Using Large Language Models to Enrich the Documentation of Datasets for Machine Learning
2404.15320
0
0
Abstract
Recent regulatory initiatives like the European AI Act and relevant voices in the Machine Learning (ML) community stress the need to describe datasets along several key dimensions for trustworthy AI, such as the provenance processes and social concerns. However, this information is typically presented as unstructured text in accompanying documentation, hampering their automated analysis and processing. In this work, we explore using large language models (LLM) and a set of prompting strategies to automatically extract these dimensions from documents and enrich the dataset description with them. Our approach could aid data publishers and practitioners in creating machine-readable documentation to improve the discoverability of their datasets, assess their compliance with current AI regulations, and improve the overall quality of ML models trained on them. In this paper, we evaluate the approach on 12 scientific dataset papers published in two scientific journals (Nature's Scientific Data and Elsevier's Data in Brief) using two different LLMs (GPT3.5 and Flan-UL2). Results show good accuracy with our prompt extraction strategies. Concrete results vary depending on the dimensions, but overall, GPT3.5 shows slightly better accuracy (81,21%) than FLAN-UL2 (69,13%) although it is more prone to hallucinations. We have released an open-source tool implementing our approach and a replication package, including the experiments' code and results, in an open-source repository.
Create account to get full access
Overview
- The paper discusses how large language models (LLMs) can be used to enrich the documentation of datasets for machine learning (ML)
- It explores ways to leverage the capabilities of LLMs to improve the quality and completeness of dataset documentation
- The authors propose several techniques for using LLMs to generate relevant metadata, descriptions, and other information to enhance dataset documentation
Plain English Explanation
Datasets are a crucial component of machine learning (ML) systems, as they provide the data used to train and evaluate these models. However, dataset documentation is often incomplete or lacking in key details, which can make it difficult for researchers and developers to understand and effectively use the data.
This paper explores how large language models (LLMs) - powerful AI systems trained on vast amounts of text data - can be leveraged to enrich the documentation of datasets. LLMs have the ability to understand and generate human-like text, which the authors propose can be used to automatically generate relevant metadata, descriptions, and other information to enhance dataset documentation.
For example, an LLM could be used to generate sample text that illustrates the content and structure of a dataset, or to extract key facts and insights from the dataset and summarize them in the documentation. The authors also discuss how LLMs could be fine-tuned or prompted to tailor the generated content to the specific needs and requirements of dataset users.
By using LLMs to enhance dataset documentation, the authors believe that researchers and developers will be better equipped to understand and effectively utilize the data, leading to more robust and reliable ML systems.
Technical Explanation
The paper begins by outlining the importance of comprehensive dataset documentation in the field of machine learning. The authors note that while dataset quality and diversity are crucial for training effective ML models, the documentation accompanying these datasets is often incomplete or lacking in key details.
To address this issue, the authors propose leveraging the capabilities of large language models (LLMs) to enrich dataset documentation. LLMs are AI systems that have been trained on vast amounts of textual data, giving them the ability to understand and generate human-like language. The authors explore several ways in which LLMs can be utilized to enhance dataset documentation:
-
Metadata Generation: LLMs can be used to automatically generate relevant metadata, such as dataset descriptions, keywords, and classifications, based on the content of the dataset.
-
Sample Text Generation: LLMs can be used to generate sample text that illustrates the content and structure of a dataset, helping users understand the data more effectively.
-
Insight Extraction: LLMs can be used to extract key facts and insights from the dataset and summarize them in the documentation, providing users with a concise overview of the data.
-
Personalized Documentation: The authors discuss how LLMs could be fine-tuned or prompted to tailor the generated content to the specific needs and requirements of individual dataset users, enhancing the relevance and usefulness of the documentation.
The paper also outlines several potential challenges and limitations of using LLMs for dataset documentation enrichment, such as the risk of bias or inaccuracies in the generated content, and the need for careful prompt engineering and model fine-tuning to ensure the generated information is reliable and relevant.
Critical Analysis
The authors make a compelling case for using LLMs to enhance dataset documentation, as this could significantly improve the usability and transparency of ML datasets. By generating relevant metadata, sample text, and insights, LLMs could help researchers and developers better understand and effectively utilize the data, leading to more robust and reliable ML systems.
However, the authors also acknowledge several potential limitations and challenges that would need to be addressed. For example, there is a risk that the generated content could be biased or inaccurate, which could lead to misleading or incorrect information being included in the dataset documentation. To mitigate this, the authors suggest the need for careful prompt engineering and model fine-tuning to ensure the generated content is reliable and relevant.
