Fine-Tuning Large Language Models to Translate: Will a Touch of Noisy Data in Misaligned Languages Suffice?
2404.14122
0
0
Abstract
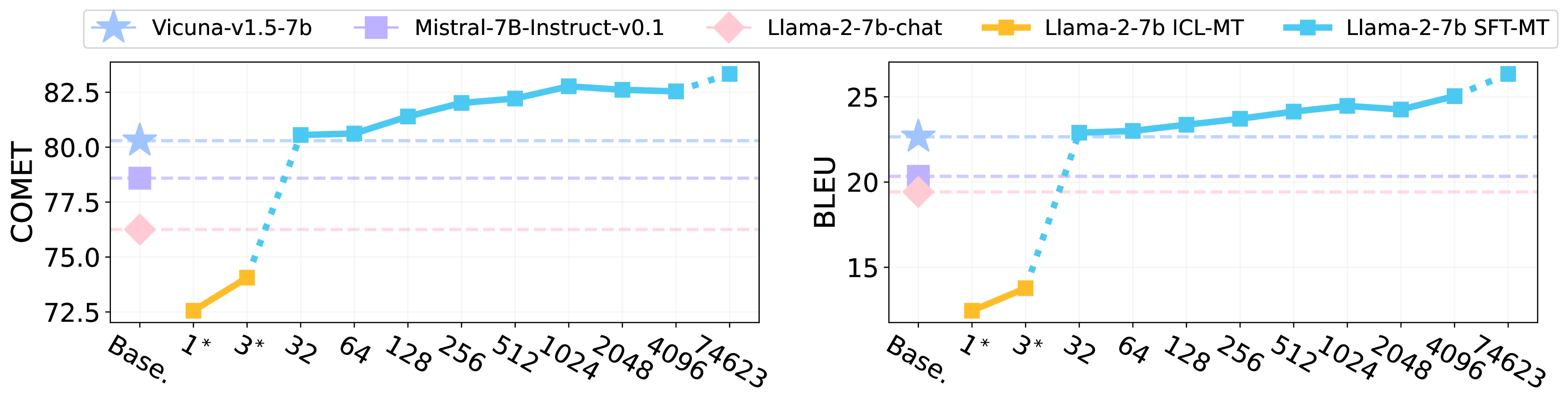
Traditionally, success in multilingual machine translation can be attributed to three key factors in training data: large volume, diverse translation directions, and high quality. In the current practice of fine-tuning large language models (LLMs) for translation, we revisit the importance of all these factors. We find that LLMs display strong translation capability after being fine-tuned on as few as 32 training instances, and that fine-tuning on a single translation direction effectively enables LLMs to translate in multiple directions. However, the choice of direction is critical: fine-tuning LLMs with English on the target side can lead to task misinterpretation, which hinders translations into non-English languages. A similar problem arises when noise is introduced into the target side of parallel data, especially when the target language is well-represented in the LLM's pre-training. In contrast, noise in an under-represented language has a less pronounced effect. Our findings suggest that attaining successful alignment hinges on teaching the model to maintain a superficial focus, thereby avoiding the learning of erroneous biases beyond translation.
Create account to get full access
Overview
- This paper explores the potential for fine-tuning large language models (LLMs) to perform machine translation tasks using noisy and misaligned data, rather than high-quality parallel corpora.
- The researchers investigate whether a "touch of noisy data" in non-aligned languages can be sufficient to translate effectively, which could significantly reduce the cost and effort required to develop multilingual translation capabilities.
- The paper presents several experiments and analyses to understand the impact of different fine-tuning strategies, data quality, and language alignment on the translation performance of LLMs.
Plain English Explanation
Large language models (LLMs) have shown impressive capabilities in a wide range of tasks, including machine translation. However, training these models for multilingual translation typically requires extensive high-quality parallel data, which can be expensive and time-consuming to obtain.
This research explores an alternative approach - using noisy, misaligned data to fine-tune LLMs for translation. The idea is that even if the training data is not perfectly aligned between languages, the LLM may still be able to learn effective translation capabilities by leveraging its broad language understanding. This could significantly reduce the cost and effort required to develop multilingual translation systems.
The researchers conduct various experiments to test this hypothesis, exploring different fine-tuning strategies, data quality, and language alignment. They analyze the translation performance of the fine-tuned LLMs to understand the tradeoffs and potential of this approach.
Technical Explanation
The paper begins by outlining the
To investigate this, the researchers design several experiments:
- They fine-tune an LLM using varying amounts of high-quality parallel data to establish a performance baseline.
- They then fine-tune the same LLM using noisy, misaligned data in non-aligned language pairs, such as English-Russian and English-Hindi.
- Finally, they explore a
novel paradigm where the LLM is first fine-tuned on noisy data, then further fine-tuned on high-quality parallel data.
The results show that the LLM can indeed learn to translate effectively using only a "touch of noisy data" in misaligned languages, though the performance is not as high as when using high-quality parallel data. The researchers also find that the
Critical Analysis
The researchers acknowledge that the translation quality achieved using noisy, misaligned data is not as high as when using high-quality parallel data. They also note that the performance varies depending on the specific language pairs and the amount of noisy data available.
