Knowledge Transfer with Simulated Inter-Image Erasing for Weakly Supervised Semantic Segmentation

0
Sign in to get full access
Overview
- This paper introduces a novel approach for weakly supervised semantic segmentation, which aims to train a semantic segmentation model using only image-level labels instead of pixel-level annotations.
- The key idea is to leverage knowledge transfer from a strongly supervised model by simulating inter-image erasing during training, which helps the model learn to focus on the most discriminative features.
- The proposed method achieves state-of-the-art performance on several weakly supervised semantic segmentation benchmarks.
Plain English Explanation
Semantic segmentation is the task of assigning a label to each pixel in an image, indicating what object or scene it belongs to. This is a valuable capability for many computer vision applications, such as self-driving cars and image editing.
Traditionally, training semantic segmentation models requires detailed pixel-level annotations, which are time-consuming and expensive to obtain. Weakly supervised learning aims to address this by using more easily available image-level labels (e.g., "this image contains a car") instead.
The key challenge in weakly supervised semantic segmentation is that the model needs to learn to locate and segment the relevant objects or regions in the image, even though it only has access to coarse image-level labels during training.
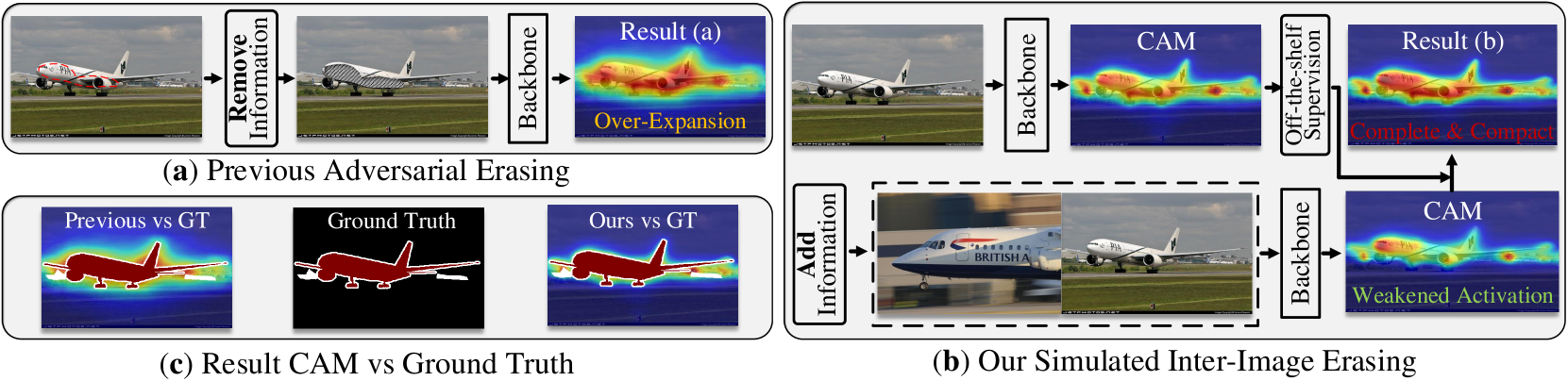
This paper introduces a novel approach called "Knowledge Transfer with Simulated Inter-Image Erasing" (KISE) to tackle this challenge. The main idea is to leverage the knowledge learned by a strongly supervised model (one trained with pixel-level annotations) by simulating the process of erasing parts of the image during training. This teaches the weakly supervised model to focus on the most discriminative features, improving its segmentation performance.
The KISE method works by first training a strongly supervised model on a dataset with pixel-level labels. During training of the weakly supervised model, the algorithm randomly erases or "masks out" different regions of the input images, forcing the model to learn features that are robust to such occlusions. This simulates the real-world scenario where certain parts of an object may be occluded or hard to see, and encourages the model to focus on the most informative visual cues.
The authors show that this knowledge transfer approach leads to state-of-the-art performance on several weakly supervised semantic segmentation benchmarks, outperforming previous methods.
Technical Explanation
The paper proposes a novel Knowledge Transfer with Simulated Inter-Image Erasing (KISE) framework for weakly supervised semantic segmentation. The key idea is to leverage the knowledge learned by a strongly supervised model to guide the training of a weakly supervised model, by simulating the process of erasing parts of the input images.