Additionally, the authors do not provide a comprehensive evaluation of the proposed techniques, which makes it difficult to assess the actual effectiveness and potential impact of using LLMs for dataset documentation enrichment. Further research would be needed to validate the authors' claims and explore the real-world implications of this approach.
Overall, the paper presents an interesting and potentially valuable idea for leveraging the capabilities of LLMs to improve dataset documentation. However, more work is needed to address the identified limitations and further explore the practical applications and implications of this approach.
Conclusion
This paper explores the use of large language models (LLMs) to enrich the documentation of datasets for machine learning (ML). The authors propose several techniques for using LLMs to generate relevant metadata, sample text, and insights that can be incorporated into dataset documentation, with the goal of improving the usability and transparency of ML datasets.
While the authors make a compelling case for this approach, they also acknowledge several potential limitations and challenges that would need to be addressed, such as the risk of bias or inaccuracies in the generated content. Further research and real-world evaluation would be needed to fully assess the effectiveness and practical implications of using LLMs for dataset documentation enrichment.
Overall, the paper presents an interesting and potentially valuable idea for leveraging the capabilities of LLMs to enhance the quality and completeness of dataset documentation, which could have significant implications for the development of more robust and reliable ML systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Use of a Structured Knowledge Base Enhances Metadata Curation by Large Language Models
Sowmya S. Sundaram, Benjamin Solomon, Avani Khatri, Anisha Laumas, Purvesh Khatri, Mark A. Musen
0
0
Metadata play a crucial role in ensuring the findability, accessibility, interoperability, and reusability of datasets. This paper investigates the potential of large language models (LLMs), specifically GPT-4, to improve adherence to metadata standards. We conducted experiments on 200 random data records describing human samples relating to lung cancer from the NCBI BioSample repository, evaluating GPT-4's ability to suggest edits for adherence to metadata standards. We computed the adherence accuracy of field name-field value pairs through a peer review process, and we observed a marginal average improvement in adherence to the standard data dictionary from 79% to 80% (p<0.01). We then prompted GPT-4 with domain information in the form of the textual descriptions of CEDAR templates and recorded a significant improvement to 97% from 79% (p<0.01). These results indicate that, while LLMs may not be able to correct legacy metadata to ensure satisfactory adherence to standards when unaided, they do show promise for use in automated metadata curation when integrated with a structured knowledge base.
4/10/2024

Large Language Models: A New Approach for Privacy Policy Analysis at Scale
David Rodriguez, Ian Yang, Jose M. Del Alamo, Norman Sadeh
0
0
The number and dynamic nature of web and mobile applications presents significant challenges for assessing their compliance with data protection laws. In this context, symbolic and statistical Natural Language Processing (NLP) techniques have been employed for the automated analysis of these systems' privacy policies. However, these techniques typically require labor-intensive and potentially error-prone manually annotated datasets for training and validation. This research proposes the application of Large Language Models (LLMs) as an alternative for effectively and efficiently extracting privacy practices from privacy policies at scale. Particularly, we leverage well-known LLMs such as ChatGPT and Llama 2, and offer guidance on the optimal design of prompts, parameters, and models, incorporating advanced strategies such as few-shot learning. We further illustrate its capability to detect detailed and varied privacy practices accurately. Using several renowned datasets in the domain as a benchmark, our evaluation validates its exceptional performance, achieving an F1 score exceeding 93%. Besides, it does so with reduced costs, faster processing times, and fewer technical knowledge requirements. Consequently, we advocate for LLM-based solutions as a sound alternative to traditional NLP techniques for the automated analysis of privacy policies at scale.