Additionally, the researchers highlight the potential limitations of this approach. For example, they mention that the LLM may struggle with rare or domain-specific terminology, which may not be adequately covered by the noisy training data. Further research is needed to understand the
Another area for further exploration is the
Conclusion
This research presents an intriguing approach to fine-tuning LLMs for machine translation, which could significantly reduce the cost and effort required to develop multilingual translation capabilities. The key finding is that a "touch of noisy data" in misaligned languages can be sufficient for LLMs to acquire reasonable translation skills, opening up new possibilities for more accessible and scalable translation systems.
While the translation quality is not as high as when using high-quality parallel data, the researchers demonstrate that this approach can be a viable alternative, especially when parallel data is scarce or expensive to obtain. Further research is needed to address the limitations and optimize the fine-tuning process, but this study represents an important step forward in leveraging LLMs for more efficient and accessible multilingual translation.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
How Multilingual Are Large Language Models Fine-Tuned for Translation?
Aquia Richburg, Marine Carpuat
0
0
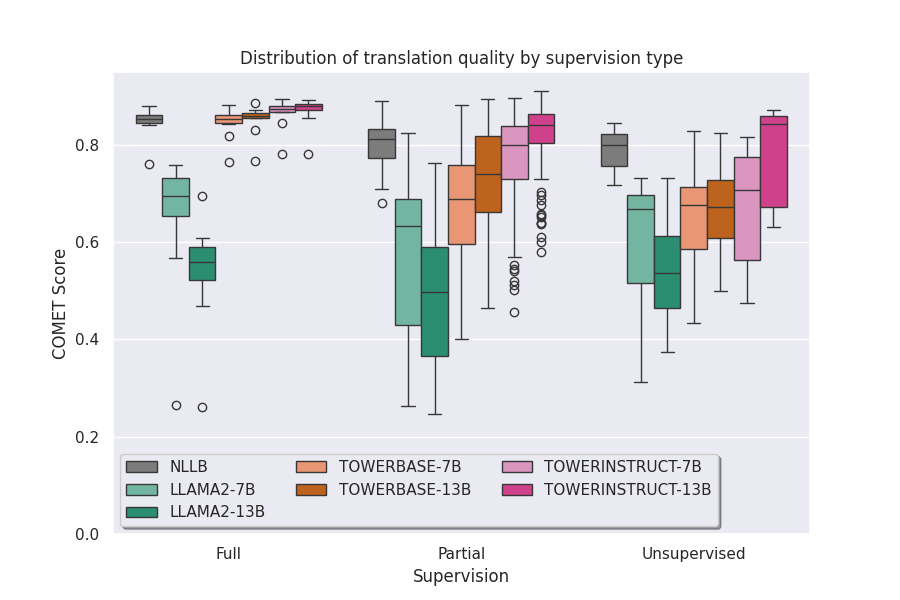
A new paradigm for machine translation has recently emerged: fine-tuning large language models (LLM) on parallel text has been shown to outperform dedicated translation systems trained in a supervised fashion on much larger amounts of parallel data (Xu et al., 2024a; Alves et al., 2024). However, it remains unclear whether this paradigm can enable massively multilingual machine translation or whether it requires fine-tuning dedicated models for a small number of language pairs. How does translation fine-tuning impact the MT capabilities of LLMs for zero-shot languages, zero-shot language pairs, and translation tasks that do not involve English? To address these questions, we conduct an extensive empirical evaluation of the translation quality of the TOWER family of language models (Alves et al., 2024) on 132 translation tasks from the multi-parallel FLORES-200 data. We find that translation fine-tuning improves translation quality even for zero-shot languages on average, but that the impact is uneven depending on the language pairs involved. These results call for further research to effectively enable massively multilingual translation with LLMs.
