Assessing the Emergent Symbolic Reasoning Abilities of Llama Large Language Models
2406.06588
0
0
Abstract
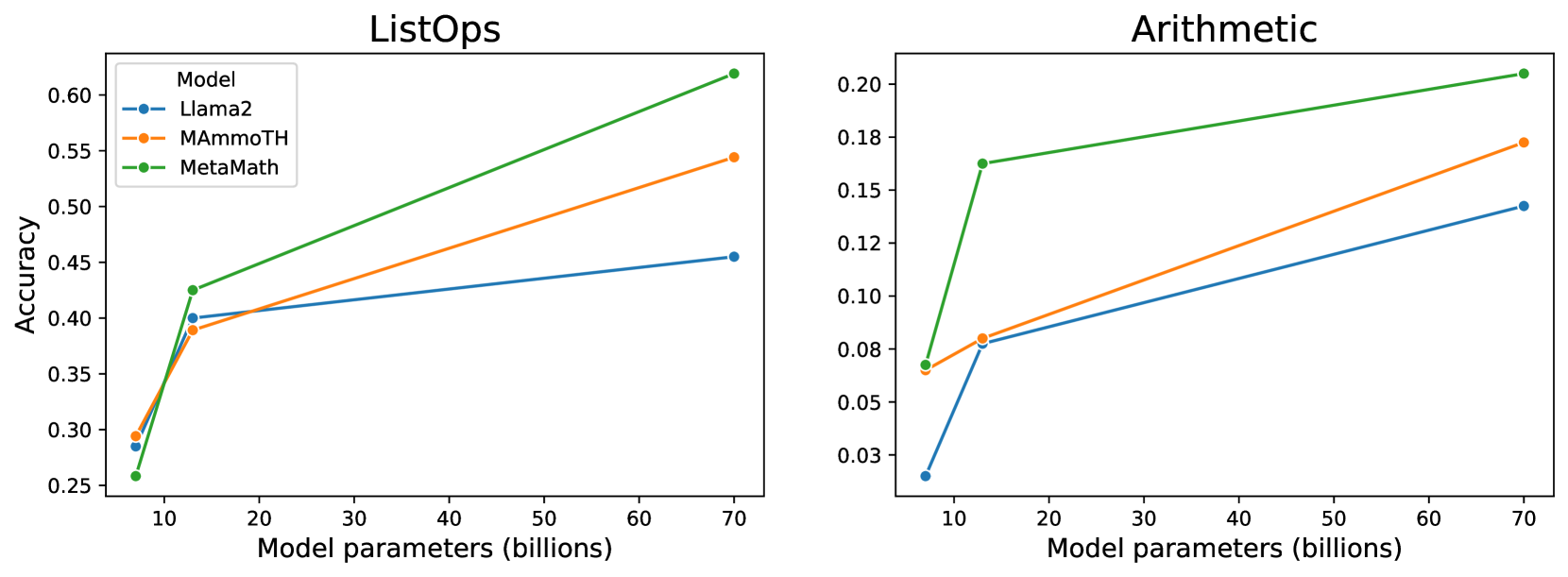
Large Language Models (LLMs) achieve impressive performance in a wide range of tasks, even if they are often trained with the only objective of chatting fluently with users. Among other skills, LLMs show emergent abilities in mathematical reasoning benchmarks, which can be elicited with appropriate prompting methods. In this work, we systematically investigate the capabilities and limitations of popular open-source LLMs on different symbolic reasoning tasks. We evaluate three models of the Llama 2 family on two datasets that require solving mathematical formulas of varying degrees of difficulty. We test a generalist LLM (Llama 2 Chat) as well as two fine-tuned versions of Llama 2 (MAmmoTH and MetaMath) specifically designed to tackle mathematical problems. We observe that both increasing the scale of the model and fine-tuning it on relevant tasks lead to significant performance gains. Furthermore, using fine-grained evaluation measures, we find that such performance gains are mostly observed with mathematical formulas of low complexity, which nevertheless often remain challenging even for the largest fine-tuned models.
