Joint Demonstration and Preference Learning Improves Policy Alignment with Human Feedback
2406.06874
0
0
Abstract
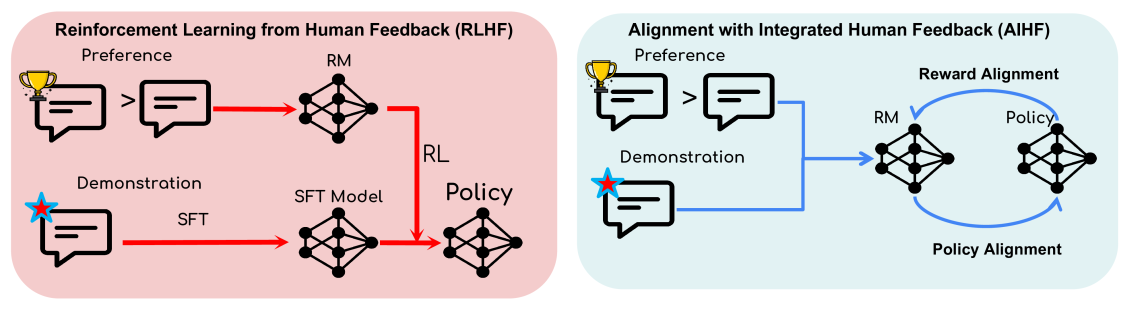
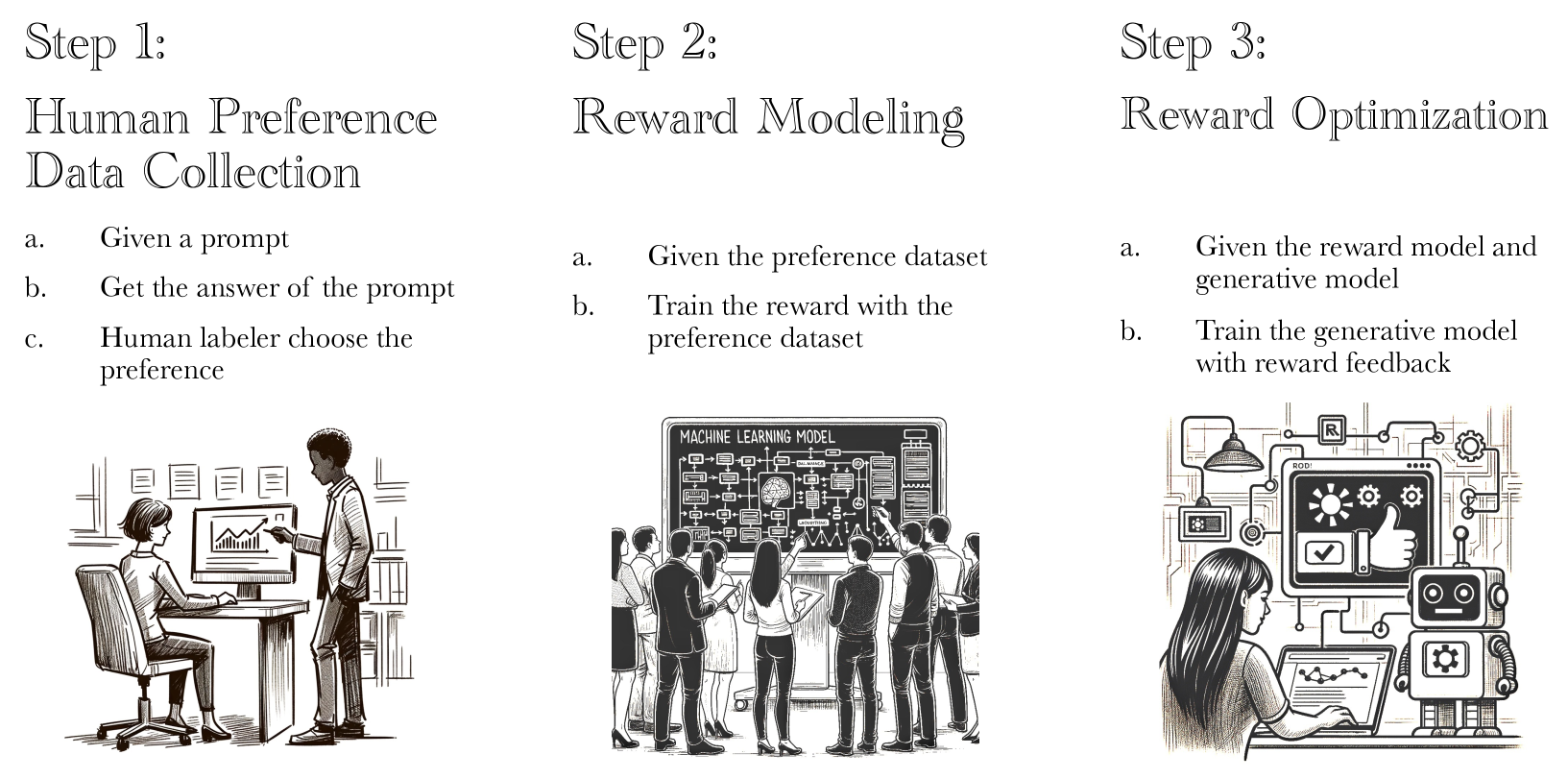
Aligning human preference and value is an important requirement for building contemporary foundation models and embodied AI. However, popular approaches such as reinforcement learning with human feedback (RLHF) break down the task into successive stages, such as supervised fine-tuning (SFT), reward modeling (RM), and reinforcement learning (RL), each performing one specific learning task. Such a sequential approach results in serious issues such as significant under-utilization of data and distribution mismatch between the learned reward model and generated policy, which eventually lead to poor alignment performance. We develop a single stage approach named Alignment with Integrated Human Feedback (AIHF), capable of integrating both human preference and demonstration to train reward models and the policy. The proposed approach admits a suite of efficient algorithms, which can easily reduce to, and leverage, popular alignment algorithms such as RLHF and Directly Policy Optimization (DPO), and only requires minor changes to the existing alignment pipelines. We demonstrate the efficiency of the proposed solutions with extensive experiments involving alignment problems in LLMs and robotic control problems in MuJoCo. We observe that the proposed solutions outperform the existing alignment algorithms such as RLHF and DPO by large margins, especially when the amount of high-quality preference data is relatively limited.
Create account to get full access
Overview
- This paper explores a method for improving the alignment of AI systems with human feedback by jointly learning from both demonstrations and preferences.
- The researchers propose a novel approach that combines demonstration learning and preference learning to better capture human values and intentions.
- The method is evaluated on several benchmarks, demonstrating significant improvements in policy alignment compared to existing techniques.
Plain English Explanation
The paper introduces a new way to train AI systems to behave in a way that is more aligned with human values and preferences. Current approaches often rely on either having the AI observe and learn from human demonstrations, or on the AI receiving feedback from humans about which actions they prefer.
The researchers found that combining these two techniques - learning from both demonstrations and preferences - resulted in AI systems that better captured the full scope of human intentions. By seeing examples of good behavior and also receiving feedback on the relative desirability of different actions, the AI was able to learn a more nuanced and reliable model of what humans want.
