Federated Learning for Cooperative Inference Systems: The Case of Early Exit Networks
2405.04249
0
0
🤯
Abstract
As Internet of Things (IoT) technology advances, end devices like sensors and smartphones are progressively equipped with AI models tailored to their local memory and computational constraints. Local inference reduces communication costs and latency; however, these smaller models typically underperform compared to more sophisticated models deployed on edge servers or in the cloud. Cooperative Inference Systems (CISs) address this performance trade-off by enabling smaller devices to offload part of their inference tasks to more capable devices. These systems often deploy hierarchical models that share numerous parameters, exemplified by Deep Neural Networks (DNNs) that utilize strategies like early exits or ordered dropout. In such instances, Federated Learning (FL) may be employed to jointly train the models within a CIS. Yet, traditional training methods have overlooked the operational dynamics of CISs during inference, particularly the potential high heterogeneity in serving rates across clients. To address this gap, we propose a novel FL approach designed explicitly for use in CISs that accounts for these variations in serving rates. Our framework not only offers rigorous theoretical guarantees, but also surpasses state-of-the-art (SOTA) training algorithms for CISs, especially in scenarios where inference request rates or data availability are uneven among clients.
Create account to get full access
Overview
- As Internet of Things (IoT) devices become more advanced, they are being equipped with AI models tailored to their local memory and computational constraints.
- Local inference on these devices can reduce communication costs and latency, but the models are typically less sophisticated than those deployed on edge servers or in the cloud.
- Cooperative Inference Systems (CISs) aim to address this performance trade-off by enabling smaller devices to offload part of their inference tasks to more capable devices.
- These CISs often use hierarchical models that share numerous parameters, such as Deep Neural Networks (DNNs) with strategies like early exits or ordered dropout.
- Federated Learning (FL) may be employed to jointly train the models within a CIS, but traditional training methods have overlooked the operational dynamics of CISs during inference, particularly the potential high heterogeneity in serving rates across clients.
Plain English Explanation
As technology advances, the sensors, smartphones, and other end devices we use are getting smarter. These devices are now equipped with their own AI models, tailored to the limited memory and processing power they have available. This local AI processing can reduce the time and cost of sending data back and forth to more powerful servers.
However, these smaller models on the end devices typically don't perform as well as the more sophisticated models that can be run on servers or in the cloud. To address this, researchers have developed Cooperative Inference Systems (CISs). In a CIS, smaller devices can offload part of their AI tasks to more capable devices, allowing them to benefit from more powerful models.
CISs often use hierarchical models that share many of the same underlying components, like the layers in a Deep Neural Network (DNN). This allows the models to be trained together using Federated Learning (FL), where the devices collaborate to improve the shared model without sharing their raw data.
However, traditional FL methods have not considered the unique dynamics of CISs during the actual inference (or prediction) process. In particular, there can be significant differences in how quickly different devices can respond to requests, which can impact the overall performance of the system. This paper proposes a new FL approach designed specifically for CISs that takes these variations in serving rates into account.
Technical Explanation
The paper proposes a novel Federated Learning (FL) approach tailored for use in Cooperative Inference Systems (CISs). CISs enable smaller, resource-constrained devices to offload part of their AI inference tasks to more capable devices, allowing them to leverage more sophisticated models.
These CISs often employ hierarchical models, such as Deep Neural Networks (DNNs), that share numerous parameters. Strategies like early exits or ordered dropout are used to enable this parameter sharing. FL can be used to jointly train the models within a CIS, but traditional FL methods have overlooked the operational dynamics during inference, particularly the potential high heterogeneity in serving rates across clients.
To address this gap, the proposed framework accounts for variations in client serving rates. It offers rigorous theoretical guarantees and outperforms state-of-the-art (SOTA) training algorithms for CISs, especially in scenarios where inference request rates or data availability are uneven among clients.
The key technical contributions include:
- A new FL algorithm designed for CIS environments that explicitly considers variations in client serving rates.
- Theoretical analysis demonstrating the algorithm's convergence guarantees and its advantages over SOTA methods.
- Extensive experiments validating the superior performance of the proposed approach, particularly in heterogeneous settings.
Critical Analysis
The paper presents a valuable contribution to the field of Cooperative Inference Systems (CISs) and Federated Learning (FL). By explicitly considering the variations in client serving rates during the inference process, the proposed FL algorithm addresses an important practical concern that was overlooked in previous work.