Create account to get full access
Overview
- This paper investigates the symbolic reasoning abilities of large language models (LLMs) like LLaMA.
- The researchers assess the models' performance on various tasks that require mathematical and logical reasoning, such as ListOps, arithmetic, and extrapolation.
- They also evaluate the models' deductive competence by testing their ability to make logical inferences.
Plain English Explanation
The paper examines how well large language models, which are AI systems trained on vast amounts of text data, can perform tasks that require symbolic reasoning and mathematical skills. The researchers designed a series of tests to assess the models' abilities in areas like logic, arithmetic, and extrapolation (making predictions based on patterns).
For example, one test involved presenting the models with a sequence of numbers and asking them to identify the pattern and continue the sequence. Another test measured their ability to make logical deductions based on given premises. The researchers wanted to see if these models, which have shown impressive language understanding and generation capabilities, could also demonstrate symbolic reasoning skills that were previously thought to require more specialized AI systems.
By evaluating the models' performance on these tasks, the researchers aimed to gain insights into the emergent reasoning abilities of large language models and explore the potential and limitations of using them for more advanced cognitive tasks beyond just language processing.
Technical Explanation
The paper presents a comprehensive evaluation of the symbolic reasoning abilities of large language models (LLMs) like LLaMA. The researchers designed a suite of tasks to assess the models' performance in areas such as ListOps, arithmetic, extrapolation, and deductive reasoning.
The researchers used a variety of LLM architectures, including transformer-based models, and evaluated their performance on tasks that required symbolic manipulation, logical inference, and mathematical problem-solving. The experimental design included both synthetic and natural language tasks to assess the models' abilities across different domains.
The results suggest that LLMs can exhibit some emergent symbolic reasoning capabilities, but the extent and robustness of these abilities vary across different tasks and model configurations. The paper provides insights into the strengths and limitations of these models in handling symbolic and logical reasoning problems, which have important implications for the development and deployment of LLMs in applications that require advanced cognitive skills.
Critical Analysis
The paper provides a comprehensive and rigorous evaluation of the symbolic reasoning abilities of LLMs, which is an important area of research as these models continue to advance in their language understanding and generation capabilities. However, the authors acknowledge several caveats and limitations of their work.
One key limitation is that the tasks used in the study, while carefully designed, may not fully capture the complexity and nuance of real-world symbolic reasoning challenges. Additionally, the performance of the LLMs was assessed on a limited set of tasks and model configurations, and it is unclear how well the findings would generalize to other architectures or problem domains.
The paper also does not delve deeply into the underlying mechanisms and representations that enable the models' emergent reasoning abilities. Further research is needed to elucidate the cognitive processes and architectural features that contribute to these capabilities.
Moreover, the paper does not address potential biases or pitfalls that may arise when deploying LLMs for tasks requiring symbolic reasoning, such as the risk of amplifying existing biases or producing erroneous logical inferences. These are important considerations that warrant further investigation.
Conclusion
This paper represents a significant contribution to the understanding of the symbolic reasoning abilities of large language models. The researchers have designed a comprehensive set of tasks to assess the models' performance in areas like logic, mathematics, and extrapolation, providing valuable insights into the emergent cognitive capabilities of these systems.
The findings suggest that LLMs can exhibit some symbolic reasoning skills, but their performance is often limited and varies across different tasks and model configurations. This highlights the need for continued research and development to further enhance the reasoning abilities of these models and address the potential challenges and risks associated with their deployment.
