iText2KG: Incremental Knowledge Graphs Construction Using Large Language Models

0

Sign in to get full access
Overview
- Describes a method called iText2KG for incremental construction of knowledge graphs using large language models
- Aims to extract relevant entities and relationships from text and continuously expand a knowledge graph
- Tested on real-world datasets and compared to existing methods
Plain English Explanation
The paper introduces a new technique called iText2KG that can be used to gradually build a knowledge graph from text data. A knowledge graph is a way of organizing information about the world, with entities (like people, places, or concepts) and the relationships between them.
The key idea behind iText2KG is to leverage the capabilities of large language models - powerful AI systems that can understand and generate human language. These models are used to analyze text, identify relevant entities and the connections between them, and then incrementally add this information to the knowledge graph.
This incremental approach is useful because it allows the knowledge graph to grow and evolve over time, rather than trying to construct the entire graph at once. As more text data is processed, the graph can be continuously expanded and refined.
The researchers tested iText2KG on real-world datasets and found that it outperformed existing methods for knowledge graph construction. This suggests that the approach could be a valuable tool for applications that require building and maintaining up-to-date knowledge bases from textual information.
Technical Explanation
The paper presents a new technique called iText2KG for the automated construction of knowledge graphs from text data using large language models. The approach works by incrementally adding entities and relationships to the knowledge graph as new text is processed.
The key components of iText2KG are:
- Entity Extraction: A large language model is used to identify relevant entities (e.g. people, places, concepts) mentioned in the input text.
- Relation Extraction: The language model also determines the relationships between the extracted entities.
- Knowledge Graph Construction: The identified entities and relationships are then added to the knowledge graph, either by creating new nodes and edges or updating existing ones.
This incremental process allows the knowledge graph to grow over time as more text is processed, rather than trying to construct the entire graph at once.
The researchers evaluate iText2KG on several real-world datasets and compare its performance to existing knowledge graph construction methods. They find that iText2KG outperforms these baselines, demonstrating the potential of using large language models for this task.
Critical Analysis
The paper presents a promising approach for knowledge graph construction using large language models. The key strengths of the iText2KG method are its ability to incrementally build and update the knowledge graph, and its strong performance compared to existing techniques.
However, the paper does not address some potential limitations or areas for further research:
- The accuracy and completeness of the knowledge graph construction process may depend on the quality and coverage of the underlying text data. The method has not been evaluated on more diverse or challenging datasets.
- The paper does not provide much detail on how the large language model is fine-tuned or adapted for the knowledge graph task. Further research could explore ways to optimize the model for this specific application.
- While the incremental approach is a strength, the paper does not discuss how to handle conflicts or inconsistencies that may arise as new information is added to the knowledge graph over time.
Overall, the iText2KG method represents an interesting and potentially valuable contribution to the field of knowledge graph construction. Further research to address the limitations and explore additional applications could help strengthen the approach and its real-world impact.
Conclusion
The paper introduces iText2KG, a new technique for the incremental construction of knowledge graphs using large language models. By leveraging the language understanding capabilities of these powerful AI systems, iText2KG can continuously extract relevant entities and relationships from text data and add them to a growing knowledge graph.
The researchers demonstrate that iText2KG outperforms existing knowledge graph construction methods on real-world datasets, suggesting that the approach could be a valuable tool for applications that require building and maintaining up-to-date knowledge bases from textual information. While the paper identifies some potential areas for further research, the iText2KG method represents an important step forward in the field of automated knowledge graph construction.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
iText2KG: Incremental Knowledge Graphs Construction Using Large Language Models
Yassir Lairgi, Ludovic Moncla, R'emy Cazabet, Khalid Benabdeslem, Pierre Cl'eau
Most available data is unstructured, making it challenging to access valuable information. Automatically building Knowledge Graphs (KGs) is crucial for structuring data and making it accessible, allowing users to search for information effectively. KGs also facilitate insights, inference, and reasoning. Traditional NLP methods, such as named entity recognition and relation extraction, are key in information retrieval but face limitations, including the use of predefined entity types and the need for supervised learning. Current research leverages large language models' capabilities, such as zero- or few-shot learning. However, unresolved and semantically duplicated entities and relations still pose challenges, leading to inconsistent graphs and requiring extensive post-processing. Additionally, most approaches are topic-dependent. In this paper, we propose iText2KG, a method for incremental, topic-independent KG construction without post-processing. This plug-and-play, zero-shot method is applicable across a wide range of KG construction scenarios and comprises four modules: Document Distiller, Incremental Entity Extractor, Incremental Relation Extractor, and Graph Integrator and Visualization. Our method demonstrates superior performance compared to baseline methods across three scenarios: converting scientific papers to graphs, websites to graphs, and CVs to graphs.
