Just ASR + LLM? A Study on Speech Large Language Models' Ability to Identify and Understand Speaker in Spoken Dialogue

0

Sign in to get full access
Overview
- The paper explores the ability of speech large language models (LLMs) to identify and understand speakers in spoken dialogues.
- It compares the performance of just using automatic speech recognition (ASR) versus using ASR combined with LLMs.
- The authors conduct experiments on a dataset of spoken dialogues and analyze the models' performance in speaker identification and dialogue understanding.
Plain English Explanation
The researchers wanted to see how well language models trained on a lot of speech data (speech LLMs) could identify who was speaking and understand the meaning of conversations, compared to just using speech recognition technology alone. They tested this by having the models listen to recorded conversations and try to figure out who was talking and what they were saying.
The key idea is that speech LLMs, which are trained on vast amounts of spoken language data, may be able to pick up on subtle cues and patterns that could help them better understand things like who the speaker is and the overall meaning of a conversation, beyond what a basic speech recognition system can do. This could be useful for applications like virtual assistants, meeting transcription, and dialogue systems.
The researchers compared the performance of using just speech recognition versus using speech recognition combined with a speech LLM on a dataset of recorded conversations. They looked at how well the models could identify the speaker and understand the meaning and context of the dialogue.
Technical Explanation
The paper investigates the ability of speech large language models (LLMs) to identify speakers and understand the meaning of spoken dialogues, compared to using just automatic speech recognition (ASR) alone.
The authors conduct experiments on a dataset of spoken dialogues, evaluating the models' performance on two key tasks:
- Speaker identification: Determining who is speaking at each turn in the dialogue.
- Dialogue understanding: Assessing the models' comprehension of the overall meaning and context of the conversation.
They compare the performance of an ASR-only baseline to models that combine ASR with different speech LLM architectures, including MALA and LibriSQA. The speech LLMs are pre-trained on large datasets of speech data and fine-tuned on the dialogue task.
The results show that the combined ASR + speech LLM models outperform the ASR-only baseline on both speaker identification and dialogue understanding, demonstrating the value that speech LLMs can bring to these types of spoken language understanding tasks. The paper provides insights into the strengths and limitations of this approach and discusses potential future research directions.
Critical Analysis
The paper provides a thorough investigation of speech LLMs' capabilities for speaker identification and dialogue understanding, an important area of research for developing more robust and adaptive spoken language systems.
One potential limitation is the use of a single dataset, which may not fully capture the diversity of real-world spoken dialogue scenarios. Expanding the evaluation to additional datasets, including more natural conversations, could strengthen the generalizability of the findings.
Additionally, the paper does not explore the impact of different fine-tuning strategies or the role of speech-specific pretraining on the models' performance. Further research into these areas could yield additional insights to optimize the speech LLM approach.
Overall, the paper makes a valuable contribution by demonstrating the potential of speech LLMs to enhance spoken language understanding beyond what can be achieved with ASR alone. Encouraging readers to think critically about the research and its implications is an important aspect of this study.
Conclusion
This paper presents a compelling case for the use of speech large language models (LLMs) in improving the identification of speakers and the understanding of spoken dialogues, compared to relying solely on automatic speech recognition (ASR).
The key finding is that the combination of ASR and speech LLMs outperforms ASR alone on tasks like speaker identification and dialogue understanding. This suggests that speech LLMs can capture important contextual and language cues that enhance spoken language understanding, with potential applications in virtual assistants, meeting transcription, and other dialogue-based systems.
