Coordinated Sparse Recovery of Label Noise
2404.04800
0
0
Abstract
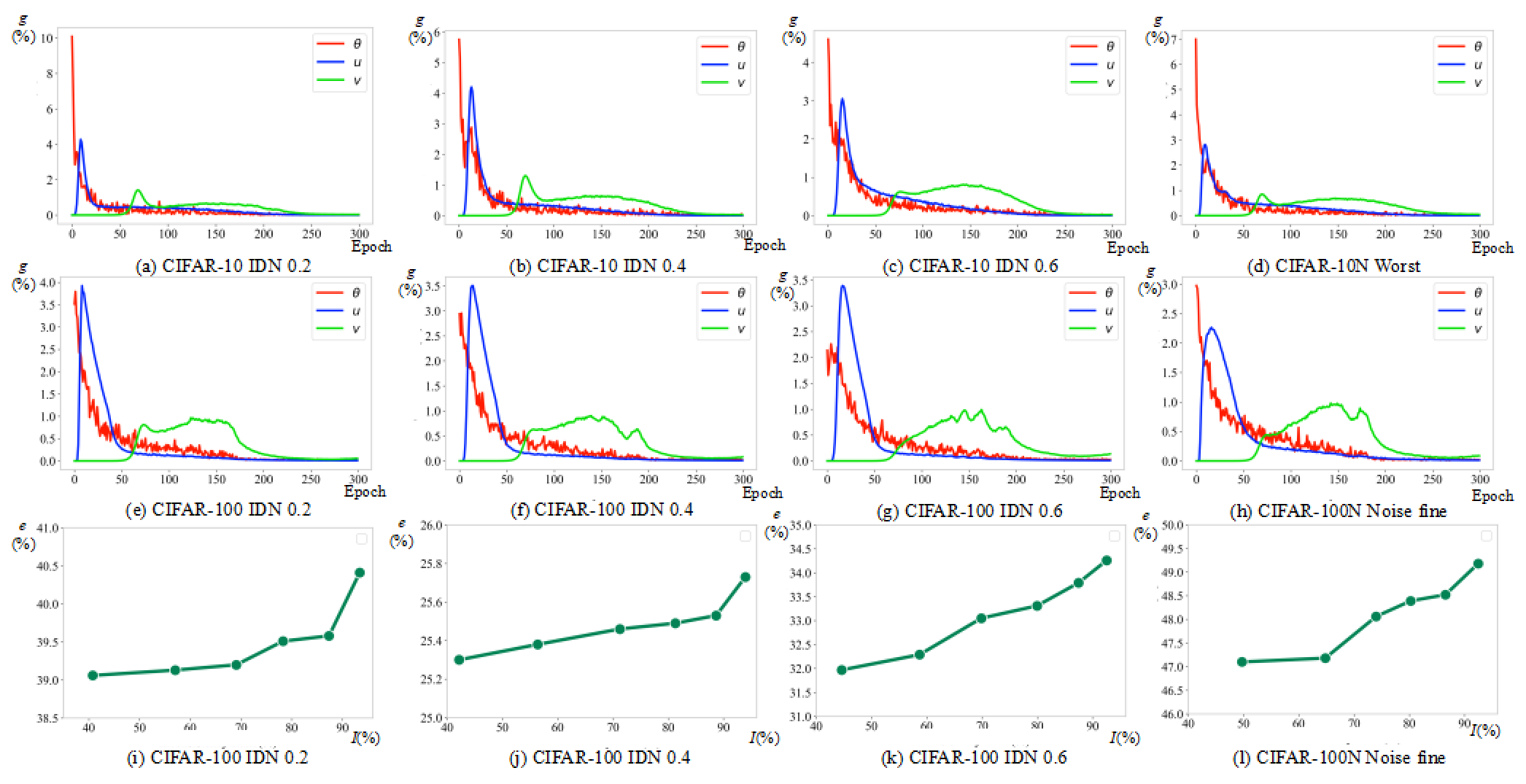
Label noise is a common issue in real-world datasets that inevitably impacts the generalization of models. This study focuses on robust classification tasks where the label noise is instance-dependent. Estimating the transition matrix accurately in this task is challenging, and methods based on sample selection often exhibit confirmation bias to varying degrees. Sparse over-parameterized training (SOP) has been theoretically effective in estimating and recovering label noise, offering a novel solution for noise-label learning. However, this study empirically observes and verifies a technical flaw of SOP: the lack of coordination between model predictions and noise recovery leads to increased generalization error. To address this, we propose a method called Coordinated Sparse Recovery (CSR). CSR introduces a collaboration matrix and confidence weights to coordinate model predictions and noise recovery, reducing error leakage. Based on CSR, this study designs a joint sample selection strategy and constructs a comprehensive and powerful learning framework called CSR+. CSR+ significantly reduces confirmation bias, especially for datasets with more classes and a high proportion of instance-specific noise. Experimental results on simulated and real-world noisy datasets demonstrate that both CSR and CSR+ achieve outstanding performance compared to methods at the same level.
