Kaleido Diffusion: Improving Conditional Diffusion Models with Autoregressive Latent Modeling

0

Sign in to get full access
Overview
- This paper introduces Kaleido Diffusion, a novel approach to improving conditional diffusion models by leveraging autoregressive latent modeling.
- Kaleido Diffusion aims to enhance the performance and capabilities of diffusion models, which have shown impressive results in tasks like image generation and text-to-image synthesis.
- The key idea is to combine the strengths of diffusion models and autoregressive models, capturing both global and local dependencies in the data.
Plain English Explanation
Diffusion models are a type of machine learning model that have become very popular for tasks like generating images. These models work by gradually adding noise to an image, and then learning how to reverse that process to generate new images. They're good at capturing the overall structure and patterns in the data.
However, diffusion models can struggle to capture fine-level details and local dependencies. That's where autoregressive models come in - these models are good at modeling the local, sequential structure of data, like the relationships between neighboring pixels in an image.
The Kaleido Diffusion approach combines the strengths of diffusion and autoregressive models. It uses a diffusion model to capture the global structure of the data, and then an autoregressive model to capture the local, fine-grained details. This allows the model to generate images with both high-level coherence and low-level realism.
The researchers show that Kaleido Diffusion outperforms standard diffusion models on a range of image generation tasks, including conditional image synthesis, where the model generates an image based on some input information like a text description. This could have important applications in areas like content creation, visual storytelling, and even scientific visualization.
Technical Explanation
The Kaleido Diffusion model consists of two key components:
- A diffusion model that captures the global structure of the data. This model learns to gradually add noise to an image and then reverse the process to generate new images.
- An autoregressive model that captures the local, fine-grained details. This model learns to predict the value of each pixel in the image based on the surrounding context.
The two models are trained jointly, with the autoregressive model taking the latent representation from the diffusion model as input. This allows the autoregressive model to refine the global structure learned by the diffusion model with local, context-aware details.
The researchers evaluate Kaleido Diffusion on a variety of image generation tasks, including unconditional image generation, class-conditional image generation, and text-to-image synthesis. They show that Kaleido Diffusion outperforms standard diffusion models across these tasks, generating images with improved visual quality and diversity.
The technical paper provides a detailed description of the Kaleido Diffusion architecture, the training procedure, and the experimental results. It also discusses potential limitations and future research directions, such as extending the approach to other modalities beyond images.
Critical Analysis
The Kaleido Diffusion paper presents a compelling approach for improving the performance of conditional diffusion models. By combining the strengths of diffusion and autoregressive models, the researchers have developed a more powerful and flexible framework for image generation.
One potential limitation of the approach is the increased computational complexity and training time due to the additional autoregressive model. The researchers mention that this trade-off may be worth it for certain applications, but it's an important consideration for real-world deployment.
Additionally, the paper focuses primarily on image generation tasks and doesn't explore the application of Kaleido Diffusion to other modalities, such as text generation or audio synthesis. It would be interesting to see if the core ideas of Kaleido Diffusion can be generalized to these other domains.
Overall, the Kaleido Diffusion paper represents an exciting step forward in the development of more powerful and versatile diffusion models. The combination of global and local modeling could have significant implications for a wide range of applications in the field of generative AI.
Conclusion
The Kaleido Diffusion paper introduces a novel approach for improving the performance of conditional diffusion models by integrating autoregressive latent modeling. By leveraging the strengths of both diffusion and autoregressive models, Kaleido Diffusion is able to generate images with enhanced visual quality and diversity.
The key contribution of this work is the insight that combining global and local modeling can lead to significant improvements in generative tasks like image synthesis. This approach has the potential to unlock new capabilities in a wide range of applications, from content creation and visual storytelling to scientific visualization and beyond.
