SciKnowEval: Evaluating Multi-level Scientific Knowledge of Large Language Models
2406.09098
0
0

Abstract
The burgeoning utilization of Large Language Models (LLMs) in scientific research necessitates advanced benchmarks capable of evaluating their understanding and application of scientific knowledge comprehensively. To address this need, we introduce the SciKnowEval benchmark, a novel framework that systematically evaluates LLMs across five progressive levels of scientific knowledge: studying extensively, inquiring earnestly, thinking profoundly, discerning clearly, and practicing assiduously. These levels aim to assess the breadth and depth of scientific knowledge in LLMs, including knowledge coverage, inquiry and exploration capabilities, reflection and reasoning abilities, ethic and safety considerations, as well as practice proficiency. Specifically, we take biology and chemistry as the two instances of SciKnowEval and construct a dataset encompassing 50K multi-level scientific problems and solutions. By leveraging this dataset, we benchmark 20 leading open-source and proprietary LLMs using zero-shot and few-shot prompting strategies. The results reveal that despite achieving state-of-the-art performance, the proprietary LLMs still have considerable room for improvement, particularly in addressing scientific computations and applications. We anticipate that SciKnowEval will establish a comprehensive standard for benchmarking LLMs in science research and discovery, and promote the development of LLMs that integrate scientific knowledge with strong safety awareness. The dataset and code are publicly available at https://github.com/hicai-zju/sciknoweval .
Create account to get full access
Overview
- This paper introduces SciKnowEval, a framework for evaluating the scientific knowledge capabilities of large language models (LLMs) across multiple levels.
- The framework assesses an LLM's ability to understand, reason about, and apply scientific concepts, processes, and terminology.
- SciKnowEval includes various tasks and datasets to probe an LLM's scientific knowledge, from basic factual knowledge to complex reasoning and problem-solving.
- The authors evaluate several state-of-the-art LLMs using SciKnowEval, providing insights into the strengths and limitations of these models' scientific understanding.
Plain English Explanation
The paper introduces a new way to test how well large AI language models, like GPT-3 or BERT, understand and work with scientific information. The researchers created a framework called SciKnowEval that includes different tasks and datasets to assess an AI model's scientific knowledge at various levels.
For example, the framework might test if a model can correctly answer factual questions about scientific concepts, or if it can understand and apply scientific processes and terminology. The goal is to go beyond just evaluating how well the model can recall facts, and also see if it can reason about and use scientific information in more complex ways.
The authors tested several top AI language models using SciKnowEval, and the results provide insights into the strengths and weaknesses of these models when it comes to scientific understanding. This could help researchers and developers improve the scientific capabilities of large language models in the future.
Technical Explanation
The paper introduces the SciKnowEval framework, which is designed to comprehensively evaluate the scientific knowledge capabilities of large language models (LLMs). SciKnowEval includes a suite of tasks and datasets that assess an LLM's understanding of scientific concepts, processes, and terminology at multiple levels.
The framework spans tasks ranging from basic factual knowledge to complex reasoning and problem-solving. This allows the authors to probe an LLM's scientific knowledge from various angles, going beyond simple recall to evaluate deeper comprehension and application of scientific principles.
The authors evaluate several state-of-the-art LLMs using SciKnowEval, including GPT-3, BERT, and others. The results provide insights into the strengths and limitations of these models when it comes to scientific understanding, as highlighted by recent research on the challenges of evaluating LLMs' capabilities.
Critical Analysis
The paper presents a well-designed framework for evaluating scientific knowledge in LLMs, addressing important limitations of existing benchmarks. By assessing multiple levels of understanding, from factual recall to reasoning and problem-solving, SciKnowEval provides a more comprehensive view of an LLM's scientific capabilities.
However, the authors acknowledge that the framework has room for further expansion and refinement. Specifically, they note that the current tasks and datasets may not fully capture the nuances of scientific knowledge, and that additional domains or task types could be added to enhance the evaluation. There is also the potential for biases and inconsistencies in the evaluation process that should be considered.
Additionally, while the paper provides valuable insights into the state of scientific knowledge in LLMs, it does not delve into the potential reasons behind the observed strengths and limitations. Further research could explore the architectural choices, training data, and other factors that contribute to an LLM's scientific understanding.
Conclusion
The SciKnowEval framework introduced in this paper represents an important step forward in evaluating the scientific knowledge capabilities of large language models. By assessing multiple levels of understanding, the framework offers a more comprehensive and nuanced assessment than previous benchmarks.