One potential limitation is the assumption of a known upper bound on the serving rate heterogeneity. In real-world deployments, this bound may be difficult to estimate accurately. The authors acknowledge this and suggest exploring adaptive techniques to relax this assumption.
Additionally, the experiments focus on a specific CIS architecture with hierarchical models. While this is a common setup, it would be interesting to see how the proposed approach performs in CISs with other model structures or task distributions.
Further research could also investigate the interplay between the FL training process and the CIS inference dynamics. For example, how do changes in the shared model during training impact the overall CIS performance, and how can the training process be optimized to account for these effects?
Overall, the paper presents a well-designed and rigorously evaluated solution to an important problem in the context of Cooperative Inference Systems. The insights and techniques developed in this work could have significant implications for improving the performance and robustness of edge AI systems in the Internet of Things.
Conclusion
This paper addresses a key challenge in Cooperative Inference Systems (CISs) by proposing a novel Federated Learning (FL) approach that accounts for variations in client serving rates during the inference process. By considering these operational dynamics, the framework is able to outperform state-of-the-art training algorithms, particularly in scenarios with uneven inference request rates or data availability across clients.
The theoretical guarantees and experimental results demonstrate the effectiveness of the proposed solution, highlighting its potential to enhance the performance and reliability of edge AI systems in the Internet of Things. As these systems become more prevalent, addressing the nuances of CIS operation will be critical to unlocking the full benefits of distributed AI inference at the edge.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤷
Semi-Federated Learning for Internet of Intelligence
Wanli Ni, Zhaohui Yang
0
0
One key vision of intelligent Internet of Things (IoT) is to provide connected intelligence for a large number of application scenarios, such as self-driving cars, industrial manufacturing, and smart city. However, existing centralized or federated learning paradigms have difficulties in coordinating heterogeneous resources in distributed IoT environments. In this article, we introduce a semi-federated learning (SemiFL) framework to tackle the challenges of data and device heterogeneity in massive IoT networks. In SemiFL, only users with sufficient computing resources are selected for local model training, while the remaining users only transmit raw data to the base station for remote computing. By doing so, SemiFL incorporates conventional centralized and federated learning paradigms into a harmonized framework that allows all devices to participate in the global model training regardless of their computational capabilities and data distributions. Furthermore, we propose a next-generation multiple access scheme by seamlessly integrating communication and computation over the air. This achieves the concurrent transmission of raw data and model parameters in a spectrum-efficient manner. With their abilities to change channels and charge devices, two emerging techniques, reconfigurable intelligent surface and wireless energy transfer, are merged with our SemiFL framework to enhance its performance in bandwidth- and energy-limited IoT networks, respectively. Simulation results are presented to demonstrate the superiority of our SemiFL for achieving edge intelligence among computing-heterogeneous IoT devices.
5/29/2024
Toward efficient resource utilization at edge nodes in federated learning
Sadi Alawadi, Addi Ait-Mlouk, Salman Toor, Andreas Hellander
0
0
Federated learning (FL) enables edge nodes to collaboratively contribute to constructing a global model without sharing their data. This is accomplished by devices computing local, private model updates that are then aggregated by a server. However, computational resource constraints and network communication can become a severe bottleneck for larger model sizes typical for deep learning applications. Edge nodes tend to have limited hardware resources (RAM, CPU), and the network bandwidth and reliability at the edge is a concern for scaling federated fleet applications. In this paper, we propose and evaluate a FL strategy inspired by transfer learning in order to reduce resource utilization on devices, as well as the load on the server and network in each global training round. For each local model update, we randomly select layers to train, freezing the remaining part of the model. In doing so, we can reduce both server load and communication costs per round by excluding all untrained layer weights from being transferred to the server. The goal of this study is to empirically explore the potential trade-off between resource utilization on devices and global model convergence under the proposed strategy. We implement the approach using the federated learning framework FEDn. A number of experiments were carried out over different datasets (CIFAR-10, CASA, and IMDB), performing different tasks using different deep-learning model architectures. Our results show that training the model partially can accelerate the training process, efficiently utilizes resources on-device, and reduce the data transmission by around 75% and 53% when we train 25%, and 50% of the model layers, respectively, without harming the resulting global model accuracy.