While the research is limited to a single dataset, it provides a strong foundation for further exploration of speech LLMs and their ability to advance the state of the art in spoken language processing. Continued advancements in this area could lead to more natural, adaptive, and intelligent spoken language interfaces that better understand and respond to human conversation.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Just ASR + LLM? A Study on Speech Large Language Models' Ability to Identify and Understand Speaker in Spoken Dialogue
Junkai Wu, Xulin Fan, Bo-Ru Lu, Xilin Jiang, Nima Mesgarani, Mark Hasegawa-Johnson, Mari Ostendorf
In recent years, we have observed a rapid advancement in speech language models (SpeechLLMs), catching up with humans' listening and reasoning abilities. Remarkably, SpeechLLMs have demonstrated impressive spoken dialogue question-answering (SQA) performance in benchmarks like Gaokao, the English listening test of the college entrance exam in China, which seemingly requires understanding both the spoken content and voice characteristics of speakers in a conversation. However, after carefully examining Gaokao's questions, we find the correct answers to many questions can be inferred from the conversation context alone without identifying the speaker asked in the question. Our evaluation of state-of-the-art models Qwen-Audio and WavLLM in both Gaokao and our proposed What Do You Like? dataset shows a significantly higher accuracy in these context-based questions than in identity-critical questions, which can only be answered correctly with correct speaker identification. Our results and analysis suggest that when solving SQA, the current SpeechLLMs exhibit limited speaker awareness from the audio and behave similarly to an LLM reasoning from the conversation transcription without sound. We propose that our definitions and automated classification of context-based and identity-critical questions could offer a more accurate evaluation framework of SpeechLLMs in SQA tasks.
Read more9/10/2024
0
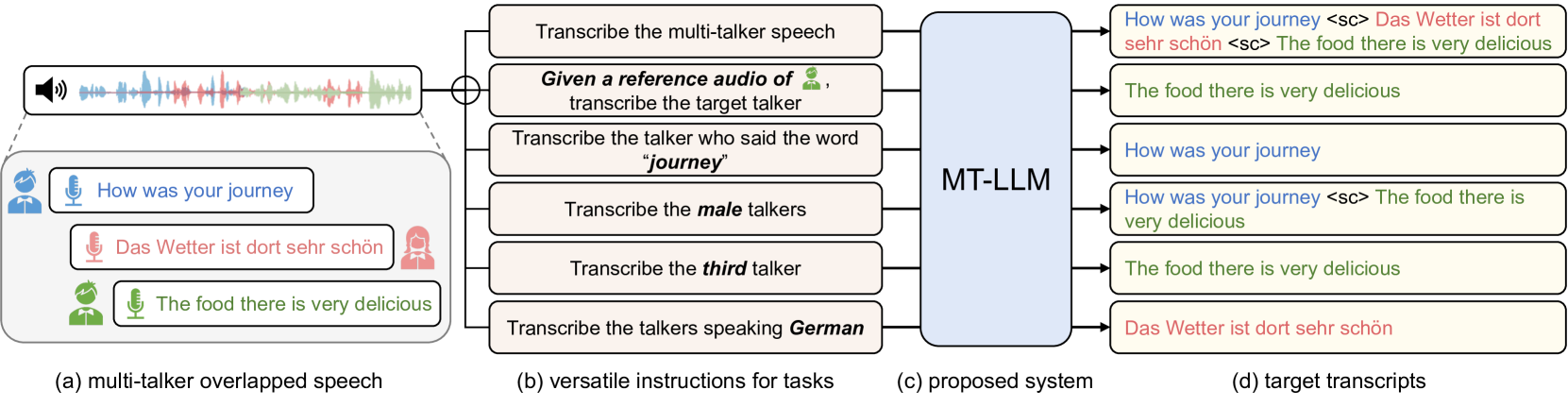
New!Large Language Model Can Transcribe Speech in Multi-Talker Scenarios with Versatile Instructions
Lingwei Meng, Shujie Hu, Jiawen Kang, Zhaoqing Li, Yuejiao Wang, Wenxuan Wu, Xixin Wu, Xunying Liu, Helen Meng
Recent advancements in large language models (LLMs) have revolutionized various domains, bringing significant progress and new opportunities. Despite progress in speech-related tasks, LLMs have not been sufficiently explored in multi-talker scenarios. In this work, we present a pioneering effort to investigate the capability of LLMs in transcribing speech in multi-talker environments, following versatile instructions related to multi-talker automatic speech recognition (ASR), target talker ASR, and ASR based on specific talker attributes such as sex, occurrence order, language, and keyword spoken. Our approach utilizes WavLM and Whisper encoder to extract multi-faceted speech representations that are sensitive to speaker characteristics and semantic context. These representations are then fed into an LLM fine-tuned using LoRA, enabling the capabilities for speech comprehension and transcription. Comprehensive experiments reveal the promising performance of our proposed system, MT-LLM, in cocktail party scenarios, highlighting the potential of LLM to handle speech-related tasks based on user instructions in such complex settings.
