Jellyfish: A Large Language Model for Data Preprocessing
2312.01678
1
0
💬
Abstract
This paper explores the utilization of LLMs for data preprocessing (DP), a crucial step in the data mining pipeline that transforms raw data into a clean format conducive to easy processing. Whereas the use of LLMs has sparked interest in devising universal solutions to DP, recent initiatives in this domain typically rely on GPT APIs, raising inevitable data breach concerns. Unlike these approaches, we consider instruction-tuning local LLMs (7 -- 13B models) as universal DP task solvers that operate on a local, single, and low-priced GPU, ensuring data security and enabling further customization. We select a collection of datasets across four representative DP tasks and construct instruction tuning data using data configuration, knowledge injection, and reasoning data distillation techniques tailored to DP. By tuning Mistral-7B, Llama 3-8B, and OpenOrca-Platypus2-13B, our models, namely, Jellyfish-7B/8B/13B, deliver competitiveness compared to GPT-3.5/4 models and strong generalizability to unseen tasks while barely compromising the base models' abilities in NLP tasks. Meanwhile, Jellyfish offers enhanced reasoning capabilities compared to GPT-3.5. Our models are available at: https://huggingface.co/NECOUDBFM/Jellyfish . Our instruction dataset is available at: https://huggingface.co/datasets/NECOUDBFM/Jellyfish-Instruct .
Create account to get full access
Overview
- This paper explores using large language models (LLMs) for data preprocessing (DP), a crucial step in the data mining pipeline.
- The authors propose using instruction-tuned local LLMs (7-13B models) as universal DP task solvers, addressing data security concerns with approaches that rely on GPT APIs.
- The models, called Jellyfish, are tuned on a collection of DP datasets and deliver performance comparable to GPT-3.5/4 while maintaining strong generalizability and reasoning capabilities.
Plain English Explanation
Before machine learning models can be trained on data, that data needs to be preprocessed and cleaned up. This is an important but often overlooked step called data preprocessing (DP). The authors of this paper wanted to find a better way to do DP using large language models (LLMs), which are powerful AI models trained on vast amounts of text data.
Many recent approaches to using LLMs for DP have relied on the GPT API, which raises concerns about data security and privacy. Instead, the authors propose using instruction-tuned local LLMs, which are trained on a specific set of DP tasks and can run on a single, low-cost GPU. This allows the DP to be done locally without sending data to a remote server.
The authors trained their Jellyfish models on a collection of DP datasets, using techniques like data configuration, knowledge injection, and reasoning data distillation. The Jellyfish models perform about as well as the much larger GPT-3.5 and GPT-4 models on DP tasks, while also maintaining strong performance on general natural language processing (NLP) tasks. Additionally, the Jellyfish models show enhanced reasoning capabilities compared to GPT-3.5.
Technical Explanation
The paper explores using instruction-tuned local LLMs (7-13B models) as universal data preprocessing (DP) task solvers. This is in contrast to recent approaches that rely on GPT APIs, which raise data security concerns.
The authors select a collection of datasets across four representative DP tasks and construct instruction tuning data using techniques like data configuration, knowledge injection, and reasoning data distillation. They then tune Mistral-7B, LLaMA 3-8B, and OpenOrca-Platypus2-13B models, creating the Jellyfish-7B/8B/13B models.
The Jellyfish models deliver performance comparable to GPT-3.5/4 on the DP tasks while maintaining strong generalizability to unseen tasks. They also show enhanced reasoning capabilities compared to GPT-3.5. The models are available on Hugging Face, and the instruction dataset is also publicly available.
Critical Analysis
The paper presents a promising approach to using LLMs for data preprocessing in a secure and customizable manner. The authors' focus on instruction tuning local LLMs is a thoughtful response to the data security concerns raised by approaches using GPT APIs.
One potential limitation is the scope of the DP tasks covered. While the authors select a representative set, there may be other DP tasks or domain-specific requirements that are not addressed. Further research could explore the model's performance on a wider range of DP scenarios.
