Simple and Effective Masked Diffusion Language Models
2406.07524
0
0
💬
Abstract
While diffusion models excel at generating high-quality images, prior work reports a significant performance gap between diffusion and autoregressive (AR) methods in language modeling. In this work, we show that simple masked discrete diffusion is more performant than previously thought. We apply an effective training recipe that improves the performance of masked diffusion models and derive a simplified, Rao-Blackwellized objective that results in additional improvements. Our objective has a simple form -- it is a mixture of classical masked language modeling losses -- and can be used to train encoder-only language models that admit efficient samplers, including ones that can generate arbitrary lengths of text semi-autoregressively like a traditional language model. On language modeling benchmarks, a range of masked diffusion models trained with modern engineering practices achieves a new state-of-the-art among diffusion models, and approaches AR perplexity. We release our code at: https://github.com/kuleshov-group/mdlm
Create account to get full access
Overview
- This paper introduces a new method for Simplified Generalized Masked Diffusion for Discrete Data, which aims to improve the performance of diffusion models on discrete data.
- The authors compare their method to existing approaches like LADIC and Masked Diffusion as Self-Supervised Representation Learner.
- They also explore ways to Improve Discrete Diffusion Models via Structured Preferential and Improve Conditional Diffusion Models with Kaleido Diffusion.
Plain English Explanation
Diffusion models are a type of machine learning algorithm that are good at generating new data samples that look similar to a set of training data. They work by gradually adding noise to the training data, then learning how to reverse the process and generate new samples.
However, diffusion models have historically struggled with discrete data, such as text or images with distinct pixel values. This paper proposes a new method called Simplified Generalized Masked Diffusion that helps diffusion models work better with discrete data.
The key idea is to mask out certain parts of the input data during training, forcing the model to learn how to "fill in the blanks" based on the surrounding context. This helps the model better understand the structure and relationships in the data, allowing it to generate more coherent and realistic samples.
The authors show that their approach outperforms previous methods on a variety of discrete data tasks, like language modeling and image generation. They also explore ways to further improve discrete diffusion models, such as incorporating structured preferences and combining them with autoregressive models.
Overall, this research represents an important step forward in making diffusion models more versatile and effective for working with discrete data, which has a wide range of real-world applications.
Technical Explanation
The paper introduces a new method called Simplified Generalized Masked Diffusion (SGMD) for training diffusion models on discrete data. The key innovation is the use of masking, where random parts of the input data are hidden during training.
The authors show that this masking process forces the diffusion model to learn the underlying structure and relationships in the data, rather than just memorizing the training samples. This allows the model to better generalize and generate more coherent and realistic samples, even for complex discrete data like text and images.
Experiments demonstrate that SGMD outperforms previous approaches like LADIC and Masked Diffusion as Self-Supervised Representation Learner on a variety of discrete data tasks. The authors also explore ways to further improve discrete diffusion models, such as Improving Discrete Diffusion Models via Structured Preferential and Improving Conditional Diffusion Models with Kaleido Diffusion.
Critical Analysis
The paper provides a solid technical contribution by introducing SGMD as a novel approach for training diffusion models on discrete data. The masking technique is a clever way to force the model to learn more meaningful representations, which is an important challenge in this domain.
However, the paper could have provided more discussion on the limitations and potential downsides of the SGMD method. For example, it's unclear how sensitive the approach is to the specific masking strategy used, or how the computational cost compares to other discrete diffusion techniques.
Additionally, while the results on benchmark tasks are promising, it would be helpful to see more analysis on the types of discrete data where SGMD shines versus other methods. A deeper examination of failure cases or areas for further improvement could also strengthen the critical evaluation.
Overall, this paper represents a valuable contribution to the field of diffusion models for discrete data, but there is still room for further research and refinement of the techniques introduced here.
Conclusion
This paper presents a novel method called Simplified Generalized Masked Diffusion (SGMD) that helps diffusion models work more effectively with discrete data such as text and images. By incorporating a masking strategy during training, the authors show that SGMD can outperform previous approaches on a variety of benchmarks.
The key insight is that masking forces the diffusion model to learn the underlying structure and relationships in the data, rather than just memorizing the training samples. This allows the model to generate more coherent and realistic outputs, even for complex discrete data.
