ELiTe: Efficient Image-to-LiDAR Knowledge Transfer for Semantic Segmentation

0
🔄
Sign in to get full access
Overview
- The paper proposes a new approach called Efficient Image-to-LiDAR Knowledge Transfer (ELiTe) to address the "weak teacher challenge" in LiDAR semantic segmentation.
- The approach leverages a Vision Foundation Model (VFM) to effectively transfer comprehensive knowledge from diverse open-world images to a lightweight student model.
- ELiTe employs a Patch-to-Point Multi-Stage Knowledge Distillation technique and a Parameter-Efficient Fine-Tuning method to enhance the VFM teacher and expedite large-scale model training.
- It also introduces a Segment Anything Model based Pseudo-Label Generation approach to improve the quality of image labels, enabling robust semantic representations.
Plain English Explanation
In this paper, the researchers present a new method called ELiTe to improve LiDAR semantic segmentation, which is the process of assigning semantic labels (e.g., car, pedestrian, road) to individual points in a 3D point cloud captured by LiDAR sensors. LiDAR is a technology that uses laser light to measure distances and create 3D maps of the environment.
The main challenge the researchers address is the "weak teacher problem" in cross-modal knowledge transfer, where the training data (camera images and their associated labels) is repetitive and lacks diversity, leading to inaccurate labels for LiDAR data. To overcome this, ELiTe leverages a Vision Foundation Model, which is a powerful AI model trained on a vast and diverse set of images from the open world. This allows ELiTe to effectively transfer comprehensive knowledge from the Vision Foundation Model to a more lightweight student model that can perform LiDAR semantic segmentation.
The researchers also introduce a few key techniques to further enhance the knowledge transfer process:
- Patch-to-Point Multi-Stage Knowledge Distillation: This enables the transfer of knowledge from the image-based Vision Foundation Model to the 3D point cloud-based student model.
- Parameter-Efficient Fine-Tuning: This helps strengthen the Vision Foundation Model teacher and expedite the training of the large-scale model with minimal computational costs.
- Segment Anything Model based Pseudo-Label Generation: This approach enhances the quality of the image labels, which are often inaccurate, leading to more robust semantic representations in the student model.
By employing these techniques, the ELiTe approach is able to achieve state-of-the-art results on the SemanticKITTI benchmark for LiDAR semantic segmentation, outperforming even real-time inference models. Importantly, ELiTe accomplishes this with significantly fewer parameters, demonstrating its efficiency and effectiveness.
Technical Explanation
The paper introduces the Efficient Image-to-LiDAR Knowledge Transfer (ELiTe) paradigm to address the "weak teacher challenge" in LiDAR semantic segmentation. This challenge arises due to the repetitive and non-diverse nature of camera images used for training, along with the sparse and inaccurate ground truth labels associated with them.
To overcome this, ELiTe leverages a Vision Foundation Model (VFM) that has been extensively trained on diverse open-world images. The researchers propose a Patch-to-Point Multi-Stage Knowledge Distillation technique to effectively transfer the comprehensive knowledge from the VFM to a lightweight student model across modalities (i.e., from images to 3D point clouds).
Additionally, ELiTe employs a Parameter-Efficient Fine-Tuning approach to strengthen the VFM teacher and expedite the large-scale model training process with minimal computational costs.
To further enhance the quality of the image labels, the researchers introduce a Segment Anything Model based Pseudo-Label Generation approach. This helps to address the inaccuracies in the ground truth labels, enabling the student model to learn more robust semantic representations.
The proposed ELiTe paradigm achieves state-of-the-art results on the SemanticKITTI benchmark for LiDAR semantic segmentation, outperforming even real-time inference models. Importantly, ELiTe accomplishes this with significantly fewer parameters, demonstrating its efficiency and effectiveness.
Critical Analysis
The paper presents a comprehensive approach to address the "weak teacher challenge" in LiDAR semantic segmentation, which is a significant problem in the field. The researchers have carefully designed their ELiTe paradigm to leverage the strengths of a Vision Foundation Model and employ various techniques to enhance the knowledge transfer process.
One potential limitation of the approach is the reliance on the availability of a well-trained Vision Foundation Model. While the researchers have demonstrated the effectiveness of this approach, the applicability may be limited to settings where such a model is readily accessible or can be trained with significant computational resources.
Additionally, the paper does not provide a detailed discussion of the computational and memory footprint of the ELiTe paradigm, beyond the fact that it achieves state-of-the-art results with fewer parameters. It would be helpful to have a more thorough analysis of the trade-offs between model performance and resource requirements, especially for deployment in real-world applications with strict computational constraints.
