Getting More Juice Out of the SFT Data: Reward Learning from Human Demonstration Improves SFT for LLM Alignment
2405.17888
0
0

Abstract
Aligning human preference and value is an important requirement for contemporary foundation models. State-of-the-art techniques such as Reinforcement Learning from Human Feedback (RLHF) often consist of two stages: 1) supervised fine-tuning (SFT), where the model is fine-tuned by learning from human demonstration data; 2) Preference learning, where preference data is used to learn a reward model, which is in turn used by a reinforcement learning (RL) step to fine-tune the model. Such reward model serves as a proxy to human preference, and it is critical to guide the RL step towards improving the model quality. In this work, we argue that the SFT stage significantly benefits from learning a reward model as well. Instead of using the human demonstration data directly via supervised learning, we propose to leverage an Inverse Reinforcement Learning (IRL) technique to (explicitly or implicitly) build an reward model, while learning the policy model. This approach leads to new SFT algorithms that are not only efficient to implement, but also promote the ability to distinguish between the preferred and non-preferred continuations. Moreover, we identify a connection between the proposed IRL based approach, and certain self-play approach proposed recently, and showed that self-play is a special case of modeling a reward-learning agent. Theoretically, we show that the proposed algorithms converge to the stationary solutions of the IRL problem. Empirically, we align 1B and 7B models using proposed methods and evaluate them on a reward benchmark model and the HuggingFace Open LLM Leaderboard. The proposed methods show significant performance improvement over existing SFT approaches. Our results indicate that it is beneficial to explicitly or implicitly leverage reward learning throughout the entire alignment process.
Create account to get full access
Overview
- This paper introduces a novel approach to improve the Supervised Fine-Tuning (SFT) process for Large Language Models (LLMs) by incorporating reward learning from human demonstration.
- The proposed method, called Reward-Augmented SFT (RA-SFT), aims to better align LLMs with human preferences and values.
- The authors demonstrate that RA-SFT outperforms traditional SFT on a range of tasks, including language generation, question answering, and downstream alignment.
Plain English Explanation
The paper presents a way to make large language models (LLMs) like GPT-3 or ChatGPT better align with human values and preferences. LLMs are trained on a vast amount of online data, which can sometimes lead to undesirable outputs that don't match what humans want.
The key idea of this work is to incorporate "reward learning" - essentially, training the model to recognize what humans consider good or bad responses. The researchers do this by having humans provide demonstrations of desirable language, and then training a reward model to predict how much humans would like a given output.
This reward model is then used to guide the fine-tuning process, rather than just relying on the original training data. The authors show that this "Reward-Augmented SFT" (RA-SFT) approach leads to language models that are better aligned with human values, as measured by performance on various tasks.
So in essence, the paper is about finding a way to imbue large language models with a better understanding of what humans want, by learning from human-provided examples and feedback. This could help make AI systems more reliably beneficial as they become more capable.
Technical Explanation
The paper introduces a novel approach called Reward-Augmented Supervised Fine-Tuning (RA-SFT) to improve the Supervised Fine-Tuning (SFT) process for aligning Large Language Models (LLMs) with human preferences.
In the RA-SFT framework, the authors first train a reward model to predict human preferences based on demonstrations of desirable language. This reward model is then used to guide the fine-tuning of the LLM, in addition to the original supervised objective.
Specifically, the authors use a two-stage training process:
- Train a reward model to predict human preferences by learning from demonstrations of good and bad language outputs.
- Fine-tune the LLM using both the original supervised objective and the learned reward signal from the reward model.
The authors show that this RA-SFT approach outperforms traditional SFT on a range of tasks, including language generation, question answering, and downstream alignment evaluations. The intuition is that the reward learning component helps the LLM better internalize human values and preferences, leading to more aligned behavior.
The paper also discusses connections to related work in intuitive fine-tuning, reward modeling, and optimizing for aligned rewards.
Critical Analysis
The paper presents a compelling approach to improving LLM alignment through reward learning from human demonstration. The authors provide thorough experimental results demonstrating the benefits of RA-SFT over traditional SFT.
However, the paper does not address some potential limitations and caveats. For instance, the reward learning process relies on human-provided demonstrations, which could be biased or incomplete. There are also open questions around the scalability of this approach and how it might perform on more complex or ambiguous language understanding tasks.
Additionally, the paper does not delve into potential negative societal impacts or unintended consequences that could arise from deploying such aligned language models at scale. Further research is needed to explore these issues in depth, as discussed in related work on mitigating overoptimization and RLHF workflows.
Overall, the RA-SFT approach represents an important step forward in aligning LLMs with human values, but continued scrutiny and responsible development will be crucial as these technologies become more powerful and widely deployed.
