Label-efficient Semantic Scene Completion with Scribble Annotations

0
🔍
Sign in to get full access
Overview
- This paper introduces a new label-efficient benchmark called ScribbleSC for semantic scene completion, which aims to infer 3D geometric structures with semantic classes from camera or LiDAR data.
- The key innovation is the use of sparse scribble-based semantic labels combined with dense geometric labels, which can reduce the expensive and tedious labeling costs associated with fully-supervised approaches.
- The authors propose a method called Scribble2Scene that bridges the gap between the sparse scribble annotations and full supervision, using geometric-aware auto-labelers and an offline-to-online distillation module.
- Experiments on the SemanticKITTI dataset show that Scribble2Scene achieves competitive performance against fully-supervised models, using only 13.5% of the voxels labeled.
Plain English Explanation
Semantic scene completion is an important task in autonomous driving, where the goal is to understand the 3D shape and contents of the world around the vehicle. Previous approaches have relied on having detailed, point-by-point annotations of the 3D data, which is very time-consuming and expensive to gather.
The researchers in this paper propose a new, more efficient way to do semantic scene completion. Instead of requiring full annotations, they use a technique called "scribble-based labeling", where the human annotator just needs to draw a few rough outlines on the 3D data to indicate the general shapes and contents. This takes much less time and effort.
The key innovation is a method called Scribble2Scene that can take these sparse scribble annotations and use them to train a high-performing 3D scene understanding model. It does this by automatically generating more detailed labels based on the geometric structure of the 3D data, and then using a special training technique to transfer knowledge from a fully-supervised model to the scribble-based model.
When tested on a standard benchmark dataset, the Scribble2Scene method was able to achieve performance very close to the fully-supervised models, but with only 13.5% of the 3D voxels labeled. This shows it's possible to get accurate 3D scene understanding without needing to painstakingly label every single detail.
Technical Explanation
The paper introduces a new benchmark called ScribbleSC for semantic scene completion, where sparse scribble-based semantic labels are combined with dense geometric labels. This aims to reduce the high labeling costs associated with fully-supervised approaches, which require dense point-wise semantic annotations.
To bridge the gap between the sparse scribble annotations and full supervision, the authors propose the Scribble2Scene method. It consists of two key components:
-
Geometric-aware auto-labelers: These generate more detailed semantic labels from the sparse scribble inputs, by leveraging the underlying 3D geometric structure of the scene.
-
Offline-to-online distillation: An offline fully-supervised model is used to guide the training of the online scribble-based model, transferring knowledge to improve its performance.
Experiments on the SemanticKITTI dataset show that Scribble2Scene achieves competitive results compared to fully-supervised approaches, reaching 99% of their performance while using only 13.5% of the voxels labeled.
The authors also introduce the ScribbleSC benchmark, which provides the sparse scribble annotations combined with dense geometric labels, as a new resource for advancing research in this area.
Critical Analysis
The Scribble2Scene method presented in this paper is a promising approach for reducing the high labeling costs associated with semantic scene completion. By leveraging sparse scribble-based annotations instead of dense point-wise labels, it can achieve comparable performance to fully-supervised models while requiring much less human effort.
However, the paper does not extensively explore the limitations or potential drawbacks of this approach. For example, it's unclear how the method would perform in more complex or ambiguous scenes where the geometric structure alone may not be sufficient to accurately infer the semantic labels from the sparse scribbles.
Additionally, the paper does not provide a thorough analysis of the generalization capabilities of the Scribble2Scene model. It would be valuable to understand how well the approach transfers to different datasets or settings beyond the SemanticKITTI benchmark.
Further research could also investigate ways to make the scribble-based annotation process even more efficient, such as through active learning techniques that intelligently select the most informative regions for the human annotator to label.
Conclusion
This paper introduces a novel label-efficient approach for semantic scene completion, called Scribble2Scene, that leverages sparse scribble-based annotations combined with geometric labels. By bridging the gap between the sparse inputs and full supervision, the method can achieve competitive performance with only a fraction of the labeling effort required by traditional fully-supervised techniques.
The results on the SemanticKITTI dataset are promising and demonstrate the potential for this approach to significantly reduce the cost and time required for annotating 3D urban scenes. The new ScribbleSC benchmark provided by the authors is also a valuable resource for further advancing research in this area.