Furthermore, the researchers could have explored the generalizability of their approach to other tasks or modalities beyond LiDAR semantic segmentation. Investigating the potential for cross-domain knowledge transfer or the adaptability of the techniques to related problems could further highlight the broader implications of the ELiTe paradigm.
Overall, the paper presents a compelling and innovative solution to a challenging problem, and the researchers have demonstrated the effectiveness of their approach through rigorous experimentation. However, a deeper exploration of the practical considerations and potential limitations would help provide a more comprehensive understanding of the ELiTe paradigm and its applicability in real-world scenarios.
Conclusion
The ELiTe paradigm proposed in this paper offers a promising solution to the "weak teacher challenge" in LiDAR semantic segmentation. By leveraging a powerful Vision Foundation Model and employing various techniques for efficient knowledge transfer, the researchers have developed an approach that achieves state-of-the-art performance on the SemanticKITTI benchmark, while using significantly fewer parameters.
The key innovations of ELiTe, such as Patch-to-Point Multi-Stage Knowledge Distillation, Parameter-Efficient Fine-Tuning, and Segment Anything Model based Pseudo-Label Generation, demonstrate the researchers' thoughtful and comprehensive approach to addressing the challenges in cross-modal knowledge transfer.
If successfully deployed, the ELiTe paradigm could have significant implications for a wide range of applications that rely on accurate and efficient LiDAR semantic segmentation, such as autonomous driving, robotics, and urban planning. The ability to achieve high-performance results with fewer computational resources could make these technologies more accessible and scalable, potentially driving further advancements in the field.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔄
0
ELiTe: Efficient Image-to-LiDAR Knowledge Transfer for Semantic Segmentation
Zhibo Zhang, Ximing Yang, Weizhong Zhang, Cheng Jin
Cross-modal knowledge transfer enhances point cloud representation learning in LiDAR semantic segmentation. Despite its potential, the textit{weak teacher challenge} arises due to repetitive and non-diverse car camera images and sparse, inaccurate ground truth labels. To address this, we propose the Efficient Image-to-LiDAR Knowledge Transfer (ELiTe) paradigm. ELiTe introduces Patch-to-Point Multi-Stage Knowledge Distillation, transferring comprehensive knowledge from the Vision Foundation Model (VFM), extensively trained on diverse open-world images. This enables effective knowledge transfer to a lightweight student model across modalities. ELiTe employs Parameter-Efficient Fine-Tuning to strengthen the VFM teacher and expedite large-scale model training with minimal costs. Additionally, we introduce the Segment Anything Model based Pseudo-Label Generation approach to enhance low-quality image labels, facilitating robust semantic representations. Efficient knowledge transfer in ELiTe yields state-of-the-art results on the SemanticKITTI benchmark, outperforming real-time inference models. Our approach achieves this with significantly fewer parameters, confirming its effectiveness and efficiency.
Read more5/8/2024
✨
0
Fine-grained Image-to-LiDAR Contrastive Distillation with Visual Foundation Models
Yifan Zhang, Junhui Hou
Contrastive image-to-LiDAR knowledge transfer, commonly used for learning 3D representations with synchronized images and point clouds, often faces a self-conflict dilemma. This issue arises as contrastive losses unintentionally dissociate features of unmatched points and pixels that share semantic labels, compromising the integrity of learned representations. To overcome this, we harness Visual Foundation Models (VFMs), which have revolutionized the acquisition of pixel-level semantics, to enhance 3D representation learning. Specifically, we utilize off-the-shelf VFMs to generate semantic labels for weakly-supervised pixel-to-point contrastive distillation. Additionally, we employ von Mises-Fisher distributions to structure the feature space, ensuring semantic embeddings within the same class remain consistent across varying inputs. Furthermore, we adapt sampling probabilities of points to address imbalances in spatial distribution and category frequency, promoting comprehensive and balanced learning. Extensive experiments demonstrate that our approach mitigates the challenges posed by traditional methods and consistently surpasses existing image-to-LiDAR contrastive distillation methods in downstream tasks. The source code is available at href{https://github.com/Eaphan/OLIVINE.}{color{black}https://github.com/Eaphan/OLIVINE}.