This joint approach was tested on a variety of benchmark tasks, and the AI systems trained this way consistently outperformed those trained using only demonstrations or only preferences. The key insight is that the combination of these two learning signals allows the AI to build a richer and more accurate understanding of human values.
Technical Explanation
The paper proposes a joint demonstration and preference learning framework for improving policy alignment with human feedback. The method combines two complementary approaches:
- Demonstration learning: The AI observes and learns from examples of good behavior demonstrated by humans.
- Preference learning: The AI receives feedback from humans about which actions they prefer, allowing it to learn a reward function that captures human values.
The key innovation is a novel linear alignment formulation that enables the seamless integration of these two learning signals. This allows the AI to build a more comprehensive understanding of human intentions compared to using only one signal.
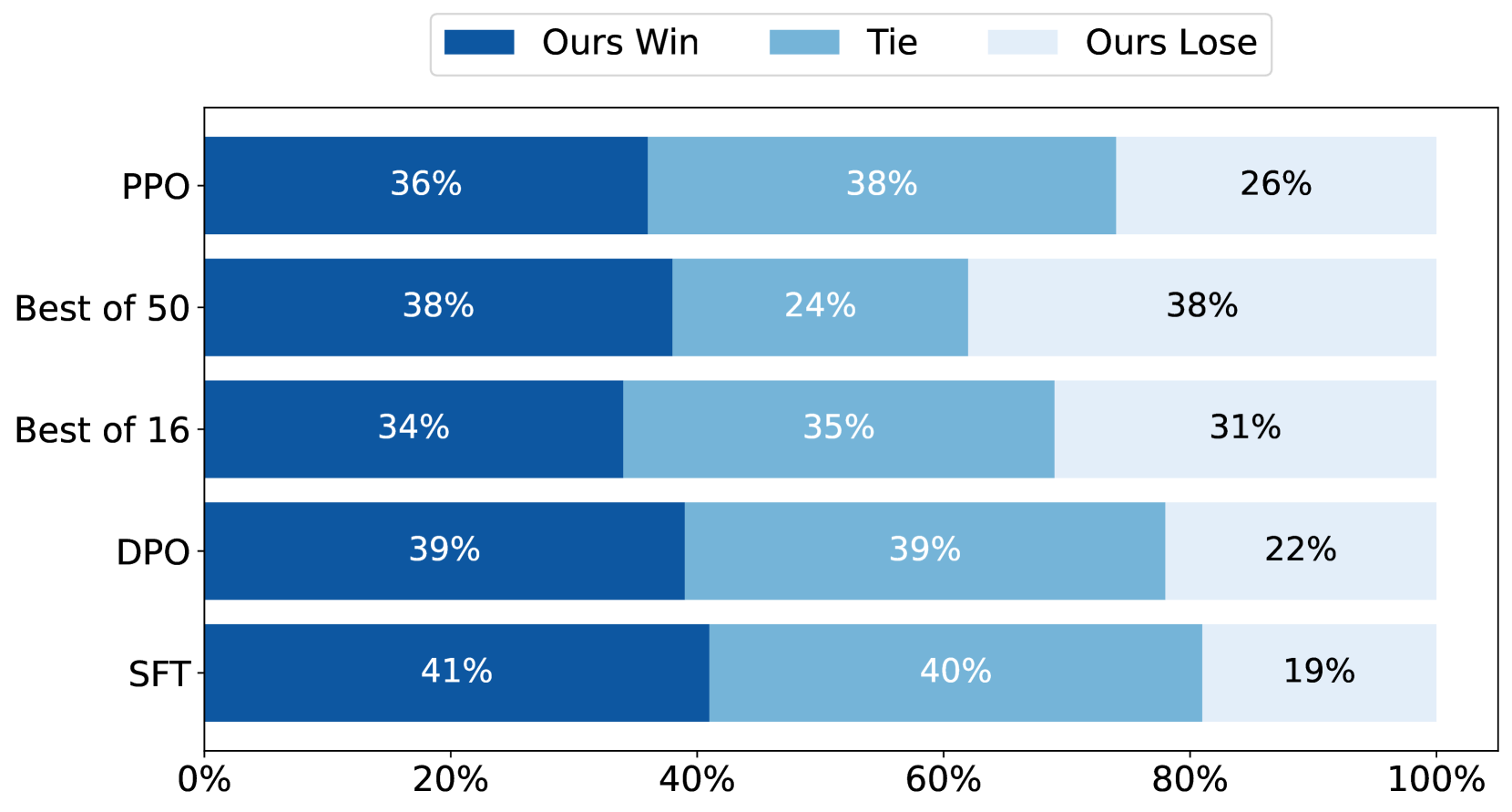
The proposed approach is evaluated on several benchmark tasks, including simulated multi-agent environments and real-world robotic control problems. The results demonstrate significant improvements in policy alignment over existing techniques that rely solely on demonstrations or preferences.
Critical Analysis
The paper presents a promising approach for improving the alignment of AI systems with human values and feedback. The joint learning framework is a conceptually simple yet effective way to combine the complementary strengths of demonstration and preference learning.
One potential limitation is that the method assumes the availability of both high-quality demonstrations and reliable human feedback. In real-world settings, these signals may not always be easy to obtain or may be subject to noise and bias. The paper does not extensively explore the robustness of the approach to imperfect or limited data.
Additionally, the adaptive preference scaling technique used in the method could benefit from further investigation. While the paper shows that it can improve performance, the underlying mechanisms and potential failure modes are not fully explored.
Overall, the research represents an important step towards developing AI systems that are more reliably aligned with human preferences. Further work to address the potential challenges and limitations could lead to even more robust and effective approaches for policy alignment.
Conclusion