6/3/2024
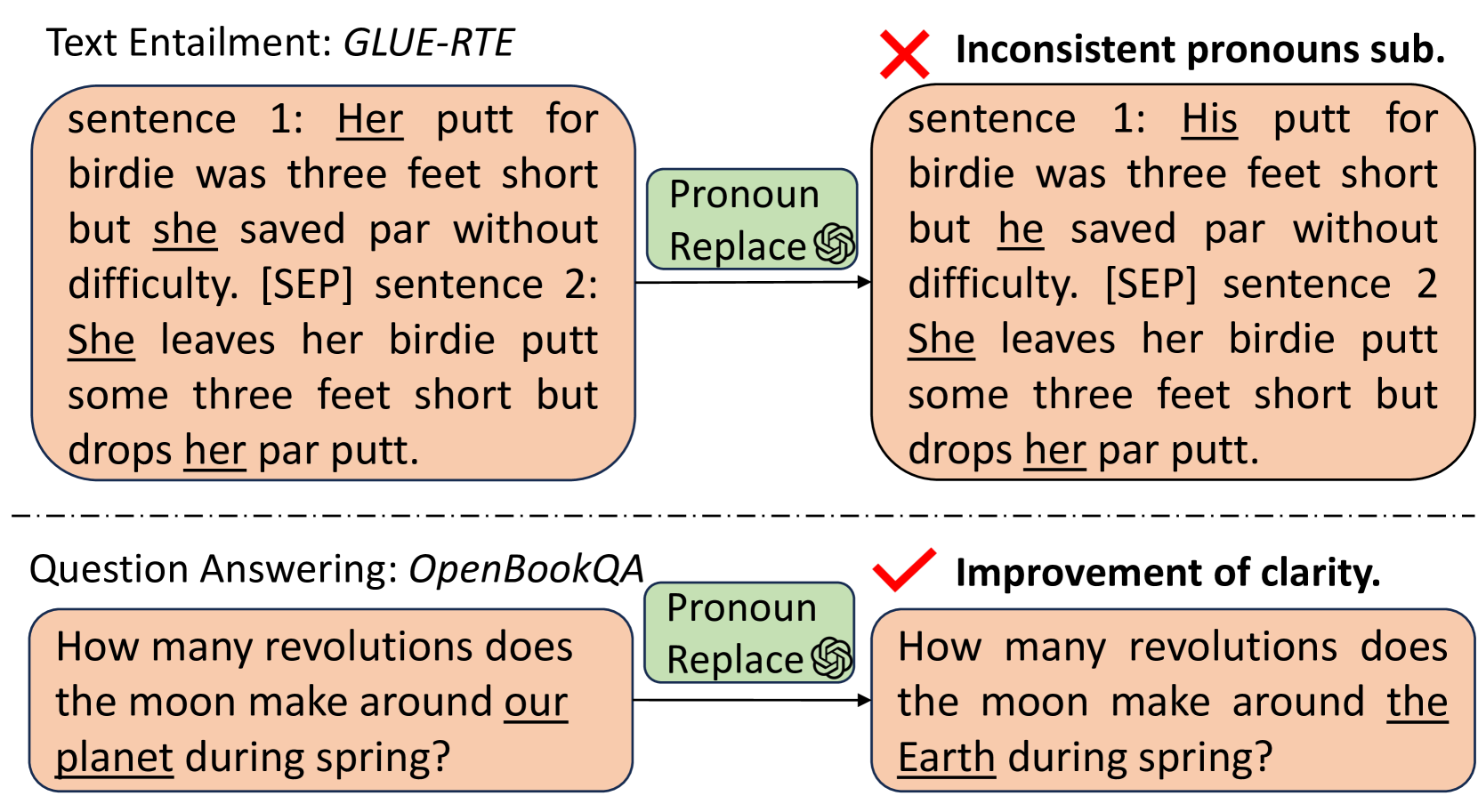
Empowering Large Language Models for Textual Data Augmentation
Yichuan Li, Kaize Ding, Jianling Wang, Kyumin Lee
0
0
With the capabilities of understanding and executing natural language instructions, Large language models (LLMs) can potentially act as a powerful tool for textual data augmentation. However, the quality of augmented data depends heavily on the augmentation instructions provided, and the effectiveness can fluctuate across different downstream tasks. While manually crafting and selecting instructions can offer some improvement, this approach faces scalability and consistency issues in practice due to the diversity of downstream tasks. In this work, we address these limitations by proposing a new solution, which can automatically generate a large pool of augmentation instructions and select the most suitable task-informed instructions, thereby empowering LLMs to create high-quality augmented data for different downstream tasks. Empirically, the proposed approach consistently generates augmented data with better quality compared to non-LLM and LLM-based data augmentation methods, leading to the best performance on 26 few-shot learning tasks sourced from a wide range of application domains.
