Iterative Refinement Strategy for Automated Data Labeling: Facial Landmark Diagnosis in Medical Imaging

0
📊
Sign in to get full access
Overview
- This paper proposes an iterative refinement strategy for automated data labeling, focusing on the application of facial landmark diagnosis in medical imaging.
- The approach involves a continuous feedback loop between the model and human experts, where the model's predictions are iteratively refined based on expert feedback.
- The goal is to improve the accuracy and reliability of automated data labeling, which is crucial for tasks like medical image analysis.
Plain English Explanation
The paper describes a new way to automatically label medical images, specifically those that contain facial landmarks. The key idea is to have the computer model and human experts work together in an iterative process. The model makes its best guess at labeling the landmarks, then the experts review the labels and provide feedback. The model then uses this feedback to refine its labeling, and the process repeats. This back-and-forth helps the model get better and better at accurately identifying the facial landmarks, which is important for medical image analysis. Rather than relying solely on the computer or solely on human experts, this approach combines their strengths to improve unsupervised learning and create more reliable data labels.
Technical Explanation
The paper introduces an iterative refinement strategy for automated data labeling, focusing on the task of facial landmark diagnosis in medical imaging. The approach involves a continuous feedback loop between the model and human experts:
- The model makes initial predictions for the facial landmark locations in a medical image.
- Human experts review the model's predictions and provide feedback, correcting any errors.
- The model takes this feedback and refines its predictions, learning from the expert corrections.
- The refined predictions are then sent back to the experts for further review and the process repeats.
This iterative process allows the model to gradually improve its performance through interaction with the human experts. The authors demonstrate the effectiveness of their approach on a dataset of facial landmark annotations in medical images, showing that it can outperform traditional supervised learning methods.
Critical Analysis
The iterative refinement strategy proposed in this paper is a promising approach for improving automated data labeling, particularly for tasks like medical image analysis where accuracy and reliability are crucial. By leveraging the complementary strengths of machine learning models and human experts, the method can overcome some of the limitations of purely automated or purely manual labeling.
However, the authors acknowledge that the approach does require significant human effort and involvement, which may limit its scalability for very large datasets. Additionally, the paper does not explore the potential biases or inconsistencies that may arise from having multiple human experts providing feedback, which could introduce additional challenges.
Further research is needed to explore ways of minimizing human effort and ensuring the reliability and consistency of the expert feedback. The authors could also investigate ways to integrate their approach with other unsupervised or semi-supervised learning techniques to further enhance the model's performance.
Conclusion
The iterative refinement strategy proposed in this paper offers a novel way to improve automated data labeling by leveraging the complementary strengths of machine learning models and human experts. Although the approach requires significant human involvement, it has the potential to significantly enhance the accuracy and reliability of tasks like medical image analysis, which is crucial for advancing healthcare technologies and improving patient outcomes.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📊
0
Iterative Refinement Strategy for Automated Data Labeling: Facial Landmark Diagnosis in Medical Imaging
Yu-Hsi Chen
Automated data labeling techniques are crucial for accelerating the development of deep learning models, particularly in complex medical imaging applications. However, ensuring accuracy and efficiency remains challenging. This paper presents iterative refinement strategies for automated data labeling in facial landmark diagnosis to enhance accuracy and efficiency for deep learning models in medical applications, including dermatology, plastic surgery, and ophthalmology. Leveraging feedback mechanisms and advanced algorithms, our approach iteratively refines initial labels, reducing reliance on manual intervention while improving label quality. Through empirical evaluation and case studies, we demonstrate the effectiveness of our proposed strategies in deep learning tasks across medical imaging domains. Our results highlight the importance of iterative refinement in automated data labeling to enhance the capabilities of deep learning systems in medical imaging applications.
Read more4/9/2024

0
Improving Facial Landmark Detection Accuracy and Efficiency with Knowledge Distillation
Zong-Wei Hong, Yu-Chen Lin
The domain of computer vision has experienced significant advancements in facial-landmark detection, becoming increasingly essential across various applications such as augmented reality, facial recognition, and emotion analysis. Unlike object detection or semantic segmentation, which focus on identifying objects and outlining boundaries, faciallandmark detection aims to precisely locate and track critical facial features. However, deploying deep learning-based facial-landmark detection models on embedded systems with limited computational resources poses challenges due to the complexity of facial features, especially in dynamic settings. Additionally, ensuring robustness across diverse ethnicities and expressions presents further obstacles. Existing datasets often lack comprehensive representation of facial nuances, particularly within populations like those in Taiwan. This paper introduces a novel approach to address these challenges through the development of a knowledge distillation method. By transferring knowledge from larger models to smaller ones, we aim to create lightweight yet powerful deep learning models tailored specifically for facial-landmark detection tasks. Our goal is to design models capable of accurately locating facial landmarks under varying conditions, including diverse expressions, orientations, and lighting environments. The ultimate objective is to achieve high accuracy and real-time performance suitable for deployment on embedded systems. This method was successfully implemented and achieved a top 6th place finish out of 165 participants in the IEEE ICME 2024 PAIR competition.
Read more4/10/2024