Conclusion
This paper introduces a novel method called Reward-Augmented Supervised Fine-Tuning (RA-SFT) that leverages reward learning from human demonstration to improve the alignment of Large Language Models (LLMs) with human preferences and values.
The key innovation is the two-stage training process that first learns a reward model from human-provided examples, and then uses that reward signal to guide the fine-tuning of the LLM. Experimental results show that RA-SFT outperforms traditional SFT on a range of tasks, suggesting it is a promising approach for developing more aligned AI systems.
While the paper makes a valuable contribution, it also highlights the need for further research to address potential limitations and consider the broader societal implications of this technology. Continued efforts to responsibly develop and deploy aligned LLMs will be crucial as these models become increasingly capable and influential.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
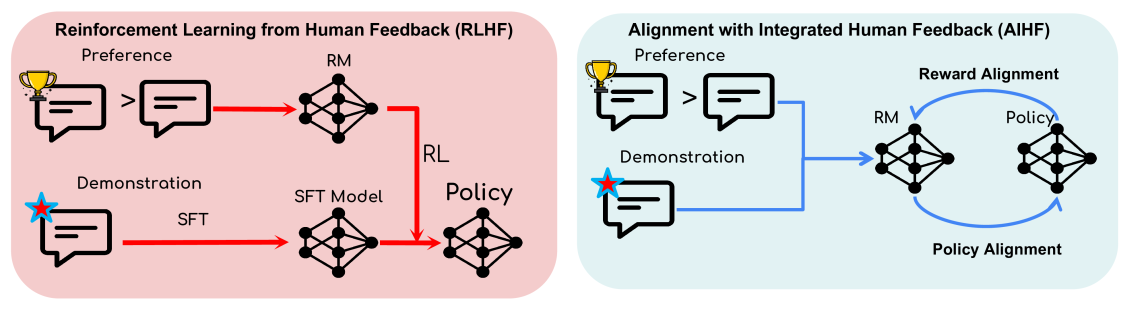
Joint Demonstration and Preference Learning Improves Policy Alignment with Human Feedback
Chenliang Li, Siliang Zeng, Zeyi Liao, Jiaxiang Li, Dongyeop Kang, Alfredo Garcia, Mingyi Hong
0
0
Aligning human preference and value is an important requirement for building contemporary foundation models and embodied AI. However, popular approaches such as reinforcement learning with human feedback (RLHF) break down the task into successive stages, such as supervised fine-tuning (SFT), reward modeling (RM), and reinforcement learning (RL), each performing one specific learning task. Such a sequential approach results in serious issues such as significant under-utilization of data and distribution mismatch between the learned reward model and generated policy, which eventually lead to poor alignment performance. We develop a single stage approach named Alignment with Integrated Human Feedback (AIHF), capable of integrating both human preference and demonstration to train reward models and the policy. The proposed approach admits a suite of efficient algorithms, which can easily reduce to, and leverage, popular alignment algorithms such as RLHF and Directly Policy Optimization (DPO), and only requires minor changes to the existing alignment pipelines. We demonstrate the efficiency of the proposed solutions with extensive experiments involving alignment problems in LLMs and robotic control problems in MuJoCo. We observe that the proposed solutions outperform the existing alignment algorithms such as RLHF and DPO by large margins, especially when the amount of high-quality preference data is relatively limited.