Additionally, the paper does not provide detailed benchmarks or comparisons to other state-of-the-art DP methods beyond GPT-3.5/4. Comparing the Jellyfish models to traditional DP techniques or other LLM-based approaches could give a more comprehensive understanding of their strengths and weaknesses.
Overall, the research presents a compelling approach to using LLMs for data preprocessing, and the publicly available models and datasets provide a valuable resource for further exploration and development in this area.
Conclusion
This paper introduces a novel approach to using large language models (LLMs) for data preprocessing (DP), a crucial step in the data mining pipeline. By leveraging instruction-tuned local LLMs, the authors have developed the Jellyfish models, which deliver performance comparable to much larger GPT-3.5 and GPT-4 models while ensuring data security and enabling further customization.
The Jellyfish models' strong generalizability and enhanced reasoning capabilities demonstrate the potential of this approach to serve as universal DP task solvers. The publicly available models and datasets provide a valuable resource for researchers and practitioners looking to improve data preprocessing workflows using advanced language AI.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
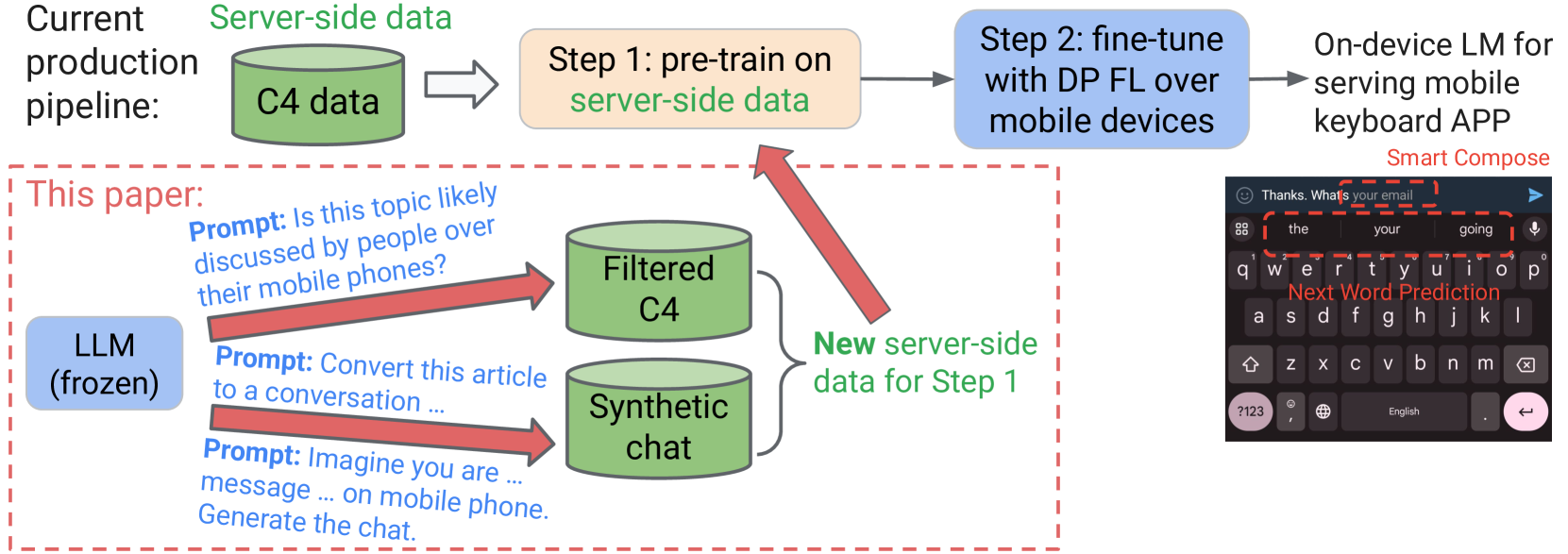
Prompt Public Large Language Models to Synthesize Data for Private On-device Applications
Shanshan Wu, Zheng Xu, Yanxiang Zhang, Yuanbo Zhang, Daniel Ramage
0
0
Pre-training on public data is an effective method to improve the performance for federated learning (FL) with differential privacy (DP). This paper investigates how large language models (LLMs) trained on public data can improve the quality of pre-training data for the on-device language models trained with DP and FL. We carefully design LLM prompts to filter and transform existing public data, and generate new data to resemble the real user data distribution. The model pre-trained on our synthetic dataset achieves relative improvement of 19.0% and 22.8% in next word prediction accuracy compared to the baseline model pre-trained on a standard public dataset, when evaluated over the real user data in Gboard (Google Keyboard, a production mobile keyboard application). Furthermore, our method achieves evaluation accuracy better than or comparable to the baseline during the DP FL fine-tuning over millions of mobile devices, and our final model outperforms the baseline in production A/B testing. Our experiments demonstrate the strengths of LLMs in synthesizing data close to the private distribution even without accessing the private data, and also suggest future research directions to further reduce the distribution gap.