Read more9/6/2024

0
Docs2KG: Unified Knowledge Graph Construction from Heterogeneous Documents Assisted by Large Language Models
Qiang Sun, Yuanyi Luo, Wenxiao Zhang, Sirui Li, Jichunyang Li, Kai Niu, Xiangrui Kong, Wei Liu
Even for a conservative estimate, 80% of enterprise data reside in unstructured files, stored in data lakes that accommodate heterogeneous formats. Classical search engines can no longer meet information seeking needs, especially when the task is to browse and explore for insight formulation. In other words, there are no obvious search keywords to use. Knowledge graphs, due to their natural visual appeals that reduce the human cognitive load, become the winning candidate for heterogeneous data integration and knowledge representation. In this paper, we introduce Docs2KG, a novel framework designed to extract multimodal information from diverse and heterogeneous unstructured documents, including emails, web pages, PDF files, and Excel files. Dynamically generates a unified knowledge graph that represents the extracted key information, Docs2KG enables efficient querying and exploration of document data lakes. Unlike existing approaches that focus on domain-specific data sources or pre-designed schemas, Docs2KG offers a flexible and extensible solution that can adapt to various document structures and content types. The proposed framework unifies data processing supporting a multitude of downstream tasks with improved domain interpretability. Docs2KG is publicly accessible at https://docs2kg.ai4wa.com, and a demonstration video is available at https://docs2kg.ai4wa.com/Video.
Read more6/6/2024
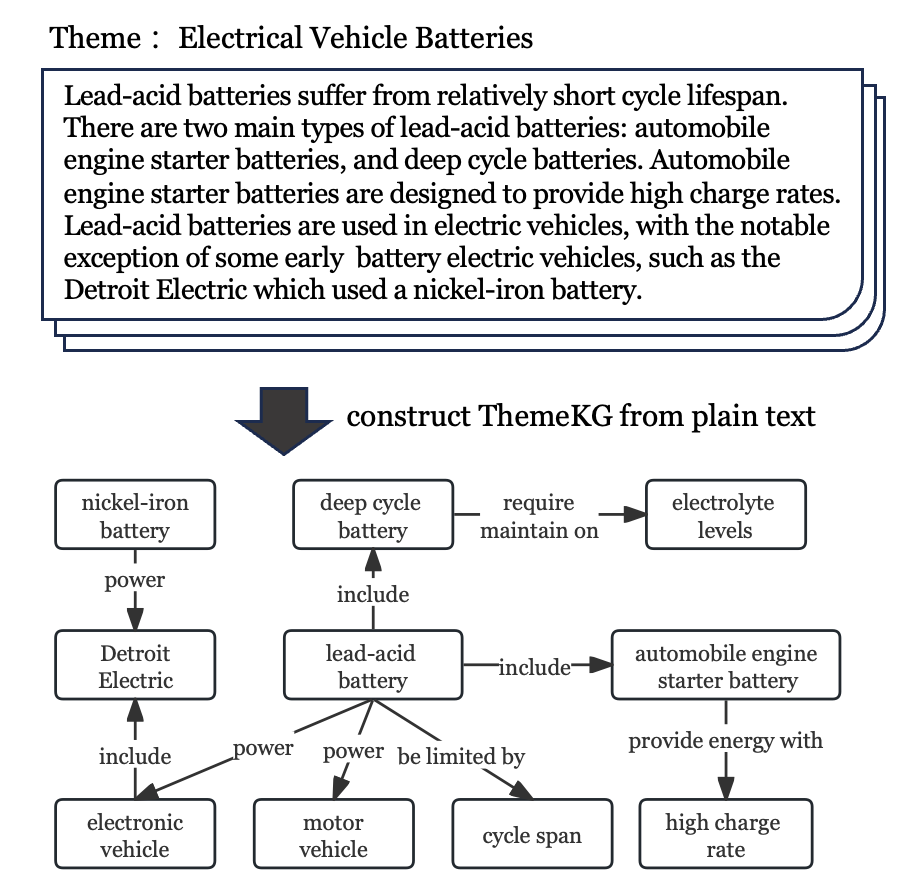
0
Automated Construction of Theme-specific Knowledge Graphs
Linyi Ding, Sizhe Zhou, Jinfeng Xiao, Jiawei Han
Despite widespread applications of knowledge graphs (KGs) in various tasks such as question answering and intelligent conversational systems, existing KGs face two major challenges: information granularity and deficiency in timeliness. These hinder considerably the retrieval and analysis of in-context, fine-grained, and up-to-date knowledge from KGs, particularly in highly specialized themes (e.g., specialized scientific research) and rapidly evolving contexts (e.g., breaking news or disaster tracking). To tackle such challenges, we propose a theme-specific knowledge graph (i.e., ThemeKG), a KG constructed from a theme-specific corpus, and design an unsupervised framework for ThemeKG construction (named TKGCon). The framework takes raw theme-specific corpus and generates a high-quality KG that