Read more9/16/2024
0
WavLLM: Towards Robust and Adaptive Speech Large Language Model
Shujie Hu, Long Zhou, Shujie Liu, Sanyuan Chen, Lingwei Meng, Hongkun Hao, Jing Pan, Xunying Liu, Jinyu Li, Sunit Sivasankaran, Linquan Liu, Furu Wei
The recent advancements in large language models (LLMs) have revolutionized the field of natural language processing, progressively broadening their scope to multimodal perception and generation. However, effectively integrating listening capabilities into LLMs poses significant challenges, particularly with respect to generalizing across varied contexts and executing complex auditory tasks. In this work, we introduce WavLLM, a robust and adaptive speech large language model with dual encoders, and a prompt-aware LoRA weight adapter, optimized by a two-stage curriculum learning approach. Leveraging dual encoders, we decouple different types of speech information, utilizing a Whisper encoder to process the semantic content of speech, and a WavLM encoder to capture the unique characteristics of the speaker's identity. Within the curriculum learning framework, WavLLM first builds its foundational capabilities by optimizing on mixed elementary single tasks, followed by advanced multi-task training on more complex tasks such as combinations of the elementary tasks. To enhance the flexibility and adherence to different tasks and instructions, a prompt-aware LoRA weight adapter is introduced in the second advanced multi-task training stage. We validate the proposed model on universal speech benchmarks including tasks such as ASR, ST, SV, ER, and also apply it to specialized datasets like Gaokao English listening comprehension set for SQA, and speech Chain-of-Thought (CoT) evaluation set. Experiments demonstrate that the proposed model achieves state-of-the-art performance across a range of speech tasks on the same model size, exhibiting robust generalization capabilities in executing complex tasks using CoT approach. Furthermore, our model successfully completes Gaokao tasks without specialized training. The codes, models, audio, and Gaokao evaluation set can be accessed at url{aka.ms/wavllm}.
Read more8/15/2024
🤿
0
Unveiling the Potential of LLM-Based ASR on Chinese Open-Source Datasets
Xuelong Geng, Tianyi Xu, Kun Wei, Bingshen Mu, Hongfei Xue, He Wang, Yangze Li, Pengcheng Guo, Yuhang Dai, Longhao Li, Mingchen Shao, Lei Xie
Large Language Models (LLMs) have demonstrated unparalleled effectiveness in various NLP tasks, and integrating LLMs with automatic speech recognition (ASR) is becoming a mainstream paradigm. Building upon this momentum, our research delves into an in-depth examination of this paradigm on a large open-source Chinese dataset. Specifically, our research aims to evaluate the impact of various configurations of speech encoders, LLMs, and projector modules in the context of the speech foundation encoder-LLM ASR paradigm. Furthermore, we introduce a three-stage training approach, expressly developed to enhance the model's ability to align auditory and textual information. The implementation of this approach, alongside the strategic integration of ASR components, enabled us to achieve the SOTA performance on the AISHELL-1, Test_Net, and Test_Meeting test sets. Our analysis presents an empirical foundation for future research in LLM-based ASR systems and offers insights into optimizing performance using Chinese datasets. We will publicly release all scripts used for data preparation, training, inference, and scoring, as well as pre-trained models and training logs to promote reproducible research.
Read more5/7/2024