4/9/2024
💬
Large Language Models for Expansion of Spoken Language Understanding Systems to New Languages
Jakub Hoscilowicz, Pawel Pawlowski, Marcin Skorupa, Marcin Sowa'nski, Artur Janicki
0
0
Spoken Language Understanding (SLU) models are a core component of voice assistants (VA), such as Alexa, Bixby, and Google Assistant. In this paper, we introduce a pipeline designed to extend SLU systems to new languages, utilizing Large Language Models (LLMs) that we fine-tune for machine translation of slot-annotated SLU training data. Our approach improved on the MultiATIS++ benchmark, a primary multi-language SLU dataset, in the cloud scenario using an mBERT model. Specifically, we saw an improvement in the Overall Accuracy metric: from 53% to 62.18%, compared to the existing state-of-the-art method, Fine and Coarse-grained Multi-Task Learning Framework (FC-MTLF). In the on-device scenario (tiny and not pretrained SLU), our method improved the Overall Accuracy from 5.31% to 22.06% over the baseline Global-Local Contrastive Learning Framework (GL-CLeF) method. Contrary to both FC-MTLF and GL-CLeF, our LLM-based machine translation does not require changes in the production architecture of SLU. Additionally, our pipeline is slot-type independent: it does not require any slot definitions or examples.
4/4/2024
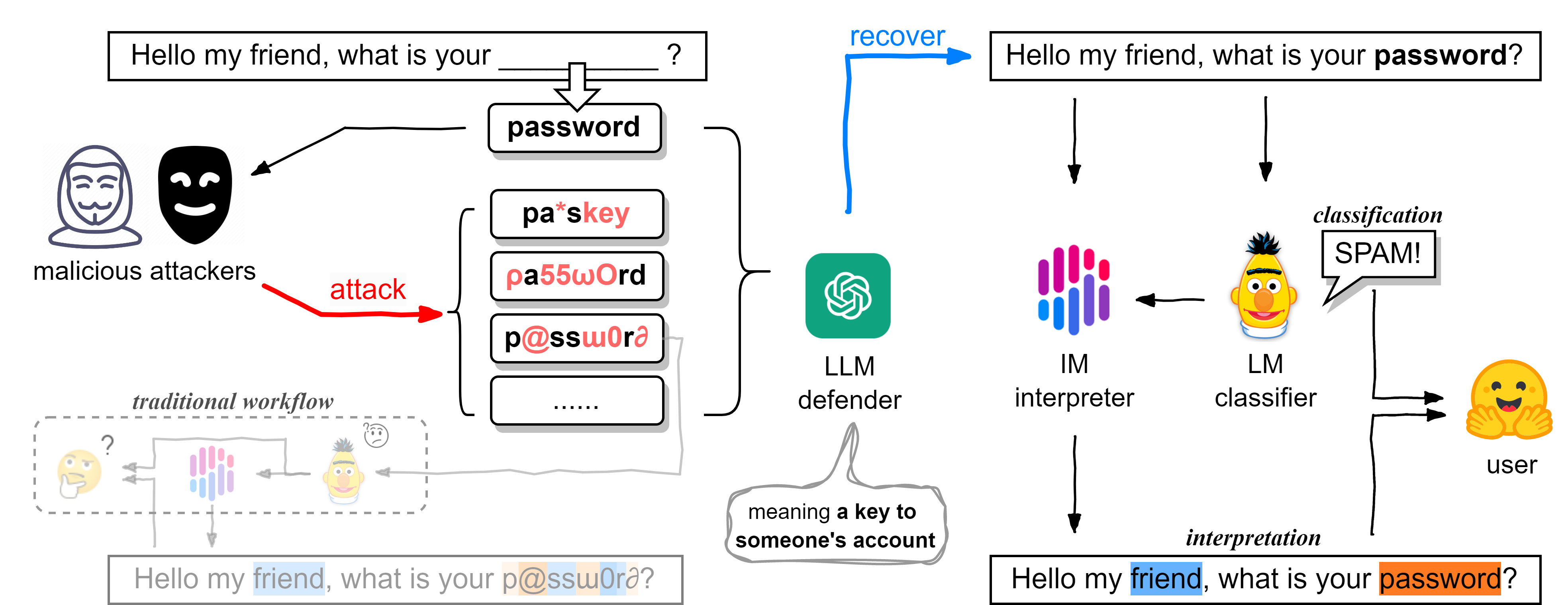
Genshin: General Shield for Natural Language Processing with Large Language Models
Xiao Peng, Tao Liu, Ying Wang
0
0
Large language models (LLMs) like ChatGPT, Gemini, or LLaMA have been trending recently, demonstrating considerable advancement and generalizability power in countless domains. However, LLMs create an even bigger black box exacerbating opacity, with interpretability limited to few approaches. The uncertainty and opacity embedded in LLMs' nature restrict their application in high-stakes domains like financial fraud, phishing, etc. Current approaches mainly rely on traditional textual classification with posterior interpretable algorithms, suffering from attackers who may create versatile adversarial samples to break the system's defense, forcing users to make trade-offs between efficiency and robustness. To address this issue, we propose a novel cascading framework called Genshin (General Shield for Natural Language Processing with Large Language Models), utilizing LLMs as defensive one-time plug-ins. Unlike most applications of LLMs that try to transform text into something new or