This paper introduces a novel joint demonstration and preference learning framework that significantly improves the alignment of AI systems with human feedback. By combining observational learning from demonstrations and reward learning from preferences, the method enables the AI to build a more comprehensive understanding of human values and intentions.
The proposed approach outperforms existing techniques on a variety of benchmark tasks, demonstrating the power of integrating these two complementary learning signals. While the method has some potential limitations, it represents an important contribution to the field of AI alignment and could have far-reaching implications for the development of safe and beneficial artificial intelligence systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Getting More Juice Out of the SFT Data: Reward Learning from Human Demonstration Improves SFT for LLM Alignment
Jiaxiang Li, Siliang Zeng, Hoi-To Wai, Chenliang Li, Alfredo Garcia, Mingyi Hong
0
0
Aligning human preference and value is an important requirement for contemporary foundation models. State-of-the-art techniques such as Reinforcement Learning from Human Feedback (RLHF) often consist of two stages: 1) supervised fine-tuning (SFT), where the model is fine-tuned by learning from human demonstration data; 2) Preference learning, where preference data is used to learn a reward model, which is in turn used by a reinforcement learning (RL) step to fine-tune the model. Such reward model serves as a proxy to human preference, and it is critical to guide the RL step towards improving the model quality. In this work, we argue that the SFT stage significantly benefits from learning a reward model as well. Instead of using the human demonstration data directly via supervised learning, we propose to leverage an Inverse Reinforcement Learning (IRL) technique to (explicitly or implicitly) build an reward model, while learning the policy model. This approach leads to new SFT algorithms that are not only efficient to implement, but also promote the ability to distinguish between the preferred and non-preferred continuations. Moreover, we identify a connection between the proposed IRL based approach, and certain self-play approach proposed recently, and showed that self-play is a special case of modeling a reward-learning agent. Theoretically, we show that the proposed algorithms converge to the stationary solutions of the IRL problem. Empirically, we align 1B and 7B models using proposed methods and evaluate them on a reward benchmark model and the HuggingFace Open LLM Leaderboard. The proposed methods show significant performance improvement over existing SFT approaches. Our results indicate that it is beneficial to explicitly or implicitly leverage reward learning throughout the entire alignment process.
