A KL-based Analysis Framework with Applications to Non-Descent Optimization Methods

0
🛠️
Sign in to get full access
Overview
- This paper proposes a new analysis framework based on Kullback-Leibler (KL) divergence for studying the convergence properties of non-descent optimization methods.
- The framework is applied to analyze the convergence of several non-descent algorithms, including Developing Lagrangian-Based Methods for Nonsmooth Nonconvex Optimization, Learning to Optimize with Convergence Guarantees using Nonlinear Dynamics, Convergence of SGD and Momentum in the Nonconvex Case: A Novel Time-Varying Analysis, and Mean-Field Analysis of Neural Stochastic Gradient Descent.
- The KL-based framework provides a unified way to analyze the convergence of these diverse non-descent optimization methods.
Plain English Explanation
The paper introduces a new way to analyze the convergence, or how quickly an optimization algorithm reaches the best solution, for a class of optimization methods that do not rely on descending down the gradient of the objective function. This is important because many modern optimization algorithms, such as those used in machine learning, do not follow this traditional descent-based approach.
The key idea is to use a mathematical concept called Kullback-Leibler (KL) divergence to quantify the difference between the current state of the optimization process and the optimal solution. By tracking how this KL divergence changes over time, the researchers can understand the convergence properties of the algorithm.
The paper then applies this KL-based analysis framework to several specific non-descent optimization methods, providing a unified way to study their convergence guarantees. This allows the researchers to compare the strengths and weaknesses of these different algorithms in a systematic way.
Technical Explanation
The paper proposes a new analysis framework based on Kullback-Leibler (KL) divergence to study the convergence properties of non-descent optimization methods. KL divergence is used to measure the difference between the current state of the optimization process and the optimal solution.
The framework is applied to analyze the convergence of several non-descent algorithms, including Developing Lagrangian-Based Methods for Nonsmooth Nonconvex Optimization, Learning to Optimize with Convergence Guarantees using Nonlinear Dynamics, Convergence of SGD and Momentum in the Nonconvex Case: A Novel Time-Varying Analysis, and Mean-Field Analysis of Neural Stochastic Gradient Descent. The KL-based framework provides a unified way to analyze the convergence of these diverse non-descent optimization methods.
Critical Analysis
The paper introduces a novel analysis framework that provides a principled way to study the convergence of a wide range of non-descent optimization methods. This is an important contribution, as many modern optimization algorithms, particularly in machine learning, do not follow the traditional gradient descent approach.
However, the paper does not address the potential limitations of the KL-based analysis framework. For example, it's unclear how the framework would perform in the presence of noise or when the objective function is highly non-convex. Additionally, the paper does not explore the computational complexity of applying the framework to large-scale optimization problems.
Further research could investigate the robustness of the KL-based analysis under different conditions and explore ways to make the framework more scalable and efficient. Comparing the KL-based approach to other convergence analysis techniques would also help to better understand its strengths and weaknesses.
Conclusion
This paper presents a new Kullback-Leibler (KL) divergence-based analysis framework for studying the convergence properties of non-descent optimization methods. The framework is applied to several specific algorithms, providing a unified way to analyze their convergence guarantees.
The KL-based approach offers a principled way to understand the behavior of optimization methods that do not rely on gradient descent, which is an important class of algorithms in modern machine learning and optimization. While the paper demonstrates the utility of this framework, further research is needed to explore its limitations and potential extensions.
Overall, this work represents a significant contribution to the field of optimization, as it provides a new analytical tool for studying the convergence of a wide range of non-descent algorithms.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🛠️
0
A KL-based Analysis Framework with Applications to Non-Descent Optimization Methods
Junwen Qiu, Bohao Ma, Xiao Li, Andre Milzarek
We propose a novel analysis framework for non-descent-type optimization methodologies in nonconvex scenarios based on the Kurdyka-Lojasiewicz property. Our framework allows covering a broad class of algorithms, including those commonly employed in stochastic and distributed optimization. Specifically, it enables the analysis of first-order methods that lack a sufficient descent property and do not require access to full (deterministic) gradient information. We leverage this framework to establish, for the first time, iterate convergence and the corresponding rates for the decentralized gradient method and federated averaging under mild assumptions. Furthermore, based on the new analysis techniques, we show the convergence of the random reshuffling and stochastic gradient descent method without necessitating typical a priori bounded iterates assumptions.
Read more6/5/2024
0
Decentralized Stochastic Subgradient Methods for Nonsmooth Nonconvex Optimization
Siyuan Zhang, Nachuan Xiao, Xin Liu
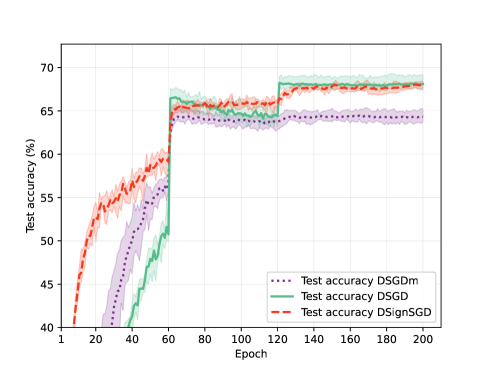
In this paper, we concentrate on decentralized optimization problems with nonconvex and nonsmooth objective functions, especially on the decentralized training of nonsmooth neural networks. We introduce a unified framework to analyze the global convergence of decentralized stochastic subgradient-based methods. We prove the global convergence of our proposed framework under mild conditions, by establishing that the generated sequence asymptotically approximates the trajectories of its associated differential inclusion. Furthermore, we establish that our proposed framework covers a wide range of existing efficient decentralized subgradient-based methods, including decentralized stochastic subgradient descent (DSGD), DSGD with gradient-tracking technique (DSGD-T), and DSGD with momentum (DSGD-M). In addition, we introduce the sign map to regularize the update directions in DSGD-M, and show it is enclosed in our proposed framework. Consequently, our convergence results establish, for the first time, global convergence of these methods when applied to nonsmooth nonconvex objectives. Preliminary numerical experiments demonstrate that our proposed framework yields highly efficient decentralized subgradient-based methods with convergence guarantees in the training of nonsmooth neural networks.
Read more6/28/2024