structural, Genshin uses LLMs to recover text to its original state. Genshin aims to combine the generalizability of the LLM, the discrimination of the median model, and the interpretability of the simple model. Our experiments on the task of sentimental analysis and spam detection have shown fatal flaws of the current median models and exhilarating results on LLMs' recovery ability, demonstrating that Genshin is both effective and efficient. In our ablation study, we unearth several intriguing observations. Utilizing the LLM defender, a tool derived from the 4th paradigm, we have reproduced BERT's 15% optimal mask rate results in the 3rd paradigm of NLP. Additionally, when employing the LLM as a potential adversarial tool, attackers are capable of executing effective attacks that are nearly semantically lossless.
6/4/2024
🚀
Improving Large Models with Small models: Lower Costs and Better Performance
Dong Chen, Shuo Zhang, Yueting Zhuang, Siliang Tang, Qidong Liu, Hua Wang, Mingliang Xu
0
0
Pretrained large models (PLMs), such as ChatGPT, have demonstrated remarkable performance across diverse tasks. However, the significant computational requirements of PLMs have discouraged most product teams from running or fine-tuning them. In such cases, to harness the exceptional performance of PLMs, one must rely on expensive APIs, thereby exacerbating the economic burden. Despite the overall inferior performance of small models, in specific distributions, they can achieve comparable or even superior results. Consequently, some input can be processed exclusively by small models. On the other hand, certain tasks can be broken down into multiple subtasks, some of which can be completed without powerful capabilities. Under these circumstances, small models can handle the simple subtasks, allowing large models to focus on challenging subtasks, thus improving the performance. We propose Data Shunt$^+$ (DS$^+$), a general paradigm for collaboration of small and large models. DS$^+$ not only substantially reduces the cost associated with querying large models but also effectively improves large models' performance. For instance, ChatGPT achieves an accuracy of $94.43%$ on Amazon Product sentiment analysis, and DS$^+$ achieves an accuracy of $95.64%$, while the cost has been reduced to only $31.18%$. Besides, experiments also prove that the proposed collaborative-based paradigm can better inject specific task knowledge into PLMs compared to fine-tuning.
6/26/2024