The authors also explore complementary techniques like structured preferential learning and combining diffusion with autoregressive models to further improve the performance of discrete diffusion systems. While the paper leaves some avenues for future work, it represents an important advance in making diffusion models more versatile and effective for real-world applications involving discrete data.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Simplified and Generalized Masked Diffusion for Discrete Data
Jiaxin Shi, Kehang Han, Zhe Wang, Arnaud Doucet, Michalis K. Titsias
0
0
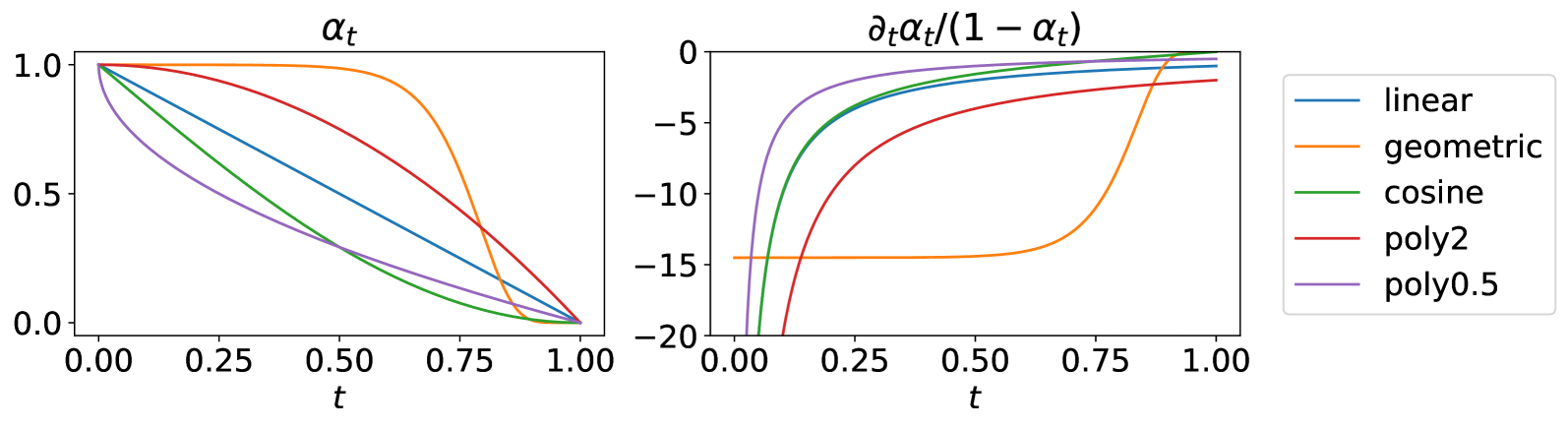
Masked (or absorbing) diffusion is actively explored as an alternative to autoregressive models for generative modeling of discrete data. However, existing work in this area has been hindered by unnecessarily complex model formulations and unclear relationships between different perspectives, leading to suboptimal parameterization, training objectives, and ad hoc adjustments to counteract these issues. In this work, we aim to provide a simple and general framework that unlocks the full potential of masked diffusion models. We show that the continuous-time variational objective of masked diffusion models is a simple weighted integral of cross-entropy losses. Our framework also enables training generalized masked diffusion models with state-dependent masking schedules. When evaluated by perplexity, our models trained on OpenWebText surpass prior diffusion language models at GPT-2 scale and demonstrate superior performance on 4 out of 5 zero-shot language modeling tasks. Furthermore, our models vastly outperform previous discrete diffusion models on pixel-level image modeling, achieving 2.78~(CIFAR-10) and 3.42 (ImageNet 64$times$64) bits per dimension that are comparable or better than autoregressive models of similar sizes.
6/7/2024

LaDiC: Are Diffusion Models Really Inferior to Autoregressive Counterparts for Image-to-Text Generation?
Yuchi Wang, Shuhuai Ren, Rundong Gao, Linli Yao, Qingyan Guo, Kaikai An, Jianhong Bai, Xu Sun
0
0
Diffusion models have exhibited remarkable capabilities in text-to-image generation. However, their performance in image-to-text generation, specifically image captioning, has lagged behind Auto-Regressive (AR) models, casting doubt on their applicability for such tasks. In this work, we revisit diffusion models, highlighting their capacity for holistic context modeling and parallel decoding. With these benefits, diffusion models can alleviate the inherent limitations of AR methods, including their slow inference speed, error propagation, and unidirectional constraints. Furthermore, we identify the prior underperformance of diffusion models stemming from the absence of an effective latent space for image-text alignment, and the discrepancy between continuous diffusion processes and discrete textual data. In response, we introduce a novel architecture, LaDiC, which utilizes a split BERT to create a dedicated latent space for captions and integrates a regularization module to manage varying text lengths. Our framework also includes a diffuser for semantic image-to-text conversion and a Back&Refine technique to enhance token interactivity during inference. LaDiC achieves state-of-the-art performance for diffusion-based methods on the MS COCO dataset with 38.2 BLEU@4 and 126.2 CIDEr, demonstrating exceptional performance without pre-training or ancillary modules. This indicates strong competitiveness with AR models, revealing the previously untapped potential of diffusion models in image-to-text generation.
4/17/2024
➖
Masked Diffusion as Self-supervised Representation Learner
Zixuan Pan, Jianxu Chen, Yiyu Shi
0
0
Denoising diffusion probabilistic models have recently demonstrated state-of-the-art generative performance and have been used as strong pixel-level representation learners. This paper decomposes the interrelation between the generative capability and representation learning ability inherent in diffusion models. We present the masked diffusion model (MDM), a scalable self-supervised representation learner for semantic segmentation, substituting the conventional additive Gaussian noise of traditional diffusion with a masking mechanism. Our proposed approach convincingly surpasses prior benchmarks, demonstrating remarkable advancements in both medical and natural image semantic segmentation tasks, particularly in few-shot scenarios.