includes salient entities and relations under the theme. Specifically, we start with an entity ontology of the theme from Wikipedia, based on which we then generate candidate relations by Large Language Models (LLMs) to construct a relation ontology. To parse the documents from the theme corpus, we first map the extracted entity pairs to the ontology and retrieve the candidate relations. Finally, we incorporate the context and ontology to consolidate the relations for entity pairs. We observe that directly prompting GPT-4 for theme-specific KG leads to inaccurate entities (such as two main types as one entity in the query result) and unclear (such as is, has) or wrong relations (such as have due to, to start). In contrast, by constructing the theme-specific KG step by step, our model outperforms GPT-4 and could consistently identify accurate entities and relations. Experimental results also show that our framework excels in evaluations compared with various KG construction baselines.
Read more5/1/2024
🛸
0
LLMs for Knowledge Graph Construction and Reasoning: Recent Capabilities and Future Opportunities
Yuqi Zhu, Xiaohan Wang, Jing Chen, Shuofei Qiao, Yixin Ou, Yunzhi Yao, Shumin Deng, Huajun Chen, Ningyu Zhang
This paper presents an exhaustive quantitative and qualitative evaluation of Large Language Models (LLMs) for Knowledge Graph (KG) construction and reasoning. We engage in experiments across eight diverse datasets, focusing on four representative tasks encompassing entity and relation extraction, event extraction, link prediction, and question-answering, thereby thoroughly exploring LLMs' performance in the domain of construction and inference. Empirically, our findings suggest that LLMs, represented by GPT-4, are more suited as inference assistants rather than few-shot information extractors. Specifically, while GPT-4 exhibits good performance in tasks related to KG construction, it excels further in reasoning tasks, surpassing fine-tuned models in certain cases. Moreover, our investigation extends to the potential generalization ability of LLMs for information extraction, leading to the proposition of a Virtual Knowledge Extraction task and the development of the corresponding VINE dataset. Based on these empirical findings, we further propose AutoKG, a multi-agent-based approach employing LLMs and external sources for KG construction and reasoning. We anticipate that this research can provide invaluable insights for future undertakings in the field of knowledge graphs. The code and datasets are in https://github.com/zjunlp/AutoKG.
Read more8/20/2024