuous state and action spaces. However, to the best of our knowledge no previous work has succeeded at using deep neural networks in structured (parameterized) continuous action spaces. To fill this gap, this paper focuses on learning within the domain of simulated RoboCup soccer, which features a small set of discrete action types, each of which is parameterized with continuous variables. The best learned agent can score goals more reliably than the 2012 RoboCup champion agent. As such, this paper represents a successful extension of deep reinforcement learning to the class of parameterized action space MDPs.
Read more5/6/2024
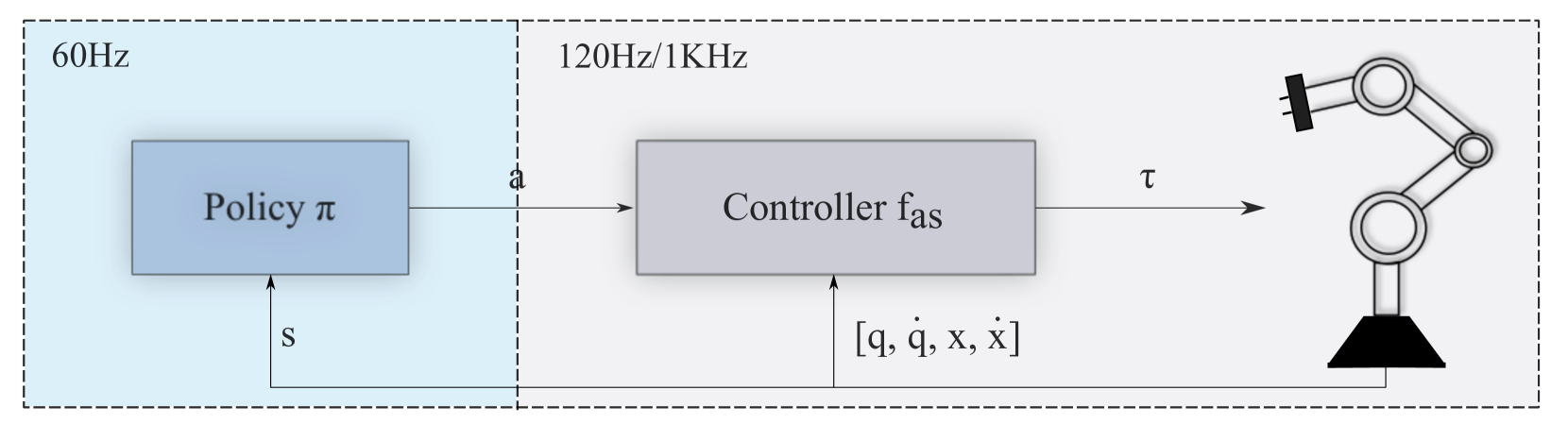
0
On the Role of the Action Space in Robot Manipulation Learning and Sim-to-Real Transfer
Elie Aljalbout, Felix Frank, Maximilian Karl, Patrick van der Smagt
We study the choice of action space in robot manipulation learning and sim-to-real transfer. We define metrics that assess the performance, and examine the emerging properties in the different action spaces. We train over 250 reinforcement learning~(RL) agents in simulated reaching and pushing tasks, using 13 different control spaces. The choice of spaces spans combinations of common action space design characteristics. We evaluate the training performance in simulation and the transfer to a real-world environment. We identify good and bad characteristics of robotic action spaces and make recommendations for future designs. Our findings have important implications for the design of RL algorithms for robot manipulation tasks, and highlight the need for careful consideration of action spaces when training and transferring RL agents for real-world robotics.
Read more5/1/2024