While the paper focuses primarily on image generation, the core principles of Kaleido Diffusion could be extended to other modalities, opening up exciting avenues for future research. As the field of generative AI continues to evolve, innovative approaches like Kaleido Diffusion will play a crucial role in pushing the boundaries of what's possible.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Kaleido Diffusion: Improving Conditional Diffusion Models with Autoregressive Latent Modeling
Jiatao Gu, Ying Shen, Shuangfei Zhai, Yizhe Zhang, Navdeep Jaitly, Joshua M. Susskind
Diffusion models have emerged as a powerful tool for generating high-quality images from textual descriptions. Despite their successes, these models often exhibit limited diversity in the sampled images, particularly when sampling with a high classifier-free guidance weight. To address this issue, we present Kaleido, a novel approach that enhances the diversity of samples by incorporating autoregressive latent priors. Kaleido integrates an autoregressive language model that encodes the original caption and generates latent variables, serving as abstract and intermediary representations for guiding and facilitating the image generation process. In this paper, we explore a variety of discrete latent representations, including textual descriptions, detection bounding boxes, object blobs, and visual tokens. These representations diversify and enrich the input conditions to the diffusion models, enabling more diverse outputs. Our experimental results demonstrate that Kaleido effectively broadens the diversity of the generated image samples from a given textual description while maintaining high image quality. Furthermore, we show that Kaleido adheres closely to the guidance provided by the generated latent variables, demonstrating its capability to effectively control and direct the image generation process.
Read more6/3/2024

0
LaDiC: Are Diffusion Models Really Inferior to Autoregressive Counterparts for Image-to-Text Generation?
Yuchi Wang, Shuhuai Ren, Rundong Gao, Linli Yao, Qingyan Guo, Kaikai An, Jianhong Bai, Xu Sun
Diffusion models have exhibited remarkable capabilities in text-to-image generation. However, their performance in image-to-text generation, specifically image captioning, has lagged behind Auto-Regressive (AR) models, casting doubt on their applicability for such tasks. In this work, we revisit diffusion models, highlighting their capacity for holistic context modeling and parallel decoding. With these benefits, diffusion models can alleviate the inherent limitations of AR methods, including their slow inference speed, error propagation, and unidirectional constraints. Furthermore, we identify the prior underperformance of diffusion models stemming from the absence of an effective latent space for image-text alignment, and the discrepancy between continuous diffusion processes and discrete textual data. In response, we introduce a novel architecture, LaDiC, which utilizes a split BERT to create a dedicated latent space for captions and integrates a regularization module to manage varying text lengths. Our