As LLMs continue to advance, it will be crucial to develop a deeper understanding of their cognitive mechanisms and limitations, as well as to explore ways to robustly integrate symbolic reasoning into these powerful language models. This paper lays the groundwork for these important lines of inquiry, which will have significant implications for the field of AI and its real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Investigating Symbolic Capabilities of Large Language Models
Neisarg Dave, Daniel Kifer, C. Lee Giles, Ankur Mali
0
0
Prompting techniques have significantly enhanced the capabilities of Large Language Models (LLMs) across various complex tasks, including reasoning, planning, and solving math word problems. However, most research has predominantly focused on language-based reasoning and word problems, often overlooking the potential of LLMs in handling symbol-based calculations and reasoning. This study aims to bridge this gap by rigorously evaluating LLMs on a series of symbolic tasks, such as addition, multiplication, modulus arithmetic, numerical precision, and symbolic counting. Our analysis encompasses eight LLMs, including four enterprise-grade and four open-source models, of which three have been pre-trained on mathematical tasks. The assessment framework is anchored in Chomsky's Hierarchy, providing a robust measure of the computational abilities of these models. The evaluation employs minimally explained prompts alongside the zero-shot Chain of Thoughts technique, allowing models to navigate the solution process autonomously. The findings reveal a significant decline in LLMs' performance on context-free and context-sensitive symbolic tasks as the complexity, represented by the number of symbols, increases. Notably, even the fine-tuned GPT3.5 exhibits only marginal improvements, mirroring the performance trends observed in other models. Across the board, all models demonstrated a limited generalization ability on these symbol-intensive tasks. This research underscores LLMs' challenges with increasing symbolic complexity and highlights the need for specialized training, memory and architectural adjustments to enhance their proficiency in symbol-based reasoning tasks.
5/24/2024

Large Language Models for Mathematical Reasoning: Progresses and Challenges
Janice Ahn, Rishu Verma, Renze Lou, Di Liu, Rui Zhang, Wenpeng Yin
0
0
Mathematical reasoning serves as a cornerstone for assessing the fundamental cognitive capabilities of human intelligence. In recent times, there has been a notable surge in the development of Large Language Models (LLMs) geared towards the automated resolution of mathematical problems. However, the landscape of mathematical problem types is vast and varied, with LLM-oriented techniques undergoing evaluation across diverse datasets and settings. This diversity makes it challenging to discern the true advancements and obstacles within this burgeoning field. This survey endeavors to address four pivotal dimensions: i) a comprehensive exploration of the various mathematical problems and their corresponding datasets that have been investigated; ii) an examination of the spectrum of LLM-oriented techniques that have been proposed for mathematical problem-solving; iii) an overview of factors and concerns affecting LLMs in solving math; and iv) an elucidation of the persisting challenges within this domain. To the best of our knowledge, this survey stands as one of the first extensive examinations of the landscape of LLMs in the realm of mathematics, providing a holistic perspective on the current state, accomplishments, and future challenges in this rapidly evolving field.
4/8/2024

Caught in the Quicksand of Reasoning, Far from AGI Summit: Evaluating LLMs' Mathematical and Coding Competency through Ontology-guided Interventions
Pengfei Hong, Navonil Majumder, Deepanway Ghosal, Somak Aditya, Rada Mihalcea, Soujanya Poria
0
0
Recent advancements in Large Language Models (LLMs) have showcased striking results on existing logical reasoning benchmarks, with some models even surpassing human performance. However, the true depth of their competencies and robustness in reasoning tasks remains an open question. To this end, in this paper, we focus on two popular reasoning tasks: arithmetic reasoning and code generation. Particularly, we introduce: (i) a general ontology of perturbations for maths and coding questions, (ii) a semi-automatic method to apply these perturbations, and (iii) two datasets, MORE and CORE, respectively, of perturbed maths and coding problems to probe the limits of LLM capabilities in numeric reasoning and coding tasks. Through comprehensive evaluations of both closed-source and open-source LLMs, we show a significant performance drop across all the models against the perturbed questions, suggesting that the current LLMs lack robust problem solving skills and structured reasoning abilities in many areas, as defined by our ontology. We open source the datasets and source codes at: https://github.com/declare-lab/llm_robustness.
