Is It Good Data for Multilingual Instruction Tuning or Just Bad Multilingual Evaluation for Large Language Models?
2406.12822
0
0
📊
Abstract
Large language models, particularly multilingual ones, are designed, claimed, and expected to cater to native speakers of varied languages. We hypothesise that the current practices of fine-tuning and evaluating these models may mismatch this intention owing to a heavy reliance on translation, which can introduce translation artefacts and defects. It remains unknown whether the nature of the instruction data has an impact on the model output; on the other hand, it remains questionable whether translated test sets can capture such nuances. Due to the often coupled practices of using translated data in both stages, such imperfections could have been overlooked. This work investigates these issues by using controlled native or translated data during instruction tuning and evaluation stages and observing model results. Experiments on eight base models and eight different benchmarks reveal that native or generation benchmarks display a notable difference between native and translated instruction data especially when model performance is high, whereas other types of test sets cannot. Finally, we demonstrate that regularization is beneficial to bridging this gap on structured but not generative tasks.
Create account to get full access
Overview
- Large language models are designed to serve speakers of diverse languages, but the current practices of fine-tuning and evaluating these models may not align with this goal.
- The use of translated data in both training and evaluation stages can introduce artifacts and defects that may impact model performance.
- This work investigates the impact of using native vs. translated data for instruction tuning and evaluation, and explores the role of regularization in bridging any performance gaps.
Plain English Explanation
Large language models are powerful AI systems that can understand and generate human-like text in multiple languages. The researchers behind this study wanted to see if the way these models are currently fine-tuned (a process of further training them on specific tasks) and evaluated (tested to measure their performance) is actually well-suited for serving speakers of different languages.
The key issue is that a lot of the training and testing data used for these models is often translated from one language to another. This translation process can introduce small errors or changes that might not be captured by the standard evaluation methods. As a result, the models' true capabilities in handling diverse languages may be misrepresented.
To investigate this, the researchers ran experiments using either native (original) language data or translated data during the fine-tuning and evaluation stages. They looked at how the models' performance differed depending on the type of data used. Interestingly, they found that the models performed notably better on native-language tasks compared to translated tasks, especially when their overall performance was high.
The researchers also explored whether applying certain regularization techniques (methods to prevent overfitting) could help bridge the gap between native and translated data performance. They found that regularization was helpful for structured tasks, but not as effective for more open-ended, generative tasks.
Technical Explanation
The researchers hypothesized that the current practices of fine-tuning and evaluating multilingual language models may not align with their intended purpose of serving diverse language speakers. Specifically, they were concerned about the heavy reliance on translated data, which could introduce artifacts and defects.
To investigate this, they conducted experiments using eight different base models and eight benchmark tasks. They compared model performance when using either native or translated data for the instruction tuning stage and the evaluation stage. The experiments revealed that on native or generation-based benchmarks, there was a notable difference in performance between native and translated instruction data, particularly when the models' overall performance was high.
Interestingly, other types of test sets did not consistently capture this performance gap. The researchers attributed this to the potential mismatch between the translation artifacts introduced during training and the characteristics of the evaluation data.
Furthermore, the study explored the role of regularization in bridging the performance gap between native and translated data. They found that regularization techniques were beneficial for structured tasks, but not as effective for more open-ended, generative tasks.
Critical Analysis
The researchers acknowledge that their study is limited in scope and does not explore all possible factors that may contribute to the observed performance differences. For example, they did not investigate the impact of different translation approaches or the quality of the translation data used.
Additionally, the paper does not delve into the specific nature of the translation artifacts or defects that may be introduced and how they might differentially impact the various benchmark tasks. Further research would be needed to understand the underlying mechanisms driving the performance gaps.
It is also worth considering whether the observed patterns would hold true for a wider range of language models and tasks, or if they are specific to the particular models and benchmarks examined in this study.
Conclusion
This research highlights the potential mismatch between the intended multilingual capabilities of large language models and the current practices of fine-tuning and evaluating them. The findings suggest that the use of translated data in both training and evaluation stages may not fully capture the models' true performance in handling diverse languages.