4/30/2024
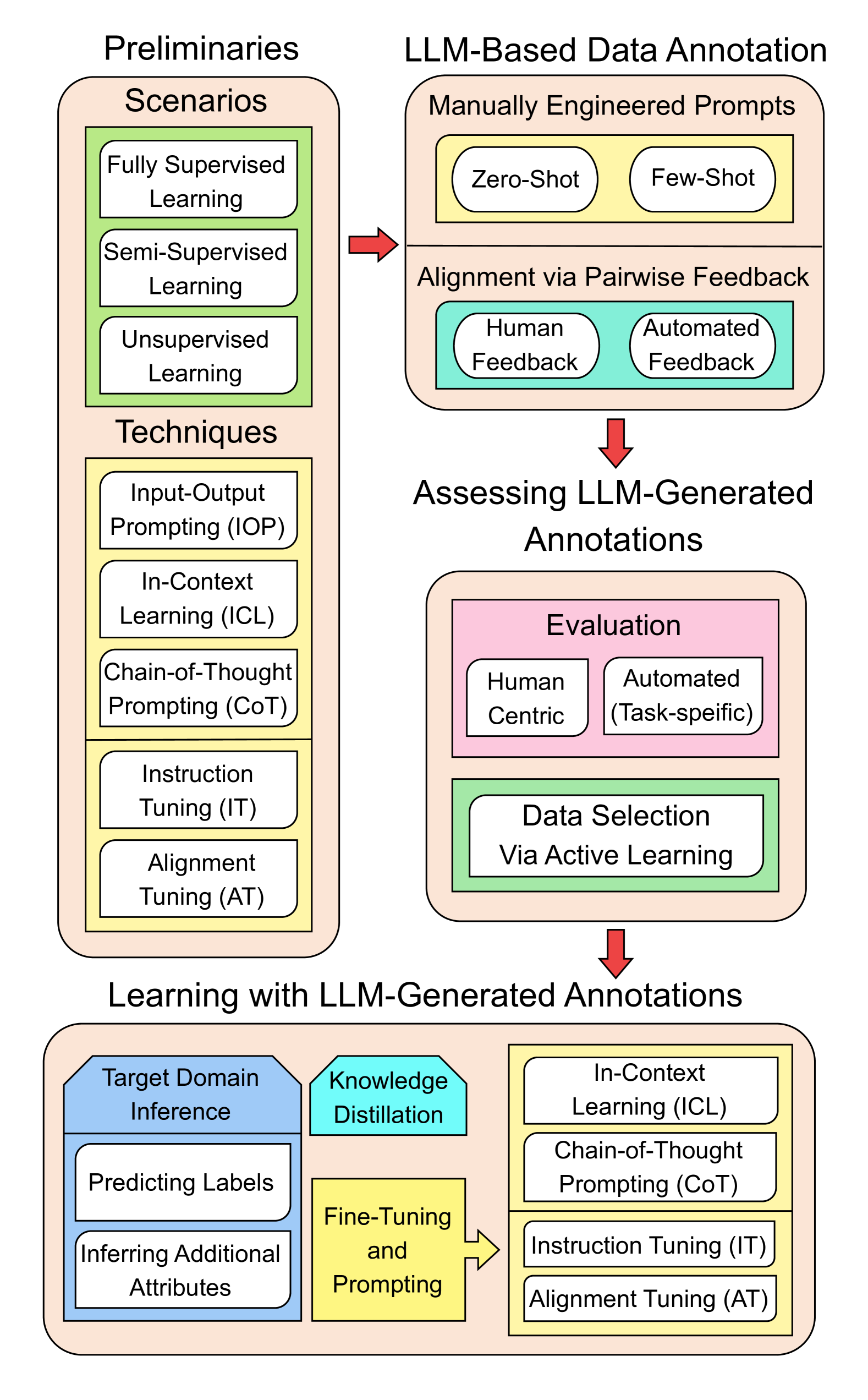
Large Language Models for Data Annotation: A Survey
Zhen Tan, Dawei Li, Song Wang, Alimohammad Beigi, Bohan Jiang, Amrita Bhattacharjee, Mansooreh Karami, Jundong Li, Lu Cheng, Huan Liu
0
0
Data annotation generally refers to the labeling or generating of raw data with relevant information, which could be used for improving the efficacy of machine learning models. The process, however, is labor-intensive and costly. The emergence of advanced Large Language Models (LLMs), exemplified by GPT-4, presents an unprecedented opportunity to automate the complicated process of data annotation. While existing surveys have extensively covered LLM architecture, training, and general applications, we uniquely focus on their specific utility for data annotation. This survey contributes to three core aspects: LLM-Based Annotation Generation, LLM-Generated Annotations Assessment, and LLM-Generated Annotations Utilization. Furthermore, this survey includes an in-depth taxonomy of data types that LLMs can annotate, a comprehensive review of learning strategies for models utilizing LLM-generated annotations, and a detailed discussion of the primary challenges and limitations associated with using LLMs for data annotation. Serving as a key guide, this survey aims to assist researchers and practitioners in exploring the potential of the latest LLMs for data annotation, thereby fostering future advancements in this critical field.
6/26/2024