While the paper does not fully explore the limitations of the Scribble2Scene method, it represents an important step towards more efficient and scalable 3D scene understanding, which is crucial for the development of reliable and safe autonomous driving systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔍
0
Label-efficient Semantic Scene Completion with Scribble Annotations
Song Wang, Jiawei Yu, Wentong Li, Hao Shi, Kailun Yang, Junbo Chen, Jianke Zhu
Semantic scene completion aims to infer the 3D geometric structures with semantic classes from camera or LiDAR, which provide essential occupancy information in autonomous driving. Prior endeavors concentrate on constructing the network or benchmark in a fully supervised manner. While the dense occupancy grids need point-wise semantic annotations, which incur expensive and tedious labeling costs. In this paper, we build a new label-efficient benchmark, named ScribbleSC, where the sparse scribble-based semantic labels are combined with dense geometric labels for semantic scene completion. In particular, we propose a simple yet effective approach called Scribble2Scene, which bridges the gap between the sparse scribble annotations and fully-supervision. Our method consists of geometric-aware auto-labelers construction and online model training with an offline-to-online distillation module to enhance the performance. Experiments on SemanticKITTI demonstrate that Scribble2Scene achieves competitive performance against the fully-supervised counterparts, showing 99% performance of the fully-supervised models with only 13.5% voxels labeled. Both annotations of ScribbleSC and our full implementation are available at https://github.com/songw-zju/Scribble2Scene.
Read more5/27/2024

0
Semi-supervised 3D Semantic Scene Completion with 2D Vision Foundation Model Guidance
Duc-Hai Pham, Duc Dung Nguyen, Hoang-Anh Pham, Ho Lai Tuan, Phong Ha Nguyen, Khoi Nguyen, Rang Nguyen
Accurate prediction of 3D semantic occupancy from 2D visual images is vital in enabling autonomous agents to comprehend their surroundings for planning and navigation. State-of-the-art methods typically employ fully supervised approaches, necessitating a huge labeled dataset acquired through expensive LiDAR sensors and meticulous voxel-wise labeling by human annotators. The resource-intensive nature of this annotating process significantly hampers the application and scalability of these methods. We introduce a novel semi-supervised framework to alleviate the dependency on densely annotated data. Our approach leverages 2D foundation models to generate essential 3D scene geometric and semantic cues, facilitating a more efficient training process. Our framework exhibits notable properties: (1) Generalizability, applicable to various 3D semantic scene completion approaches, including 2D-3D lifting and 3D-2D transformer methods. (2) Effectiveness, as demonstrated through experiments on SemanticKITTI and NYUv2, wherein our method achieves up to 85% of the fully-supervised performance using only 10% labeled data. This approach not only reduces the cost and labor associated with data annotation but also demonstrates the potential for broader adoption in camera-based systems for 3D semantic occupancy prediction.
Read more9/16/2024
0
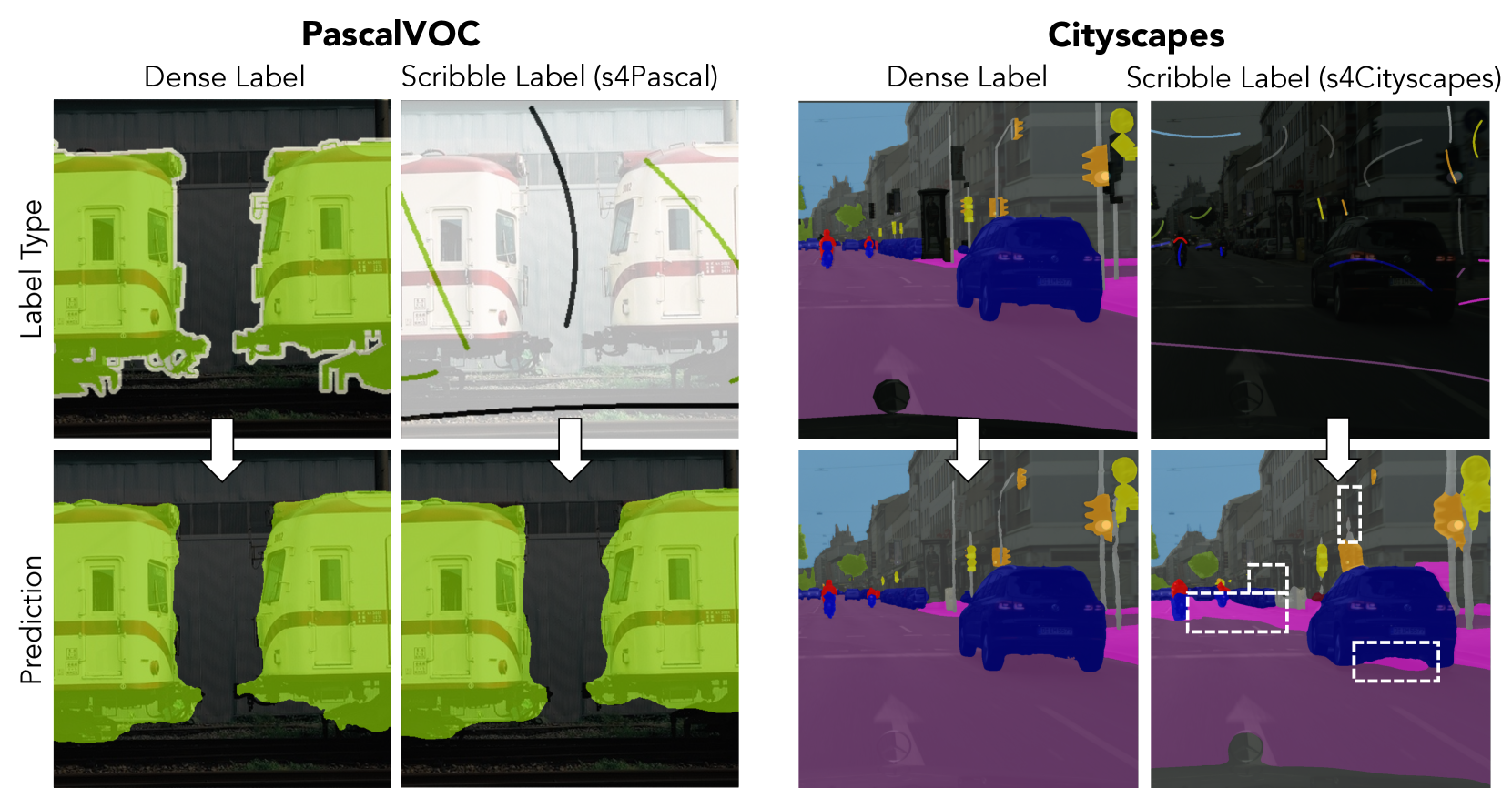