0
Developing Lagrangian-based Methods for Nonsmooth Nonconvex Optimization
Nachuan Xiao, Kuangyu Ding, Xiaoyin Hu, Kim-Chuan Toh
In this paper, we consider the minimization of a nonsmooth nonconvex objective function $f(x)$ over a closed convex subset $mathcal{X}$ of $mathbb{R}^n$, with additional nonsmooth nonconvex constraints $c(x) = 0$. We develop a unified framework for developing Lagrangian-based methods, which takes a single-step update to the primal variables by some subgradient methods in each iteration. These subgradient methods are ``embedded'' into our framework, in the sense that they are incorporated as black-box updates to the primal variables. We prove that our proposed framework inherits the global convergence guarantees from these embedded subgradient methods under mild conditions. In addition, we show that our framework can be extended to solve constrained optimization problems with expectation constraints. Based on the proposed framework, we show that a wide range of existing stochastic subgradient methods, including the proximal SGD, proximal momentum SGD, and proximal ADAM, can be embedded into Lagrangian-based methods. Preliminary numerical experiments on deep learning tasks illustrate that our proposed framework yields efficient variants of Lagrangian-based methods with convergence guarantees for nonconvex nonsmooth constrained optimization problems.
Read more4/16/2024

1
An Adaptive Stochastic Gradient Method with Non-negative Gauss-Newton Stepsizes
Antonio Orvieto, Lin Xiao
We consider the problem of minimizing the average of a large number of smooth but possibly non-convex functions. In the context of most machine learning applications, each loss function is non-negative and thus can be expressed as the composition of a square and its real-valued square root. This reformulation allows us to apply the Gauss-Newton method, or the Levenberg-Marquardt method when adding a quadratic regularization. The resulting algorithm, while being computationally as efficient as the vanilla stochastic gradient method, is highly adaptive and can automatically warmup and decay the effective stepsize while tracking the non-negative loss landscape. We provide a tight convergence analysis, leveraging new techniques, in the stochastic convex and non-convex settings. In particular, in the convex case, the method does not require access to the gradient Lipshitz constant for convergence, and is guaranteed to never diverge. The convergence rates and empirical evaluations compare favorably to the classical (stochastic) gradient method as well as to several other adaptive methods.
Read more7/8/2024