The results of the author's evaluation provide valuable insights into the current state of scientific knowledge in state-of-the-art LLMs, highlighting both their strengths and limitations. This information can inform future research and development efforts aimed at improving the scientific reasoning and problem-solving abilities of these powerful language models.
As the field of AI continues to advance, tools like SciKnowEval will be crucial for ensuring that language models can effectively engage with and apply scientific knowledge to tackle complex real-world challenges.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
SciAssess: Benchmarking LLM Proficiency in Scientific Literature Analysis
Hengxing Cai, Xiaochen Cai, Junhan Chang, Sihang Li, Lin Yao, Changxin Wang, Zhifeng Gao, Hongshuai Wang, Yongge Li, Mujie Lin, Shuwen Yang, Jiankun Wang, Mingjun Xu, Jin Huang, Fang Xi, Jiaxi Zhuang, Yuqi Yin, Yaqi Li, Changhong Chen, Zheng Cheng, Zifeng Zhao, Linfeng Zhang, Guolin Ke
0
0
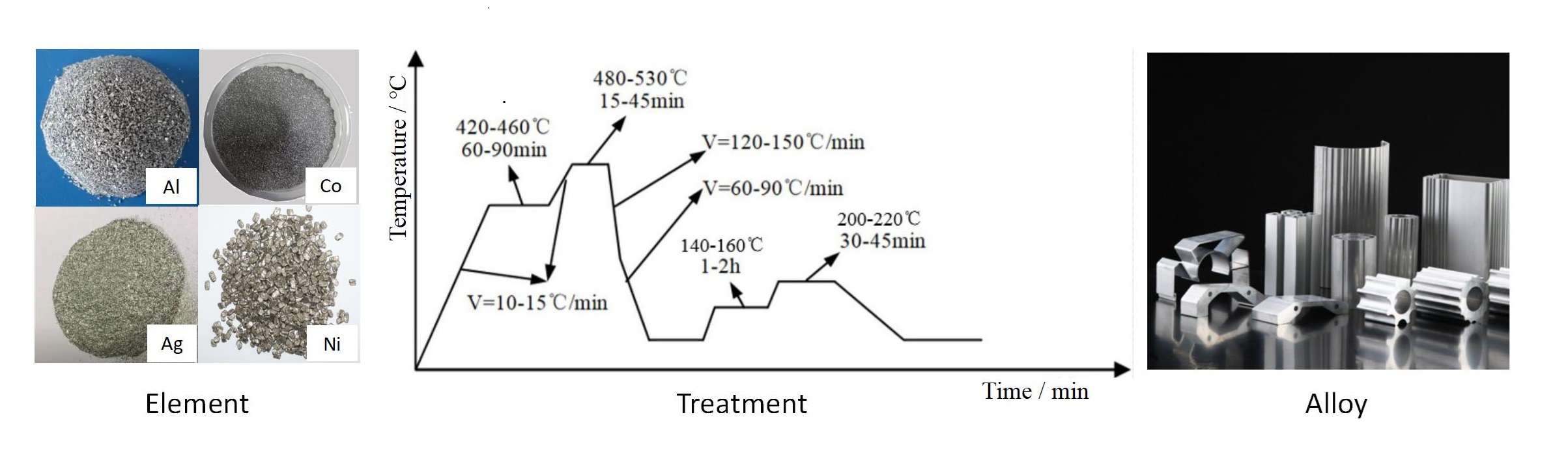
Recent breakthroughs in Large Language Models (LLMs) have revolutionized natural language understanding and generation, sparking significant interest in applying them to scientific literature analysis. However, existing benchmarks fail to adequately evaluate the proficiency of LLMs in this domain, particularly in scenarios requiring higher-level abilities beyond mere memorization and the handling of multimodal data. In response to this gap, we introduce SciAssess, a benchmark specifically designed for the comprehensive evaluation of LLMs in scientific literature analysis. SciAssess aims to thoroughly assess the efficacy of LLMs by focusing on their capabilities in Memorization (L1), Comprehension (L2), and Analysis & Reasoning (L3). It encompasses a variety of tasks drawn from diverse scientific fields, including fundamental science, alloy materials, biomedicine, drug discovery, and organic materials. To ensure the reliability of SciAssess, rigorous quality control measures have been implemented, ensuring accuracy, anonymization, and compliance with copyright standards. SciAssess evaluates 11 LLMs, including GPT, Claude, and Gemini, highlighting their strengths and areas for improvement. This evaluation supports the ongoing development of LLM applications in the analysis of scientific literature. SciAssess and its resources are available at url{https://sci-assess.github.io/}.