5/30/2024
Iterative Preference Learning from Human Feedback: Bridging Theory and Practice for RLHF under KL-Constraint
Wei Xiong, Hanze Dong, Chenlu Ye, Ziqi Wang, Han Zhong, Heng Ji, Nan Jiang, Tong Zhang
0
0
This paper studies the alignment process of generative models with Reinforcement Learning from Human Feedback (RLHF). We first identify the primary challenges of existing popular methods like offline PPO and offline DPO as lacking in strategical exploration of the environment. Then, to understand the mathematical principle of RLHF, we consider a standard mathematical formulation, the reverse-KL regularized contextual bandit for RLHF. Despite its widespread practical application, a rigorous theoretical analysis of this formulation remains open. We investigate its behavior in three distinct settings -- offline, online, and hybrid -- and propose efficient algorithms with finite-sample theoretical guarantees. Moving towards practical applications, our framework, with a robust approximation of the information-theoretical policy improvement oracle, naturally gives rise to several novel RLHF algorithms. This includes an iterative version of the Direct Preference Optimization (DPO) algorithm for online settings, and a multi-step rejection sampling strategy for offline scenarios. Our empirical evaluations on real-world alignment experiment of large language model demonstrate that these proposed methods significantly surpass existing strong baselines, such as DPO and Rejection Sampling Optimization (RSO), showcasing the connections between solid theoretical foundations and their potent practical implementations.
5/2/2024
🏅
Multi-turn Reinforcement Learning from Preference Human Feedback
Lior Shani, Aviv Rosenberg, Asaf Cassel, Oran Lang, Daniele Calandriello, Avital Zipori, Hila Noga, Orgad Keller, Bilal Piot, Idan Szpektor, Avinatan Hassidim, Yossi Matias, R'emi Munos
0
0
Reinforcement Learning from Human Feedback (RLHF) has become the standard approach for aligning Large Language Models (LLMs) with human preferences, allowing LLMs to demonstrate remarkable abilities in various tasks. Existing methods work by emulating the preferences at the single decision (turn) level, limiting their capabilities in settings that require planning or multi-turn interactions to achieve a long-term goal. In this paper, we address this issue by developing novel methods for Reinforcement Learning (RL) from preference feedback between two full multi-turn conversations. In the tabular setting, we present a novel mirror-descent-based policy optimization algorithm for the general multi-turn preference-based RL problem, and prove its convergence to Nash equilibrium. To evaluate performance, we create a new environment, Education Dialogue, where a teacher agent guides a student in learning a random topic, and show that a deep RL variant of our algorithm outperforms RLHF baselines. Finally, we show that in an environment with explicit rewards, our algorithm recovers the same performance as a reward-based RL baseline, despite relying solely on a weaker preference signal.
5/24/2024
Linear Alignment: A Closed-form Solution for Aligning Human Preferences without Tuning and Feedback
Songyang Gao, Qiming Ge, Wei Shen, Shihan Dou, Junjie Ye, Xiao Wang, Rui Zheng, Yicheng Zou, Zhi Chen, Hang Yan, Qi Zhang, Dahua Lin
0
0
The success of AI assistants based on Language Models (LLMs) hinges on Reinforcement Learning from Human Feedback (RLHF) to comprehend and align with user intentions. However, traditional alignment algorithms, such as PPO, are hampered by complex annotation and training requirements. This reliance limits the applicability of RLHF and hinders the development of professional assistants tailored to diverse human preferences. In this work, we introduce textit{Linear Alignment}, a novel algorithm that aligns language models with human preferences in one single inference step, eliminating the reliance on data annotation and model training. Linear alignment incorporates a new parameterization for policy optimization under divergence constraints, which enables the extraction of optimal policy in a closed-form manner and facilitates the direct estimation of the aligned response. Extensive experiments on both general and personalized preference datasets demonstrate that linear alignment significantly enhances the performance and efficiency of LLM alignment across diverse scenarios. Our code and dataset is published on url{https://github.com/Wizardcoast/Linear_Alignment.git}.
5/7/2024