6/21/2024
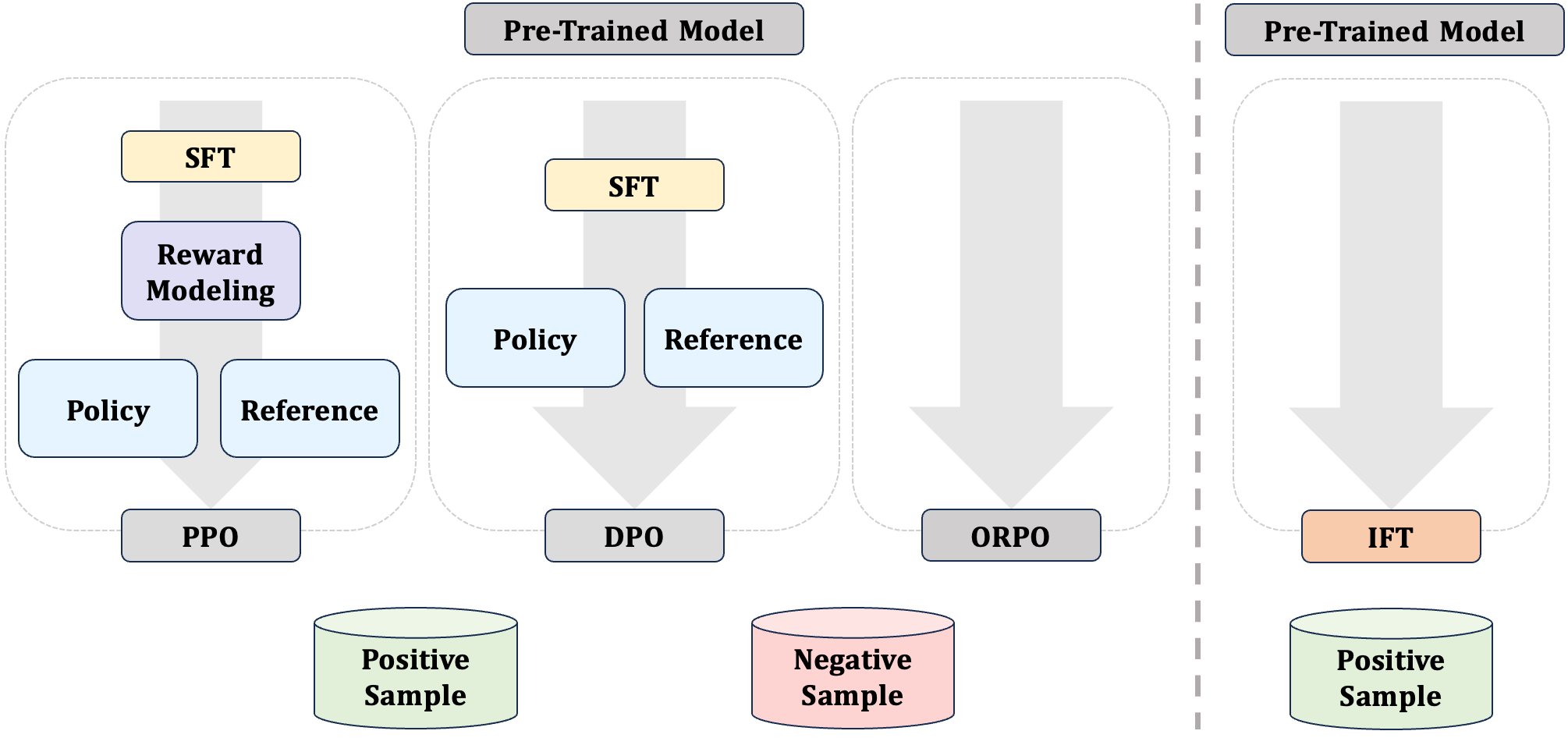
Intuitive Fine-Tuning: Towards Unifying SFT and RLHF into a Single Process
Ermo Hua, Biqing Qi, Kaiyan Zhang, Yue Yu, Ning Ding, Xingtai Lv, Kai Tian, Bowen Zhou
0
0
Supervised Fine-Tuning (SFT) and Preference Optimization (PO) are two fundamental processes for enhancing the capabilities of Language Models (LMs) post pre-training, aligning them better with human preferences. Although SFT advances in training efficiency, PO delivers better alignment, thus they are often combined. However, common practices simply apply them sequentially without integrating their optimization objectives, ignoring the opportunities to bridge their paradigm gap and take the strengths from both. To obtain a unified understanding, we interpret SFT and PO with two sub-processes -- Preference Estimation and Transition Optimization -- defined at token level within the Markov Decision Process (MDP) framework. This modeling shows that SFT is only a specialized case of PO with inferior estimation and optimization. PO evaluates the quality of model's entire generated answer, whereas SFT only scores predicted tokens based on preceding tokens from target answers. Therefore, SFT overestimates the ability of model, leading to inferior optimization. Building on this view, we introduce Intuitive Fine-Tuning (IFT) to integrate SFT and Preference Optimization into a single process. IFT captures LMs' intuitive sense of the entire answers through a temporal residual connection, but it solely relies on a single policy and the same volume of non-preference-labeled data as SFT. Our experiments show that IFT performs comparably or even superiorly to sequential recipes of SFT and some typical Preference Optimization methods across several tasks, particularly those requires generation, reasoning, and fact-following abilities. An explainable Frozen Lake game further validates the effectiveness of IFT for getting competitive policy.