6/28/2024
Mathify: Evaluating Large Language Models on Mathematical Problem Solving Tasks
Avinash Anand, Mohit Gupta, Kritarth Prasad, Navya Singla, Sanjana Sanjeev, Jatin Kumar, Adarsh Raj Shivam, Rajiv Ratn Shah
0
0
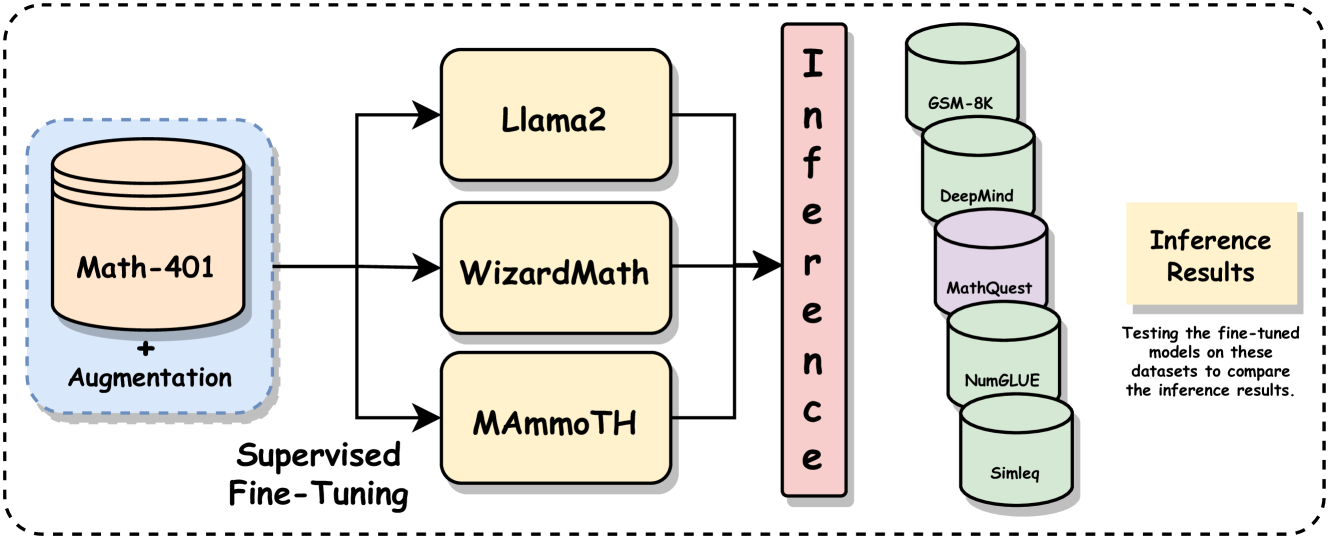
The rapid progress in the field of natural language processing (NLP) systems and the expansion of large language models (LLMs) have opened up numerous opportunities in the field of education and instructional methods. These advancements offer the potential for tailored learning experiences and immediate feedback, all delivered through accessible and cost-effective services. One notable application area for this technological advancement is in the realm of solving mathematical problems. Mathematical problem-solving not only requires the ability to decipher complex problem statements but also the skill to perform precise arithmetic calculations at each step of the problem-solving process. However, the evaluation of the arithmetic capabilities of large language models remains an area that has received relatively little attention. In response, we introduce an extensive mathematics dataset called MathQuest sourced from the 11th and 12th standard Mathematics NCERT textbooks. This dataset encompasses mathematical challenges of varying complexity and covers a wide range of mathematical concepts. Utilizing this dataset, we conduct fine-tuning experiments with three prominent LLMs: LLaMA-2, WizardMath, and MAmmoTH. These fine-tuned models serve as benchmarks for evaluating their performance on our dataset. Our experiments reveal that among the three models, MAmmoTH-13B emerges as the most proficient, achieving the highest level of competence in solving the presented mathematical problems. Consequently, MAmmoTH-13B establishes itself as a robust and dependable benchmark for addressing NCERT mathematics problems.
4/23/2024