Measuring Catastrophic Forgetting in Cross-Lingual Transfer Paradigms: Exploring Tuning Strategies
2309.06089
0
0
🔄
Abstract
The cross-lingual transfer is a promising technique to solve tasks in less-resourced languages. In this empirical study, we compare two fine-tuning approaches combined with zero-shot and full-shot learning approaches for large language models in a cross-lingual setting. As fine-tuning strategies, we compare parameter-efficient adapter methods with fine-tuning of all parameters. As cross-lingual transfer strategies, we compare the intermediate-training (textit{IT}) that uses each language sequentially and cross-lingual validation (textit{CLV}) that uses a target language already in the validation phase of fine-tuning. We assess the success of transfer and the extent of catastrophic forgetting in a source language due to cross-lingual transfer, i.e., how much previously acquired knowledge is lost when we learn new information in a different language. The results on two different classification problems, hate speech detection and product reviews, each containing datasets in several languages, show that the textit{IT} cross-lingual strategy outperforms textit{CLV} for the target language. Our findings indicate that, in the majority of cases, the textit{CLV} strategy demonstrates superior retention of knowledge in the base language (English) compared to the textit{IT} strategy, when evaluating catastrophic forgetting in multiple cross-lingual transfers.
Create account to get full access
Overview
- This paper compares two fine-tuning approaches combined with zero-shot and full-shot learning for large language models in a cross-lingual setting.
- The researchers investigate cross-lingual transfer, a promising technique to solve tasks in less-resourced languages.
- They assess the success of transfer and the extent of catastrophic forgetting in a source language due to cross-lingual transfer.
Plain English Explanation
The paper explores a technique called cross-lingual transfer that aims to solve tasks in languages with limited data by using information from a language with more resources, like English. The researchers compare two ways of fine-tuning large language models for this cross-lingual setting:
- Using parameter-efficient adapters
- Fine-tuning all model parameters
They also compare two cross-lingual transfer strategies:
- Intermediate Training (IT), which trains on each language sequentially
- Cross-Lingual Validation (CLV), which uses the target language during the fine-tuning process
The key question is how well these approaches work for tasks like hate speech detection and product reviews in multiple languages. The researchers also look at how much previously learned information is forgotten (catastrophic forgetting) when the model learns new languages.
Technical Explanation
The paper compares two fine-tuning approaches for large language models in a cross-lingual setting:
- Parameter-Efficient Adapters: Only a small number of model parameters are fine-tuned, which can be more efficient than fine-tuning all parameters.
- Full Fine-Tuning: All model parameters are fine-tuned on the target task and language.
For cross-lingual transfer, the researchers evaluate two strategies:
- Intermediate Training (IT): The model is fine-tuned on each language sequentially.
- Cross-Lingual Validation (CLV): The target language is used during the fine-tuning process, even though the final evaluation is on a held-out test set.
The experiments are conducted on two different classification tasks - hate speech detection and product reviews - with datasets in multiple languages. The researchers assess the performance on the target language as well as the extent of catastrophic forgetting in the source language (English).
Critical Analysis
The paper provides a thorough empirical evaluation of cross-lingual transfer strategies for large language models. The researchers acknowledge that the success of these approaches may depend on the specific task and language pair, and encourage further exploration of cross-lingual transfer in other domains.
One potential limitation is that the experiments only consider a relatively small number of languages. Expanding the evaluation to a wider range of languages, especially those with fewer resources, could provide additional insights. Additionally, the paper does not delve into the underlying reasons for the observed differences in performance and catastrophic forgetting between the IT and CLV strategies, which would be an interesting area for further research.
Overall, the paper offers a valuable contribution to the understanding of cross-lingual transfer learning and highlights the importance of carefully considering fine-tuning and transfer strategies when working with multilingual language models.