The study's insights underscore the importance of carefully designing evaluation protocols and considering the impact of translation artifacts on model performance. As the field of large language models continues to advance, it will be crucial to ensure that these powerful systems are developed and assessed in a way that truly serves the needs of speakers from around the world.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
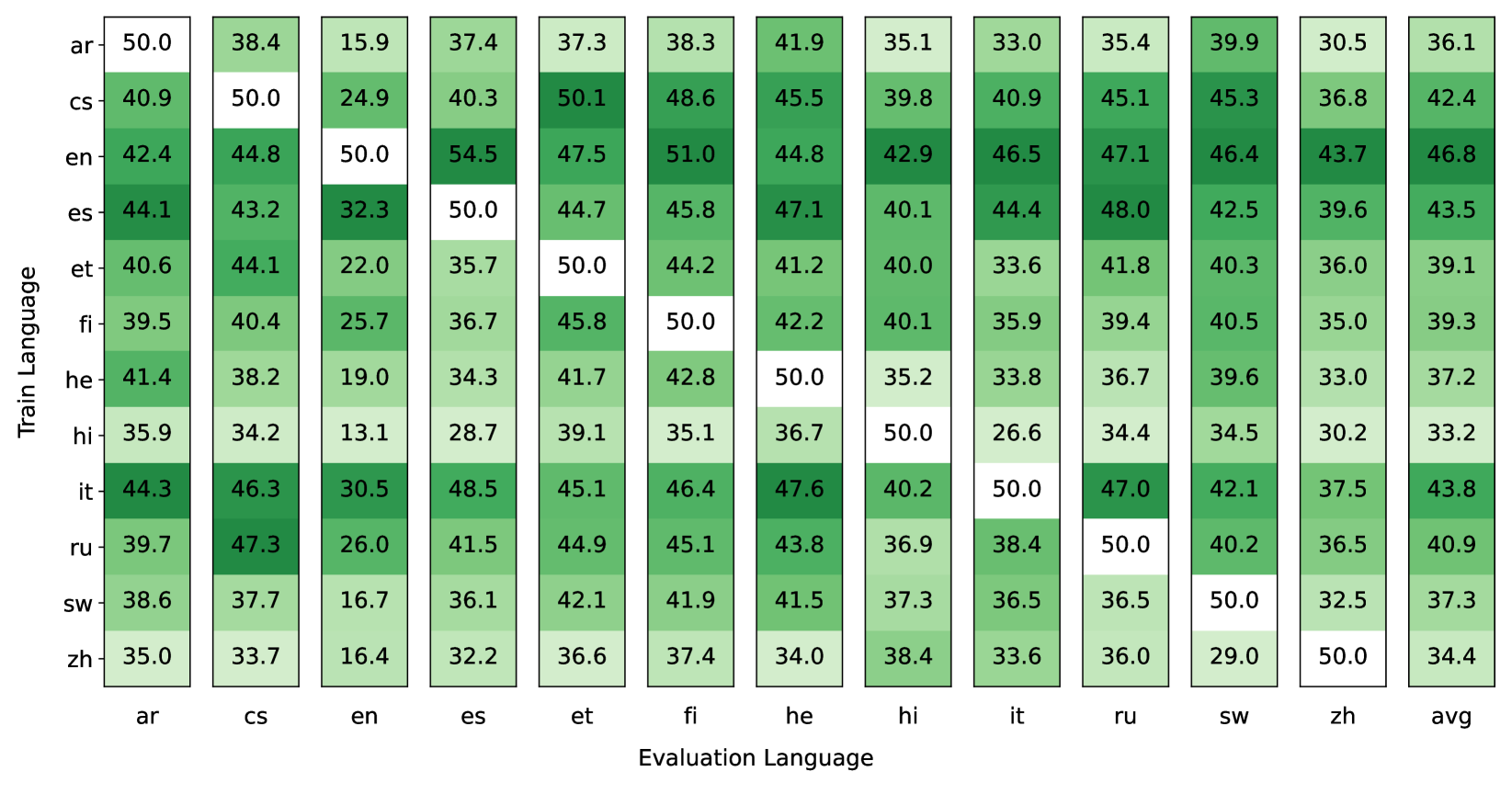
Multilingual Instruction Tuning With Just a Pinch of Multilinguality
Uri Shaham, Jonathan Herzig, Roee Aharoni, Idan Szpektor, Reut Tsarfaty, Matan Eyal
0
0
As instruction-tuned large language models (LLMs) gain global adoption, their ability to follow instructions in multiple languages becomes increasingly crucial. In this work, we investigate how multilinguality during instruction tuning of a multilingual LLM affects instruction-following across languages from the pre-training corpus. We first show that many languages transfer some instruction-following capabilities to other languages from even monolingual tuning. Furthermore, we find that only 40 multilingual examples integrated in an English tuning set substantially improve multilingual instruction-following, both in seen and unseen languages during tuning. In general, we observe that models tuned on multilingual mixtures exhibit comparable or superior performance in multiple languages compared to monolingually tuned models, despite training on 10x fewer examples in those languages. Finally, we find that diversifying the instruction tuning set with even just 2-4 languages significantly improves cross-lingual generalization. Our results suggest that building massively multilingual instruction-tuned models can be done with only a very small set of multilingual instruction-responses.