6/12/2024
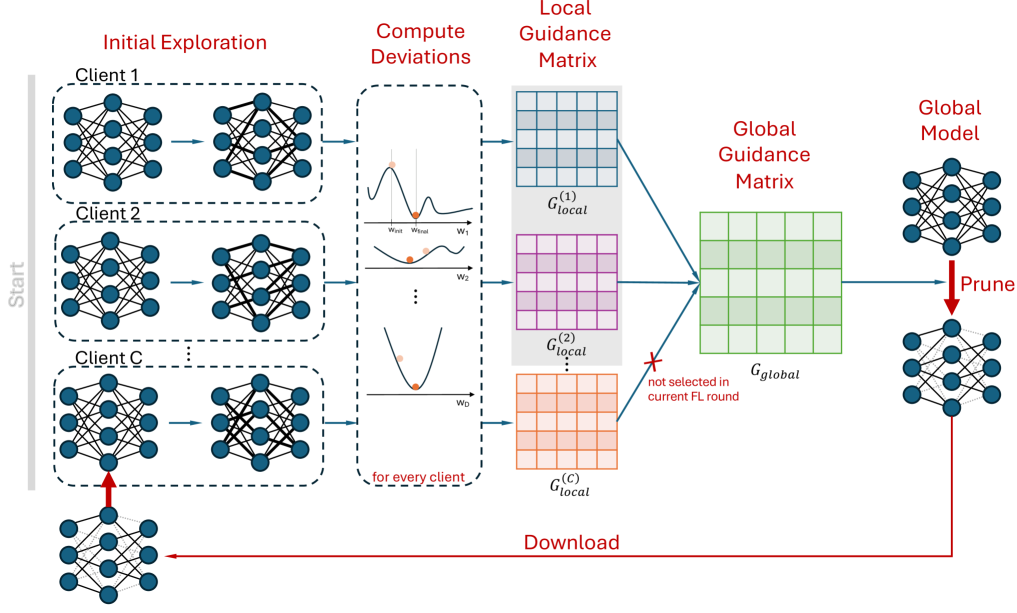
Automated Federated Learning via Informed Pruning
Christian Intern`o, Elena Raponi, Niki van Stein, Thomas Back, Markus Olhofer, Yaochu Jin, Barbara Hammer
0
0
Federated learning (FL) represents a pivotal shift in machine learning (ML) as it enables collaborative training of local ML models coordinated by a central aggregator, all without the need to exchange local data. However, its application on edge devices is hindered by limited computational capabilities and data communication challenges, compounded by the inherent complexity of Deep Learning (DL) models. Model pruning is identified as a key technique for compressing DL models on devices with limited resources. Nonetheless, conventional pruning techniques typically rely on manually crafted heuristics and demand human expertise to achieve a balance between model size, speed, and accuracy, often resulting in sub-optimal solutions. In this study, we introduce an automated federated learning approach utilizing informed pruning, called AutoFLIP, which dynamically prunes and compresses DL models within both the local clients and the global server. It leverages a federated loss exploration phase to investigate model gradient behavior across diverse datasets and losses, providing insights into parameter significance. Our experiments showcase notable enhancements in scenarios with strong non-IID data, underscoring AutoFLIP's capacity to tackle computational constraints and achieve superior global convergence.
5/17/2024
🏋️
Recurrent Early Exits for Federated Learning with Heterogeneous Clients
Royson Lee, Javier Fernandez-Marques, Shell Xu Hu, Da Li, Stefanos Laskaridis, {L}ukasz Dudziak, Timothy Hospedales, Ferenc Husz'ar, Nicholas D. Lane
0
0
Federated learning (FL) has enabled distributed learning of a model across multiple clients in a privacy-preserving manner. One of the main challenges of FL is to accommodate clients with varying hardware capacities; clients have differing compute and memory requirements. To tackle this challenge, recent state-of-the-art approaches leverage the use of early exits. Nonetheless, these approaches fall short of mitigating the challenges of joint learning multiple exit classifiers, often relying on hand-picked heuristic solutions for knowledge distillation among classifiers and/or utilizing additional layers for weaker classifiers. In this work, instead of utilizing multiple classifiers, we propose a recurrent early exit approach named ReeFL that fuses features from different sub-models into a single shared classifier. Specifically, we use a transformer-based early-exit module shared among sub-models to i) better exploit multi-layer feature representations for task-specific prediction and ii) modulate the feature representation of the backbone model for subsequent predictions. We additionally present a per-client self-distillation approach where the best sub-model is automatically selected as the teacher of the other sub-models at each client. Our experiments on standard image and speech classification benchmarks across various emerging federated fine-tuning baselines demonstrate ReeFL's effectiveness over previous works.
5/28/2024