4/16/2024
Promises, Outlooks and Challenges of Diffusion Language Modeling
Justin Deschenaux, Caglar Gulcehre
0
0
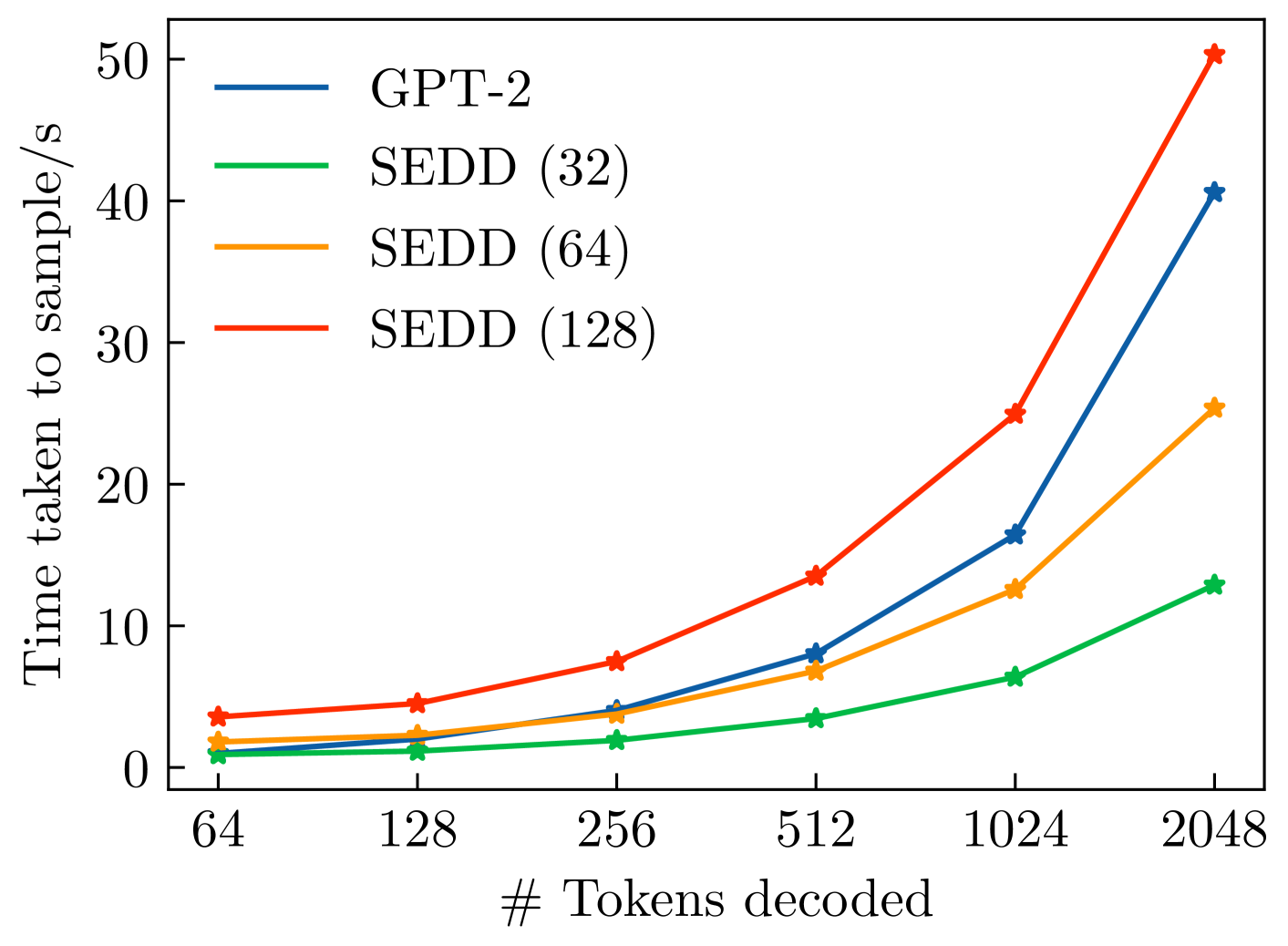
The modern autoregressive Large Language Models (LLMs) have achieved outstanding performance on NLP benchmarks, and they are deployed in the real world. However, they still suffer from limitations of the autoregressive training paradigm. For example, autoregressive token generation is notably slow and can be prone to textit{exposure bias}. The diffusion-based language models were proposed as an alternative to autoregressive generation to address some of these limitations. We evaluate the recently proposed Score Entropy Discrete Diffusion (SEDD) approach and show it is a promising alternative to autoregressive generation but it has some short-comings too. We empirically demonstrate the advantages and challenges of SEDD, and observe that SEDD generally matches autoregressive models in perplexity and on benchmarks such as HellaSwag, Arc or WinoGrande. Additionally, we show that in terms of inference latency, SEDD can be up to 4.5$times$ more efficient than GPT-2. While SEDD allows conditioning on tokens at abitrary positions, SEDD appears slightly weaker than GPT-2 for conditional generation given short prompts. Finally, we reproduced the main results from the original SEDD paper.
6/18/2024