First, the authors train a strongly supervised segmentation model using a dataset with pixel-level annotations. This model serves as the "teacher" network, providing guidance to the weakly supervised student model during training.
For the weakly supervised training, the algorithm applies random erasing to the input images, where rectangular regions are masked out with a constant value. This encourages the student model to learn robust features that are invariant to partial occlusions or missing information, similar to the real-world scenarios encountered in weakly supervised learning.
To transfer knowledge from the strongly supervised teacher model, the authors propose two key components:
-
Inter-Image Erasing Consistency Loss: This loss term encourages the student model to produce consistent predictions before and after the random erasing is applied to the input image. This helps the student model learn to focus on the most discriminative features.
-
Teacher-Guided Attention Map: The attention maps produced by the teacher model are used to guide the student model's attention, further improving its segmentation performance.
The authors evaluate the proposed KISE framework on several weakly supervised semantic segmentation benchmarks, including Pascal VOC 2012 and MS-COCO. The results show that KISE outperforms previous state-of-the-art weakly supervised methods, demonstrating the effectiveness of the knowledge transfer approach.
Critical Analysis
The KISE framework presented in this paper is a promising approach for addressing the challenge of weakly supervised semantic segmentation. By leveraging the knowledge of a strongly supervised model through simulated inter-image erasing, the method is able to guide the weakly supervised model to focus on the most informative visual features.
One potential limitation of the approach is that it relies on the availability of a strongly supervised model, which may not always be practical or feasible. The authors do not explore the impact of the quality or architecture of the teacher model on the performance of the student model.
Additionally, the paper does not provide a detailed analysis of the types of errors or failures that the KISE method may still exhibit. Understanding the failure modes and limitations of the approach would be valuable for identifying areas for further improvement.
Overall, the KISE framework represents a significant advancement in weakly supervised semantic segmentation, and the authors have demonstrated its effectiveness on several benchmark datasets. Further research into the scalability, robustness, and generalization of the method could lead to even more impactful applications in real-world computer vision scenarios.
Conclusion
This paper introduces a novel Knowledge Transfer with Simulated Inter-Image Erasing (KISE) framework for weakly supervised semantic segmentation. The key idea is to leverage the knowledge learned by a strongly supervised model to guide the training of a weakly supervised model, by simulating the process of randomly erasing parts of the input images.
The KISE method achieves state-of-the-art performance on several weakly supervised semantic segmentation benchmarks, demonstrating the effectiveness of the knowledge transfer approach. By focusing the weakly supervised model on the most discriminative visual features, KISE addresses a fundamental challenge in this domain and paves the way for more practical and scalable semantic segmentation solutions.
The insights and techniques presented in this paper could have broader implications for other areas of weakly supervised learning and knowledge distillation, potentially leading to more efficient and robust computer vision models that can be trained with fewer annotated examples.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Knowledge Transfer with Simulated Inter-Image Erasing for Weakly Supervised Semantic Segmentation
Tao Chen, XiRuo Jiang, Gensheng Pei, Zeren Sun, Yucheng Wang, Yazhou Yao
Though adversarial erasing has prevailed in weakly supervised semantic segmentation to help activate integral object regions, existing approaches still suffer from the dilemma of under-activation and over-expansion due to the difficulty in determining when to stop erasing. In this paper, we propose a textbf{K}nowledge textbf{T}ransfer with textbf{S}imulated Inter-Image textbf{E}rasing (KTSE) approach for weakly supervised semantic segmentation to alleviate the above problem. In contrast to existing erasing-based methods that remove the discriminative part for more object discovery, we propose a simulated inter-image erasing scenario to weaken the original activation by introducing extra object information. Then, object knowledge is transferred from the anchor image to the consequent less activated localization map to strengthen network localization ability. Considering the adopted bidirectional alignment will also weaken the anchor image activation if appropriate constraints are missing, we propose a self-supervised regularization module to maintain the reliable activation in discriminative regions and improve the inter-class object boundary recognition for complex images with multiple categories of objects. In addition, we resort to intra-image erasing and propose a multi-granularity alignment module to gently enlarge the object activation to boost the object knowledge transfer. Extensive experiments and ablation studies on PASCAL VOC 2012 and COCO datasets demonstrate the superiority of our proposed approach. Source codes and models are available at https://github.com/NUST-Machine-Intelligence-Laboratory/KTSE.