Conclusion
This study compares different fine-tuning and cross-lingual transfer approaches for large language models, with a focus on understanding the trade-offs between target language performance and the retention of knowledge in the source language. The results suggest that the Intermediate Training (IT) strategy generally outperforms Cross-Lingual Validation (CLV) for the target language, but the CLV approach demonstrates better preservation of knowledge in the source language. These insights can help inform the development of more effective and efficient cross-lingual transfer learning systems, which are crucial for expanding the reach of language technologies to underserved languages.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
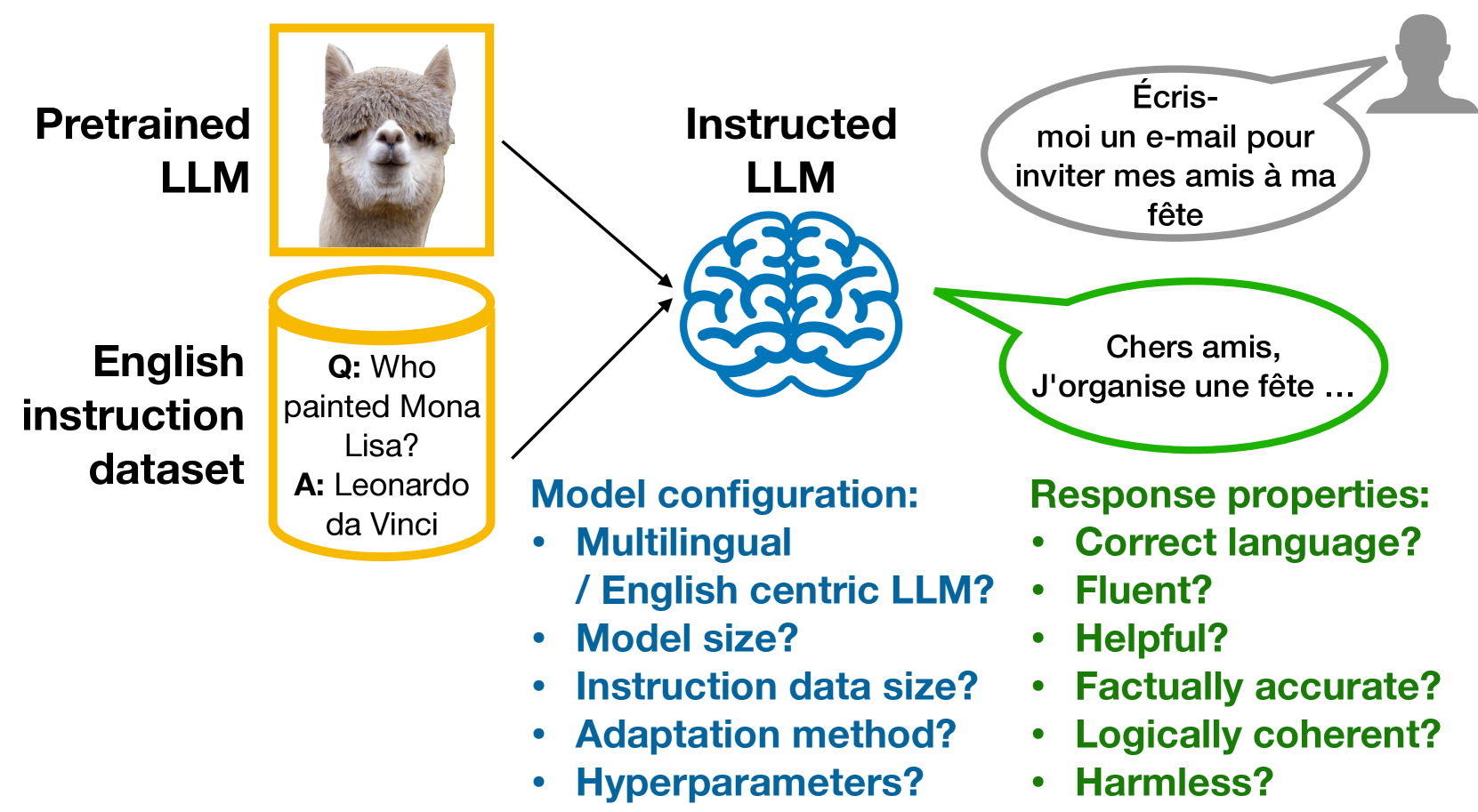
Zero-shot cross-lingual transfer in instruction tuning of large language models
Nadezhda Chirkova, Vassilina Nikoulina
0
0
Instruction tuning (IT) is widely used to teach pretrained large language models (LLMs) to follow arbitrary instructions, but is under-studied in multilingual settings. In this work, we conduct a systematic study of zero-shot cross-lingual transfer in IT, when an LLM is instruction-tuned on English-only data and then tested on user prompts in other languages. We advocate for the importance of evaluating various aspects of model responses in multilingual instruction following and investigate the influence of different model configuration choices. We find that cross-lingual transfer does happen successfully in IT even if all stages of model training are English-centric, but only if multiliguality is taken into account in hyperparameter tuning and with large enough IT data. English-trained LLMs are capable of generating correct-language, comprehensive and helpful responses in other languages, but suffer from low factuality and may occasionally have fluency errors.