Read more5/24/2024
🧪
0
TransKD: Transformer Knowledge Distillation for Efficient Semantic Segmentation
Ruiping Liu, Kailun Yang, Alina Roitberg, Jiaming Zhang, Kunyu Peng, Huayao Liu, Yaonan Wang, Rainer Stiefelhagen
Semantic segmentation benchmarks in the realm of autonomous driving are dominated by large pre-trained transformers, yet their widespread adoption is impeded by substantial computational costs and prolonged training durations. To lift this constraint, we look at efficient semantic segmentation from a perspective of comprehensive knowledge distillation and aim to bridge the gap between multi-source knowledge extractions and transformer-specific patch embeddings. We put forward the Transformer-based Knowledge Distillation (TransKD) framework which learns compact student transformers by distilling both feature maps and patch embeddings of large teacher transformers, bypassing the long pre-training process and reducing the FLOPs by >85.0%. Specifically, we propose two fundamental modules to realize feature map distillation and patch embedding distillation, respectively: (1) Cross Selective Fusion (CSF) enables knowledge transfer between cross-stage features via channel attention and feature map distillation within hierarchical transformers; (2) Patch Embedding Alignment (PEA) performs dimensional transformation within the patchifying process to facilitate the patch embedding distillation. Furthermore, we introduce two optimization modules to enhance the patch embedding distillation from different perspectives: (1) Global-Local Context Mixer (GL-Mixer) extracts both global and local information of a representative embedding; (2) Embedding Assistant (EA) acts as an embedding method to seamlessly bridge teacher and student models with the teacher's number of channels. Experiments on Cityscapes, ACDC, NYUv2, and Pascal VOC2012 datasets show that TransKD outperforms state-of-the-art distillation frameworks and rivals the time-consuming pre-training method. The source code is publicly available at https://github.com/RuipingL/TransKD.
Read more9/6/2024
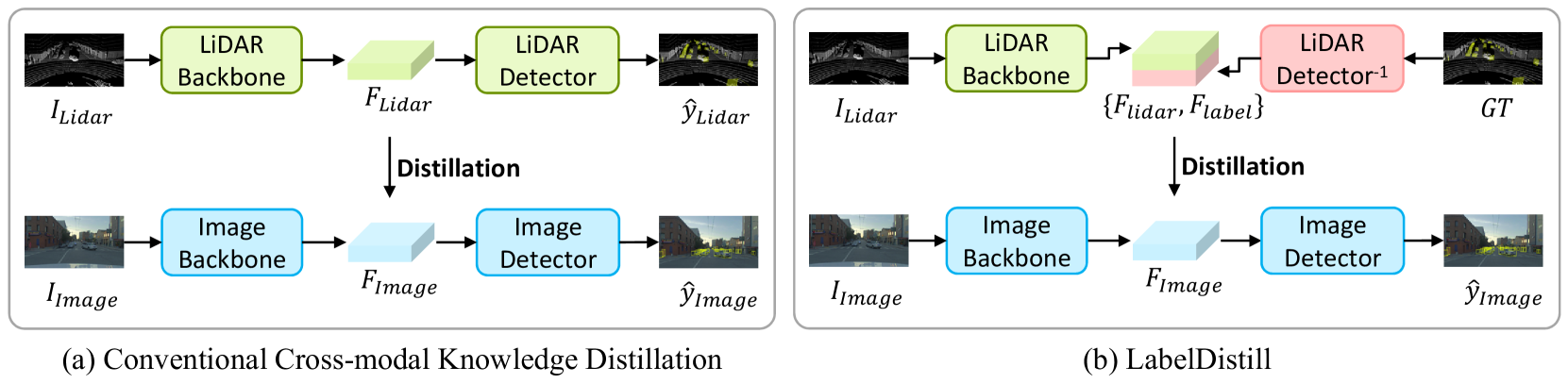
0
LabelDistill: Label-guided Cross-modal Knowledge Distillation for Camera-based 3D Object Detection
Sanmin Kim, Youngseok Kim, Sihwan Hwang, Hyeonjun Jeong, Dongsuk Kum
Recent advancements in camera-based 3D object detection have introduced cross-modal knowledge distillation to bridge the performance gap with LiDAR 3D detectors, leveraging the precise geometric information in LiDAR point clouds. However, existing cross-modal knowledge distillation methods tend to overlook the inherent imperfections of LiDAR, such as the ambiguity of measurements on distant or occluded objects, which should not be transferred to the image detector. To mitigate these imperfections in LiDAR teacher, we propose a novel method that leverages aleatoric uncertainty-free features from ground truth labels. In contrast to conventional label guidance approaches, we approximate the inverse function of the teacher's head to effectively embed label inputs into feature space. This approach provides additional accurate guidance alongside LiDAR teacher, thereby boosting the performance of the image detector. Additionally, we introduce feature partitioning, which effectively transfers knowledge from the teacher modality while preserving the distinctive features of the student, thereby maximizing the potential of both modalities. Experimental results demonstrate that our approach improves mAP and NDS by 5.1 points and 4.9 points compared to the baseline model, proving the effectiveness of our approach. The code is available at https://github.com/sanmin0312/LabelDistill
Read more7/16/2024