framework also includes a diffuser for semantic image-to-text conversion and a Back&Refine technique to enhance token interactivity during inference. LaDiC achieves state-of-the-art performance for diffusion-based methods on the MS COCO dataset with 38.2 BLEU@4 and 126.2 CIDEr, demonstrating exceptional performance without pre-training or ancillary modules. This indicates strong competitiveness with AR models, revealing the previously untapped potential of diffusion models in image-to-text generation.
Read more4/17/2024
💬
0
Simple and Effective Masked Diffusion Language Models
Subham Sekhar Sahoo, Marianne Arriola, Yair Schiff, Aaron Gokaslan, Edgar Marroquin, Justin T Chiu, Alexander Rush, Volodymyr Kuleshov
While diffusion models excel at generating high-quality images, prior work reports a significant performance gap between diffusion and autoregressive (AR) methods in language modeling. In this work, we show that simple masked discrete diffusion is more performant than previously thought. We apply an effective training recipe that improves the performance of masked diffusion models and derive a simplified, Rao-Blackwellized objective that results in additional improvements. Our objective has a simple form -- it is a mixture of classical masked language modeling losses -- and can be used to train encoder-only language models that admit efficient samplers, including ones that can generate arbitrary lengths of text semi-autoregressively like a traditional language model. On language modeling benchmarks, a range of masked diffusion models trained with modern engineering practices achieves a new state-of-the-art among diffusion models, and approaches AR perplexity. We release our code at: https://github.com/kuleshov-group/mdlm
Read more6/12/2024
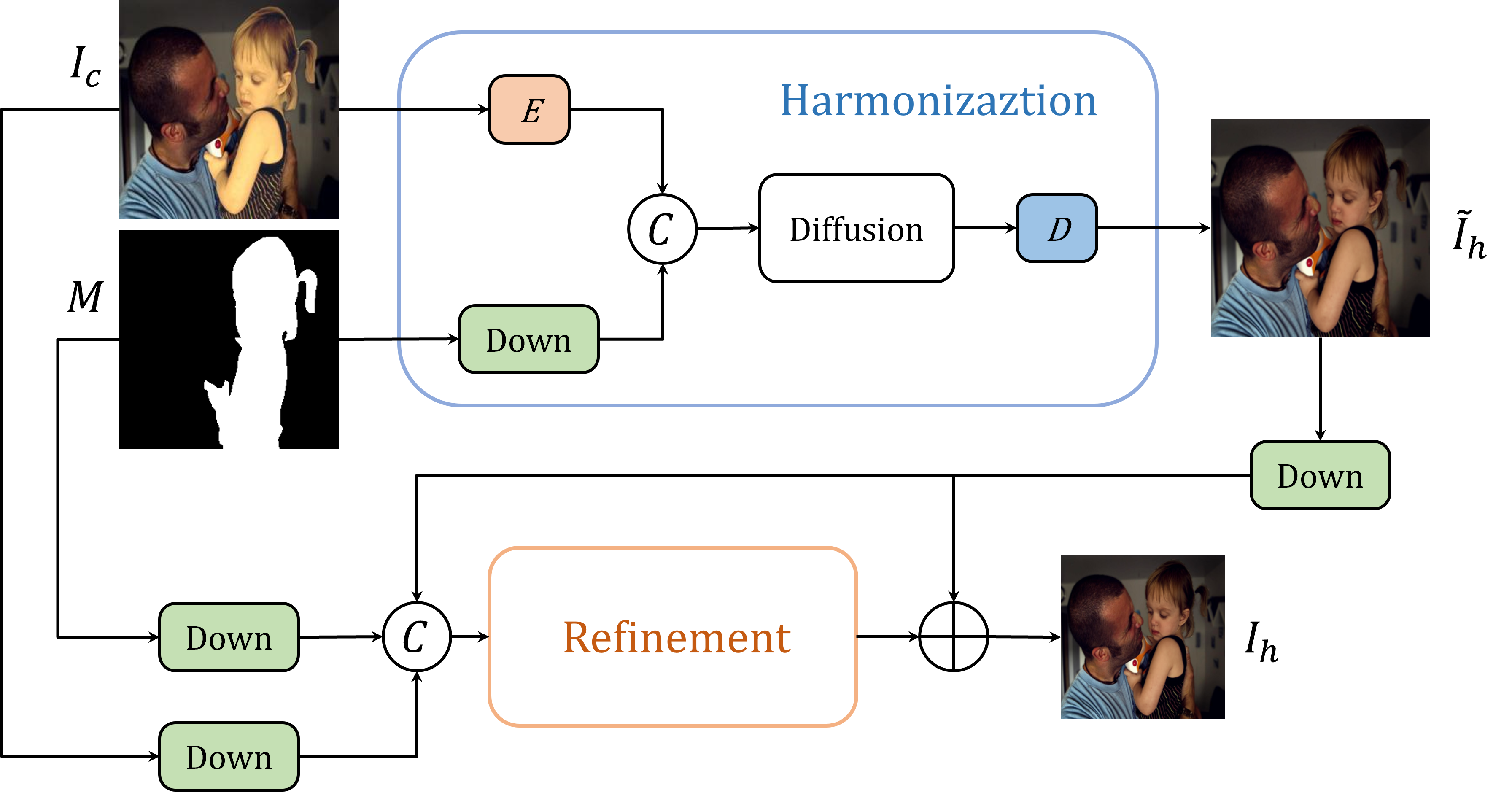
0
DiffHarmony: Latent Diffusion Model Meets Image Harmonization
Pengfei Zhou, Fangxiang Feng, Xiaojie Wang
Image harmonization, which involves adjusting the foreground of a composite image to attain a unified visual consistency with the background, can be conceptualized as an image-to-image translation task. Diffusion models have recently promoted the rapid development of image-to-image translation tasks . However, training diffusion models from scratch is computationally intensive. Fine-tuning pre-trained latent diffusion models entails dealing with the reconstruction error induced by the image compression autoencoder, making it unsuitable for image generation tasks that involve pixel-level evaluation metrics. To deal with these issues, in this paper, we first adapt a pre-trained latent diffusion model to the image harmonization task to generate the harmonious but potentially blurry initial images. Then we implement two strategies: utilizing higher-resolution images during inference and incorporating an additional refinement stage, to further enhance the clarity of the initially harmonized images. Extensive experiments on iHarmony4 datasets demonstrate the superiority of our proposed method. The code and model will be made publicly available at https://github.com/nicecv/DiffHarmony .
Read more4/10/2024