4/23/2024
💬
An Empirical Study of Catastrophic Forgetting in Large Language Models During Continual Fine-tuning
Yun Luo, Zhen Yang, Fandong Meng, Yafu Li, Jie Zhou, Yue Zhang
0
0
Catastrophic forgetting (CF) is a phenomenon that occurs in machine learning when a model forgets previously learned information while acquiring new knowledge. As large language models (LLMs) have demonstrated remarkable performance, it is intriguing to investigate whether CF exists during the continual instruction tuning of LLMs. This study empirically evaluates the forgetting phenomenon in LLMs' knowledge during continual instruction tuning from the perspectives of domain knowledge, reasoning, and reading comprehension. The experiments reveal that catastrophic forgetting is generally observed in LLMs ranging from 1b to 7b parameters. Moreover, as the model scale increases, the severity of forgetting intensifies. Comparing the decoder-only model BLOOMZ with the encoder-decoder model mT0, BLOOMZ exhibits less forgetting and retains more knowledge. Interestingly, we also observe that LLMs can mitigate language biases, such as gender bias, during continual fine-tuning. Furthermore, our findings indicate that ALPACA maintains more knowledge and capacity compared to LLAMA during continual fine-tuning, suggesting that general instruction tuning can help alleviate the forgetting phenomenon in LLMs during subsequent fine-tuning processes.
4/3/2024
🔄
Measuring Cross-lingual Transfer in Bytes
Leandro Rodrigues de Souza, Thales Sales Almeida, Roberto Lotufo, Rodrigo Nogueira
0
0
Multilingual pretraining has been a successful solution to the challenges posed by the lack of resources for languages. These models can transfer knowledge to target languages with minimal or no examples. Recent research suggests that monolingual models also have a similar capability, but the mechanisms behind this transfer remain unclear. Some studies have explored factors like language contamination and syntactic similarity. An emerging line of research suggests that the representations learned by language models contain two components: a language-specific and a language-agnostic component. The latter is responsible for transferring a more universal knowledge. However, there is a lack of comprehensive exploration of these properties across diverse target languages. To investigate this hypothesis, we conducted an experiment inspired by the work on the Scaling Laws for Transfer. We measured the amount of data transferred from a source language to a target language and found that models initialized from diverse languages perform similarly to a target language in a cross-lingual setting. This was surprising because the amount of data transferred to 10 diverse target languages, such as Spanish, Korean, and Finnish, was quite similar. We also found evidence that this transfer is not related to language contamination or language proximity, which strengthens the hypothesis that the model also relies on language-agnostic knowledge. Our experiments have opened up new possibilities for measuring how much data represents the language-agnostic representations learned during pretraining.
4/15/2024
🔄
Key ingredients for effective zero-shot cross-lingual knowledge transfer in generative tasks
Nadezhda Chirkova, Vassilina Nikoulina
0
0
Zero-shot cross-lingual knowledge transfer enables a multilingual pretrained language model, finetuned on a task in one language, make predictions for this task in other languages. While being broadly studied for natural language understanding tasks, the described setting is understudied for generation. Previous works notice a frequent problem of generation in a wrong language and propose approaches to address it, usually using mT5 as a backbone model. In this work we compare various approaches proposed from the literature in unified settings, also including alternative backbone models, namely mBART and NLLB-200. We first underline the importance of tuning learning rate used for finetuning, which helps to substantially alleviate the problem of generation in the wrong language. Then, we show that with careful learning rate tuning, the simple full finetuning of the model acts as a very strong baseline and alternative approaches bring only marginal improvements. Finally, we find that mBART performs similarly to mT5 of the same size, and NLLB-200 can be competitive in some cases. Our final zero-shot models reach the performance of the approach based on data translation which is usually considered as an upper baseline for zero-shot cross-lingual transfer in generation.
4/23/2024