Scribbles for All: Benchmarking Scribble Supervised Segmentation Across Datasets
Wolfgang Boettcher, Lukas Hoyer, Ozan Unal, Jan Eric Lenssen, Bernt Schiele
In this work, we introduce Scribbles for All, a label and training data generation algorithm for semantic segmentation trained on scribble labels. Training or fine-tuning semantic segmentation models with weak supervision has become an important topic recently and was subject to significant advances in model quality. In this setting, scribbles are a promising label type to achieve high quality segmentation results while requiring a much lower annotation effort than usual pixel-wise dense semantic segmentation annotations. The main limitation of scribbles as source for weak supervision is the lack of challenging datasets for scribble segmentation, which hinders the development of novel methods and conclusive evaluations. To overcome this limitation, Scribbles for All provides scribble labels for several popular segmentation datasets and provides an algorithm to automatically generate scribble labels for any dataset with dense annotations, paving the way for new insights and model advancements in the field of weakly supervised segmentation. In addition to providing datasets and algorithm, we evaluate state-of-the-art segmentation models on our datasets and show that models trained with our synthetic labels perform competitively with respect to models trained on manual labels. Thus, our datasets enable state-of-the-art research into methods for scribble-labeled semantic segmentation. The datasets, scribble generation algorithm, and baselines are publicly available at https://github.com/wbkit/Scribbles4All
Read more8/23/2024

0
$alpha$-SSC: Uncertainty-Aware Camera-based 3D Semantic Scene Completion
Sanbao Su, Nuo Chen, Felix Juefei-Xu, Chen Feng, Fei Miao
In the realm of autonomous vehicle (AV) perception, comprehending 3D scenes is paramount for tasks such as planning and mapping. Semantic scene completion (SSC) aims to infer scene geometry and semantics from limited observations. While camera-based SSC has gained popularity due to affordability and rich visual cues, existing methods often neglect the inherent uncertainty in models. To address this, we propose an uncertainty-aware camera-based 3D semantic scene completion method ($alpha$-SSC). Our approach includes an uncertainty propagation framework from depth models (Depth-UP) to enhance geometry completion (up to 11.58% improvement) and semantic segmentation (up to 14.61% improvement). Additionally, we propose a hierarchical conformal prediction (HCP) method to quantify SSC uncertainty, effectively addressing high-level class imbalance in SSC datasets. On the geometry level, we present a novel KL divergence-based score function that significantly improves the occupied recall of safety-critical classes (45% improvement) with minimal performance overhead (3.4% reduction). For uncertainty quantification, we demonstrate the ability to achieve smaller prediction set sizes while maintaining a defined coverage guarantee. Compared with baselines, it achieves up to 85% reduction in set sizes. Our contributions collectively signify significant advancements in SSC accuracy and robustness, marking a noteworthy step forward in autonomous perception systems.
Read more6/24/2024