5/29/2024
⛏️
SALMON: Self-Alignment with Instructable Reward Models
Zhiqing Sun, Yikang Shen, Hongxin Zhang, Qinhong Zhou, Zhenfang Chen, David Cox, Yiming Yang, Chuang Gan
0
0
Supervised Fine-Tuning (SFT) on response demonstrations combined with Reinforcement Learning from Human Feedback (RLHF) constitutes a powerful paradigm for aligning LLM-based AI agents. However, a significant limitation of such an approach is its dependency on high-quality human annotations, making its application to intricate tasks challenging due to difficulties in obtaining consistent response demonstrations and in-distribution response preferences. This paper presents a novel approach, namely SALMON, to align base language models with minimal human supervision, using only a small set of human-defined principles, yet achieving superior performance. Central to our approach is an instructable reward model. Trained on synthetic preference data, this model can generate reward scores based on arbitrary human-defined principles. By merely adjusting these principles during the RL training phase, we gain full control over the preferences with the instructable reward model, subsequently influencing the behavior of the RL-trained policy models, and reducing the reliance on the collection of online human preferences. Applying our method to the LLaMA-2-70b base language model, we developed an AI assistant named Dromedary-2. With only 6 exemplars for in-context learning and 31 human-defined principles, Dromedary-2 significantly surpasses the performance of several state-of-the-art AI systems, including LLaMA-2-Chat-70b, on various benchmark datasets. We have open-sourced the code and model weights to encourage further research into aligning LLM-based AI agents with enhanced supervision efficiency, improved controllability, and scalable oversight.
4/11/2024
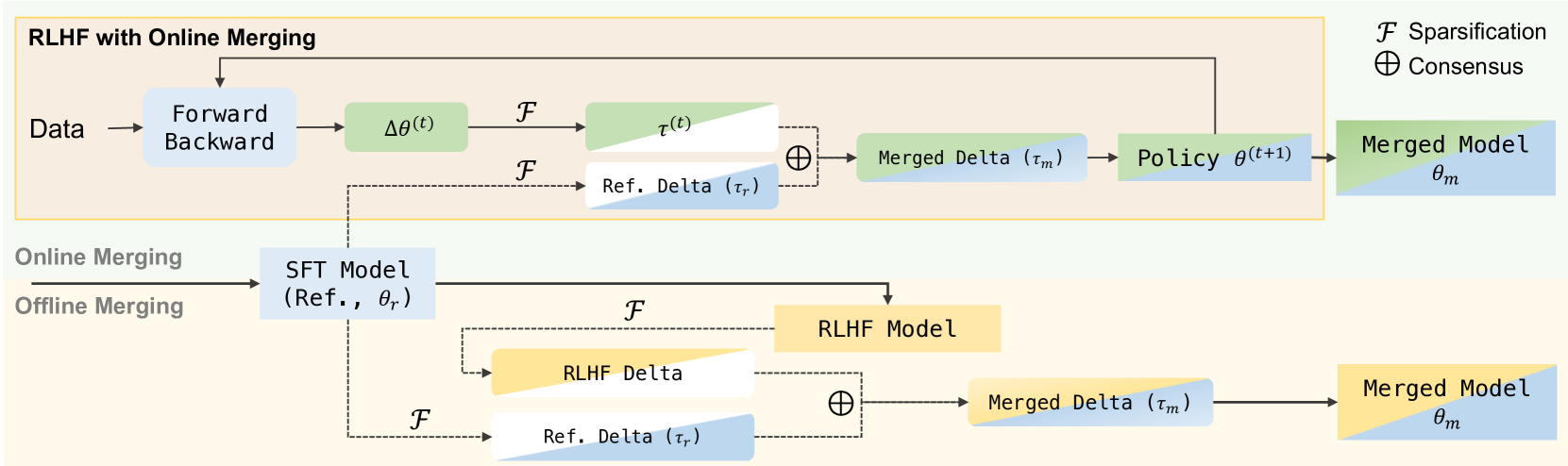
Online Merging Optimizers for Boosting Rewards and Mitigating Tax in Alignment
Keming Lu, Bowen Yu, Fei Huang, Yang Fan, Runji Lin, Chang Zhou
0
0
Effectively aligning Large Language Models (LLMs) with human-centric values while preventing the degradation of abilities acquired through Pre-training and Supervised Fine-tuning (SFT) poses a central challenge in Reinforcement Learning from Human Feedback (RLHF). In this paper, we first discover that interpolating RLHF and SFT model parameters can adjust the trade-off between human preference and basic capabilities, thereby reducing the alignment tax at the cost of alignment reward. Inspired by this, we propose integrating the RL policy and SFT models at each optimization step in RLHF to continuously regulate the training direction, introducing the Online Merging Optimizer. Specifically, we merge gradients with the parameter differences between SFT and pretrained models, effectively steering the gradient towards maximizing rewards in the direction of SFT optimization. We demonstrate that our optimizer works well with different LLM families, such as Qwen and LLaMA, across various model sizes ranging from 1.8B to 8B, various RLHF algorithms like DPO and KTO, and existing model merging methods. It significantly enhances alignment reward while mitigating alignment tax, achieving higher overall performance across 14 benchmarks.
5/29/2024