6/19/2024
💬
New!SciBench: Evaluating College-Level Scientific Problem-Solving Abilities of Large Language Models
Xiaoxuan Wang, Ziniu Hu, Pan Lu, Yanqiao Zhu, Jieyu Zhang, Satyen Subramaniam, Arjun R. Loomba, Shichang Zhang, Yizhou Sun, Wei Wang
0
0
Most of the existing Large Language Model (LLM) benchmarks on scientific problem reasoning focus on problems grounded in high-school subjects and are confined to elementary algebraic operations. To systematically examine the reasoning capabilities required for solving complex scientific problems, we introduce an expansive benchmark suite SciBench for LLMs. SciBench contains a carefully curated dataset featuring a range of collegiate-level scientific problems from mathematics, chemistry, and physics domains. Based on the dataset, we conduct an in-depth benchmarking study of representative open-source and proprietary LLMs with various prompting strategies. The results reveal that the current LLMs fall short of delivering satisfactory performance, with the best overall score of merely 43.22%. Furthermore, through a detailed user study, we categorize the errors made by LLMs into ten problem-solving abilities. Our analysis indicates that no single prompting strategy significantly outperforms the others and some strategies that demonstrate improvements in certain problem-solving skills could result in declines in other skills. We envision that SciBench will catalyze further developments in the reasoning abilities of LLMs, thereby ultimately contributing to scientific research and discovery.
7/1/2024
KIEval: A Knowledge-grounded Interactive Evaluation Framework for Large Language Models
Zhuohao Yu, Chang Gao, Wenjin Yao, Yidong Wang, Wei Ye, Jindong Wang, Xing Xie, Yue Zhang, Shikun Zhang
0
0
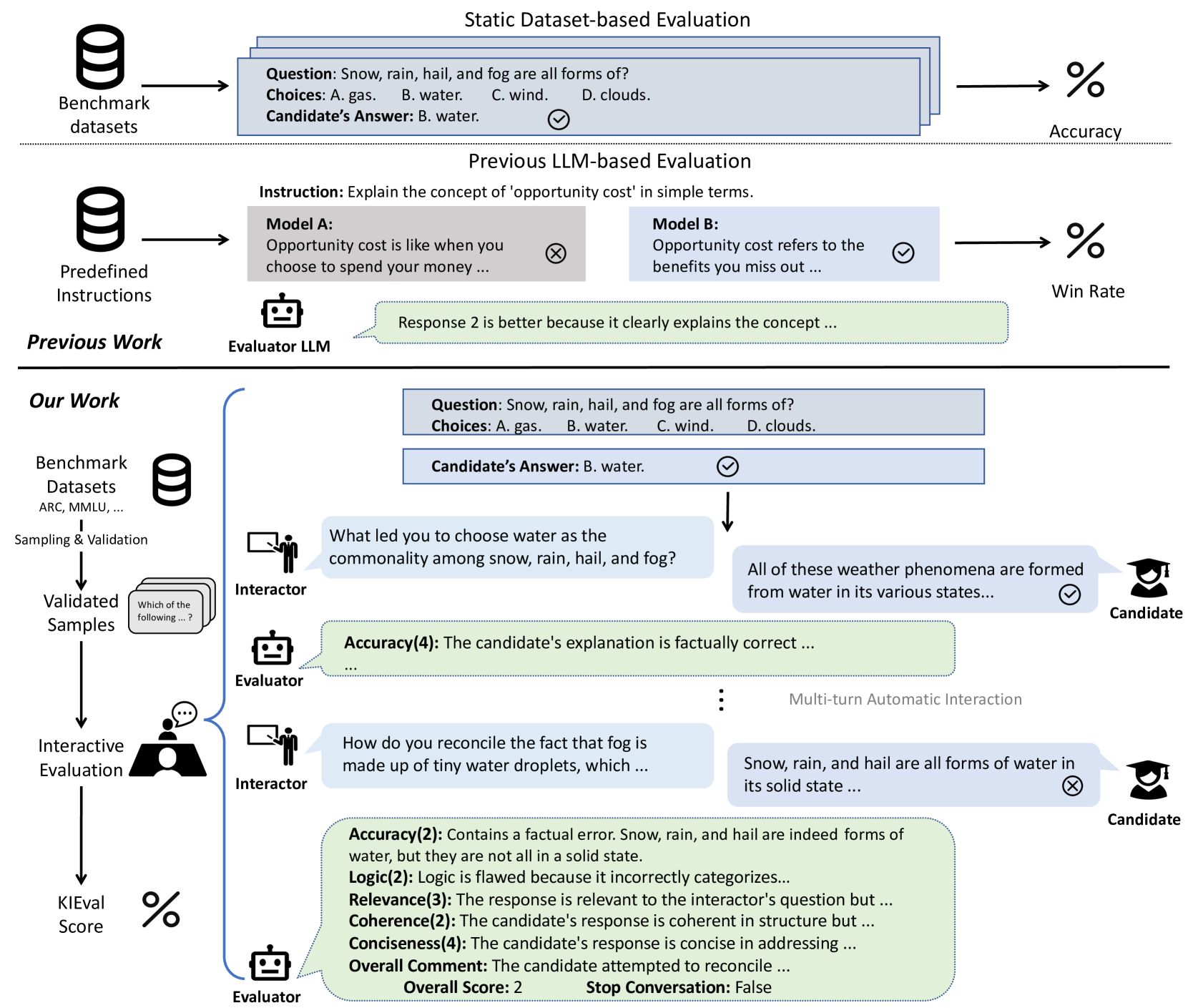
Automatic evaluation methods for large language models (LLMs) are hindered by data contamination, leading to inflated assessments of their effectiveness. Existing strategies, which aim to detect contaminated texts, focus on quantifying contamination status instead of accurately gauging model performance. In this paper, we introduce KIEval, a Knowledge-grounded Interactive Evaluation framework, which incorporates an LLM-powered interactor role for the first time to accomplish a dynamic contamination-resilient evaluation. Starting with a question in a conventional LLM benchmark involving domain-specific knowledge, KIEval utilizes dynamically generated, multi-round, and