0
FaceLift: Semi-supervised 3D Facial Landmark Localization
David Ferman, Pablo Garrido, Gaurav Bharaj
3D facial landmark localization has proven to be of particular use for applications, such as face tracking, 3D face modeling, and image-based 3D face reconstruction. In the supervised learning case, such methods usually rely on 3D landmark datasets derived from 3DMM-based registration that often lack spatial definition alignment, as compared with that chosen by hand-labeled human consensus, e.g., how are eyebrow landmarks defined? This creates a gap between landmark datasets generated via high-quality 2D human labels and 3DMMs, and it ultimately limits their effectiveness. To address this issue, we introduce a novel semi-supervised learning approach that learns 3D landmarks by directly lifting (visible) hand-labeled 2D landmarks and ensures better definition alignment, without the need for 3D landmark datasets. To lift 2D landmarks to 3D, we leverage 3D-aware GANs for better multi-view consistency learning and in-the-wild multi-frame videos for robust cross-generalization. Empirical experiments demonstrate that our method not only achieves better definition alignment between 2D-3D landmarks but also outperforms other supervised learning 3D landmark localization methods on both 3DMM labeled and photogrammetric ground truth evaluation datasets. Project Page: https://davidcferman.github.io/FaceLift
Read more5/31/2024
0
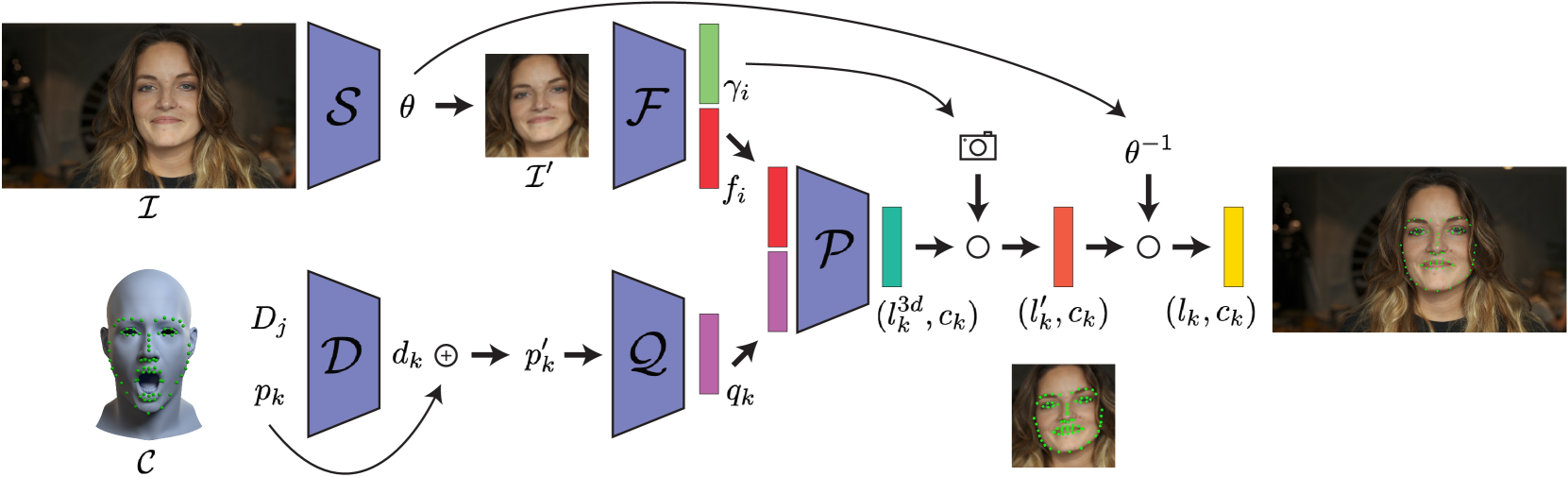
Infinite 3D Landmarks: Improving Continuous 2D Facial Landmark Detection
Prashanth Chandran, Gaspard Zoss, Paulo Gotardo, Derek Bradley
In this paper, we examine 3 important issues in the practical use of state-of-the-art facial landmark detectors and show how a combination of specific architectural modifications can directly improve their accuracy and temporal stability. First, many facial landmark detectors require face normalization as a preprocessing step, which is accomplished by a separately-trained neural network that crops and resizes the face in the input image. There is no guarantee that this pre-trained network performs the optimal face normalization for landmark detection. We instead analyze the use of a spatial transformer network that is trained alongside the landmark detector in an unsupervised manner, and jointly learn optimal face normalization and landmark detection. Second, we show that modifying the output head of the landmark predictor to infer landmarks in a canonical 3D space can further improve accuracy. To convert the predicted 3D landmarks into screen-space, we additionally predict the camera intrinsics and head pose from the input image. As a side benefit, this allows to predict the 3D face shape from a given image only using 2D landmarks as supervision, which is useful in determining landmark visibility among other things. Finally, when training a landmark detector on multiple datasets at the same time, annotation inconsistencies across datasets forces the network to produce a suboptimal average. We propose to add a semantic correction network to address this issue. This additional lightweight neural network is trained alongside the landmark detector, without requiring any additional supervision. While the insights of this paper can be applied to most common landmark detectors, we specifically target a recently-proposed continuous 2D landmark detector to demonstrate how each of our additions leads to meaningful improvements over the state-of-the-art on standard benchmarks.
Read more5/31/2024