6/3/2024
The Fine-Tuning Paradox: Boosting Translation Quality Without Sacrificing LLM Abilities
David Stap, Eva Hasler, Bill Byrne, Christof Monz, Ke Tran
0
0
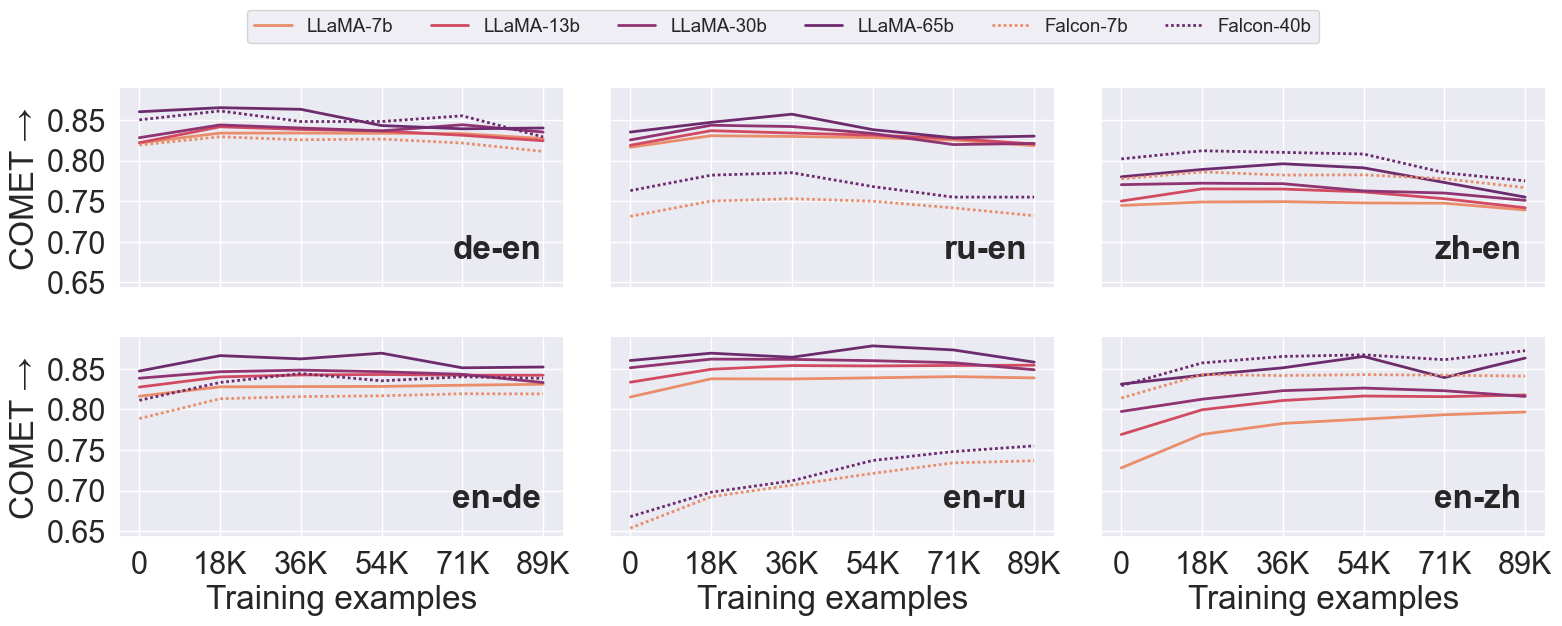
Fine-tuning large language models (LLMs) for machine translation has shown improvements in overall translation quality. However, it is unclear what is the impact of fine-tuning on desirable LLM behaviors that are not present in neural machine translation models, such as steerability, inherent document-level translation abilities, and the ability to produce less literal translations. We perform an extensive translation evaluation on the LLaMA and Falcon family of models with model size ranging from 7 billion up to 65 billion parameters. Our results show that while fine-tuning improves the general translation quality of LLMs, several abilities degrade. In particular, we observe a decline in the ability to perform formality steering, to produce technical translations through few-shot examples, and to perform document-level translation. On the other hand, we observe that the model produces less literal translations after fine-tuning on parallel data. We show that by including monolingual data as part of the fine-tuning data we can maintain the abilities while simultaneously enhancing overall translation quality. Our findings emphasize the need for fine-tuning strategies that preserve the benefits of LLMs for machine translation.
5/31/2024
💬
Eliciting the Translation Ability of Large Language Models via Multilingual Finetuning with Translation Instructions
Jiahuan Li, Hao Zhou, Shujian Huang, Shanbo Cheng, Jiajun Chen
0
0
Large-scale Pretrained Language Models (LLMs), such as ChatGPT and GPT4, have shown strong abilities in multilingual translations, without being explicitly trained on parallel corpora. It is interesting how the LLMs obtain their ability to carry out translation instructions for different languages. In this paper, we present a detailed analysis by finetuning a multilingual pretrained language model, XGLM-7B, to perform multilingual translation following given instructions. Firstly, we show that multilingual LLMs have stronger translation abilities than previously demonstrated. For a certain language, the performance depends on its similarity to English and the amount of data used in the pretraining phase. Secondly, we find that LLMs' ability to carry out translation instructions relies on the understanding of translation instructions and the alignment among different languages. With multilingual finetuning, LLMs could learn to perform the translation task well even for those language pairs unseen during the instruction tuning phase.
4/16/2024
📊
Is It Good Data for Multilingual Instruction Tuning or Just Bad Multilingual Evaluation for Large Language Models?
Pinzhen Chen, Simon Yu, Zhicheng Guo, Barry Haddow
0
0
Large language models, particularly multilingual ones, are designed, claimed, and expected to cater to native speakers of varied languages. We hypothesise that the current practices of fine-tuning and evaluating these models may mismatch this intention owing to a heavy reliance on translation, which can introduce translation artefacts and defects. It remains unknown whether the nature of the instruction data has an impact on the model output; on the other hand, it remains questionable whether translated test sets can capture such nuances. Due to the often coupled practices of using translated data in both stages, such imperfections could have been overlooked. This work investigates these issues by using controlled native or translated data during instruction tuning and evaluation stages and observing model results. Experiments on eight base models and eight different benchmarks reveal that native or generation benchmarks display a notable difference between native and translated instruction data especially when model performance is high, whereas other types of test sets cannot. Finally, we demonstrate that regularization is beneficial to bridging this gap on structured but not generative tasks.
6/19/2024