knowledge-focused dialogues to determine whether a model's response is merely a recall of benchmark answers or demonstrates a deep comprehension to apply knowledge in more complex conversations. Extensive experiments on seven leading LLMs across five datasets validate KIEval's effectiveness and generalization. We also reveal that data contamination brings no contribution or even negative effect to models' real-world applicability and understanding, and existing contamination detection methods for LLMs can only identify contamination in pre-training but not during supervised fine-tuning.
6/4/2024
💬
New!KoLA: Carefully Benchmarking World Knowledge of Large Language Models
Jifan Yu, Xiaozhi Wang, Shangqing Tu, Shulin Cao, Daniel Zhang-Li, Xin Lv, Hao Peng, Zijun Yao, Xiaohan Zhang, Hanming Li, Chunyang Li, Zheyuan Zhang, Yushi Bai, Yantao Liu, Amy Xin, Nianyi Lin, Kaifeng Yun, Linlu Gong, Jianhui Chen, Zhili Wu, Yunjia Qi, Weikai Li, Yong Guan, Kaisheng Zeng, Ji Qi, Hailong Jin, Jinxin Liu, Yu Gu, Yuan Yao, Ning Ding, Lei Hou, Zhiyuan Liu, Bin Xu, Jie Tang, Juanzi Li
0
0
The unprecedented performance of large language models (LLMs) necessitates improvements in evaluations. Rather than merely exploring the breadth of LLM abilities, we believe meticulous and thoughtful designs are essential to thorough, unbiased, and applicable evaluations. Given the importance of world knowledge to LLMs, we construct a Knowledge-oriented LLM Assessment benchmark (KoLA), in which we carefully design three crucial factors: (1) For textbf{ability modeling}, we mimic human cognition to form a four-level taxonomy of knowledge-related abilities, covering $19$ tasks. (2) For textbf{data}, to ensure fair comparisons, we use both Wikipedia, a corpus prevalently pre-trained by LLMs, along with continuously collected emerging corpora, aiming to evaluate the capacity to handle unseen data and evolving knowledge. (3) For textbf{evaluation criteria}, we adopt a contrastive system, including overall standard scores for better numerical comparability across tasks and models and a unique self-contrast metric for automatically evaluating knowledge-creating ability. We evaluate $28$ open-source and commercial LLMs and obtain some intriguing findings. The KoLA dataset and open-participation leaderboard are publicly released at https://kola.xlore.cn and will be continuously updated to provide references for developing LLMs and knowledge-related systems.
7/2/2024