5/22/2024
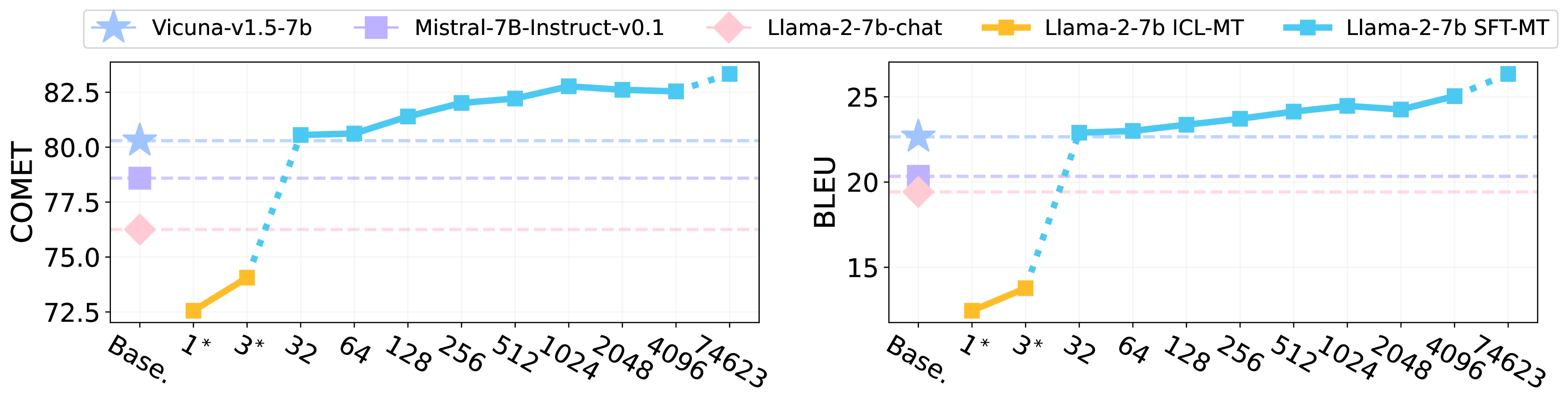
Fine-Tuning Large Language Models to Translate: Will a Touch of Noisy Data in Misaligned Languages Suffice?
Dawei Zhu, Pinzhen Chen, Miaoran Zhang, Barry Haddow, Xiaoyu Shen, Dietrich Klakow
0
0
Traditionally, success in multilingual machine translation can be attributed to three key factors in training data: large volume, diverse translation directions, and high quality. In the current practice of fine-tuning large language models (LLMs) for translation, we revisit the importance of all these factors. We find that LLMs display strong translation capability after being fine-tuned on as few as 32 training instances, and that fine-tuning on a single translation direction effectively enables LLMs to translate in multiple directions. However, the choice of direction is critical: fine-tuning LLMs with English on the target side can lead to task misinterpretation, which hinders translations into non-English languages. A similar problem arises when noise is introduced into the target side of parallel data, especially when the target language is well-represented in the LLM's pre-training. In contrast, noise in an under-represented language has a less pronounced effect. Our findings suggest that attaining successful alignment hinges on teaching the model to maintain a superficial focus, thereby avoiding the learning of erroneous biases beyond translation.