Read more7/4/2024

0
STEREO: Towards Adversarially Robust Concept Erasing from Text-to-Image Generation Models
Koushik Srivatsan, Fahad Shamshad, Muzammal Naseer, Karthik Nandakumar
The rapid proliferation of large-scale text-to-image generation (T2IG) models has led to concerns about their potential misuse in generating harmful content. Though many methods have been proposed for erasing undesired concepts from T2IG models, they only provide a false sense of security, as recent works demonstrate that concept-erased models (CEMs) can be easily deceived to generate the erased concept through adversarial attacks. The problem of adversarially robust concept erasing without significant degradation to model utility (ability to generate benign concepts) remains an unresolved challenge, especially in the white-box setting where the adversary has access to the CEM. To address this gap, we propose an approach called STEREO that involves two distinct stages. The first stage searches thoroughly enough for strong and diverse adversarial prompts that can regenerate an erased concept from a CEM, by leveraging robust optimization principles from adversarial training. In the second robustly erase once stage, we introduce an anchor-concept-based compositional objective to robustly erase the target concept at one go, while attempting to minimize the degradation on model utility. By benchmarking the proposed STEREO approach against four state-of-the-art concept erasure methods under three adversarial attacks, we demonstrate its ability to achieve a better robustness vs. utility trade-off. Our code and models are available at https://github.com/koushiksrivats/robust-concept-erasing.
Read more9/2/2024

0
Improving Weakly-Supervised Object Localization Using Adversarial Erasing and Pseudo Label
Byeongkeun Kang, Sinhae Cha, Yeejin Lee
Weakly-supervised learning approaches have gained significant attention due to their ability to reduce the effort required for human annotations in training neural networks. This paper investigates a framework for weakly-supervised object localization, which aims to train a neural network capable of predicting both the object class and its location using only images and their image-level class labels. The proposed framework consists of a shared feature extractor, a classifier, and a localizer. The localizer predicts pixel-level class probabilities, while the classifier predicts the object class at the image level. Since image-level class labels are insufficient for training the localizer, weakly-supervised object localization methods often encounter challenges in accurately localizing the entire object region. To address this issue, the proposed method incorporates adversarial erasing and pseudo labels to improve localization accuracy. Specifically, novel losses are designed to utilize adversarially erased foreground features and adversarially erased feature maps, reducing dependence on the most discriminative region. Additionally, the proposed method employs pseudo labels to suppress activation values in the background while increasing them in the foreground. The proposed method is applied to two backbone networks (MobileNetV1 and InceptionV3) and is evaluated on three publicly available datasets (ILSVRC-2012, CUB-200-2011, and PASCAL VOC 2012). The experimental results demonstrate that the proposed method outperforms previous state-of-the-art methods across all evaluated metrics.
Read more4/16/2024
🔄
0
ELiTe: Efficient Image-to-LiDAR Knowledge Transfer for Semantic Segmentation
Zhibo Zhang, Ximing Yang, Weizhong Zhang, Cheng Jin
Cross-modal knowledge transfer enhances point cloud representation learning in LiDAR semantic segmentation. Despite its potential, the textit{weak teacher challenge} arises due to repetitive and non-diverse car camera images and sparse, inaccurate ground truth labels. To address this, we propose the Efficient Image-to-LiDAR Knowledge Transfer (ELiTe) paradigm. ELiTe introduces Patch-to-Point Multi-Stage Knowledge Distillation, transferring comprehensive knowledge from the Vision Foundation Model (VFM), extensively trained on diverse open-world images. This enables effective knowledge transfer to a lightweight student model across modalities. ELiTe employs Parameter-Efficient Fine-Tuning to strengthen the VFM teacher and expedite large-scale model training with minimal costs. Additionally, we introduce the Segment Anything Model based Pseudo-Label Generation approach to enhance low-quality image labels, facilitating robust semantic representations. Efficient knowledge transfer in ELiTe yields state-of-the-art results on the SemanticKITTI benchmark, outperforming real-time inference models. Our approach achieves this with significantly fewer parameters, confirming its effectiveness and efficiency.
Read more5/8/2024