4/23/2024
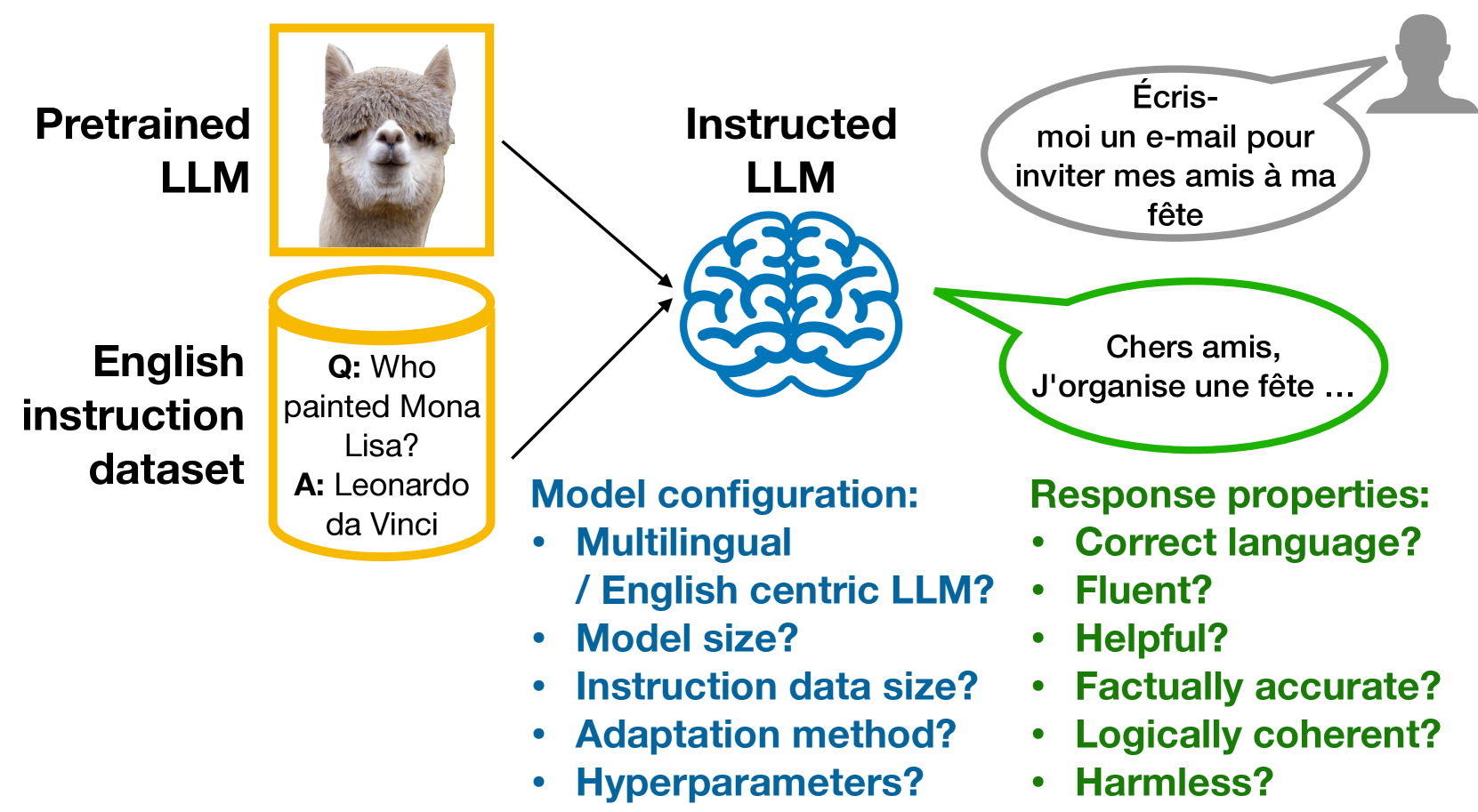
Zero-shot cross-lingual transfer in instruction tuning of large language models
Nadezhda Chirkova, Vassilina Nikoulina
0
0
Instruction tuning (IT) is widely used to teach pretrained large language models (LLMs) to follow arbitrary instructions, but is under-studied in multilingual settings. In this work, we conduct a systematic study of zero-shot cross-lingual transfer in IT, when an LLM is instruction-tuned on English-only data and then tested on user prompts in other languages. We advocate for the importance of evaluating various aspects of model responses in multilingual instruction following and investigate the influence of different model configuration choices. We find that cross-lingual transfer does happen successfully in IT even if all stages of model training are English-centric, but only if multiliguality is taken into account in hyperparameter tuning and with large enough IT data. English-trained LLMs are capable of generating correct-language, comprehensive and helpful responses in other languages, but suffer from low factuality and may occasionally have fluency errors.
4/23/2024
🏷️
Using Machine Translation to Augment Multilingual Classification
Adam King
0
0
An all-too-present bottleneck for text classification model development is the need to annotate training data and this need is multiplied for multilingual classifiers. Fortunately, contemporary machine translation models are both easily accessible and have dependable translation quality, making it possible to translate labeled training data from one language into another. Here, we explore the effects of using machine translation to fine-tune a multilingual model for a classification task across multiple languages. We also investigate the benefits of using a novel technique, originally proposed in the field of image captioning, to account for potential negative effects of tuning models on translated data. We show that translated data are of sufficient quality to tune multilingual classifiers and that this novel loss technique is able to offer some improvement over models tuned without it.
5/10/2024