Create account to get full access
Overview
- Addresses the challenge of learning from noisy or unreliable labels in machine learning
- Proposes a coordinated sparse recovery framework to jointly estimate the true labels and the label noise
- Leverages over-parameterization and a collaboration matrix to improve robustness to label noise
Plain English Explanation
When training machine learning models, the labels or target values we use to supervise the learning process can sometimes be noisy or unreliable. This can happen for a variety of reasons, such as mistakes in the data collection process, ambiguity in the labeling task, or even adversarial attacks aimed at corrupting the labels.
The paper proposes a new approach, called "Coordinated Sparse Recovery of Label Noise," that helps address this challenge. The key idea is to jointly estimate the true labels and the label noise, rather than treating them separately. This is done by leveraging a technique called "over-parameterization," where the model has more parameters than necessary to fit the data.
The over-parameterized model is then encouraged to find a sparse solution, meaning that only a few of the parameters are actually used. This sparse structure helps the model identify and recover the true labels, even in the presence of significant noise.
Additionally, the approach introduces a "collaboration matrix" that captures the relationships between different samples and helps the model better coordinate the sparse recovery process. This collaboration matrix is learned alongside the model, further improving its robustness to label noise.
By combining these techniques, the paper demonstrates how the proposed approach can effectively recover the true labels and label noise, leading to improved performance on machine learning tasks with noisy or unreliable labels.
Technical Explanation
The paper introduces a Coordinated Sparse Recovery of Label Noise framework to jointly estimate the true labels and the label noise. The key components of the approach are:
-
Over-parameterization: The model is designed to have more parameters than necessary to fit the data. This over-parameterization allows the model to discover a sparse solution, where only a few parameters are actually used.
-
Collaboration Matrix: The approach introduces a collaboration matrix that captures the relationships between different samples. This matrix is learned alongside the model and helps coordinate the sparse recovery process, improving the robustness to label noise.
-
Confidence Weighting: The model assigns a confidence weight to each sample, which is used to balance the contribution of different samples during training. Samples with higher confidence weights are given more importance, while those with lower confidence weights are down-weighted.
The paper evaluates the proposed approach on various benchmark datasets and real-world applications, such as pairwise similarity distribution clustering for noisy label learning and robust preference optimization with provable noise tolerance. The results demonstrate the effectiveness of the Coordinated Sparse Recovery of Label Noise framework in recovering the true labels and outperforming existing noisy label processing and classification techniques.
Critical Analysis
The paper presents a well-designed and comprehensive approach to addressing the challenge of learning from noisy or unreliable labels. The authors have carefully considered various aspects of the problem, such as over-parameterization, sparse modeling, and sample-level confidence weighting, to develop a robust solution.
One potential limitation of the approach is the computational complexity associated with learning the collaboration matrix, which could be challenging to scale to very large datasets. Additionally, the paper does not provide a detailed analysis of the sensitivity of the approach to the choice of hyperparameters or the specific characteristics of the label noise.
Further research could explore ways to signal-noise separation using unsupervised reservoir computing or other techniques to reduce the computational burden of the collaboration matrix learning. It would also be valuable to investigate the performance of the approach under different types and magnitudes of label noise, as well as its applicability to a wider range of machine learning problems.
Conclusion
The "Coordinated Sparse Recovery of Label Noise" paper presents a novel and promising approach to addressing the challenging problem of learning from noisy or unreliable labels. By leveraging over-parameterization, sparse modeling, and a collaboration matrix, the proposed framework demonstrates the ability to effectively recover the true labels and improve the robustness of machine learning models to label noise.
This research has the potential to significantly impact various applications where noisy or unreliable labels are a common challenge, such as image recognition, natural language processing, and clinical decision support systems. The insights and techniques presented in this paper can inspire further advancements in the field of noisy label learning and contribute to the development of more reliable and trustworthy machine learning systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Label Noise Robustness for Domain-Agnostic Fair Corrections via Nearest Neighbors Label Spreading
Nathan Stromberg, Rohan Ayyagari, Sanmi Koyejo, Richard Nock, Lalitha Sankar
0
0
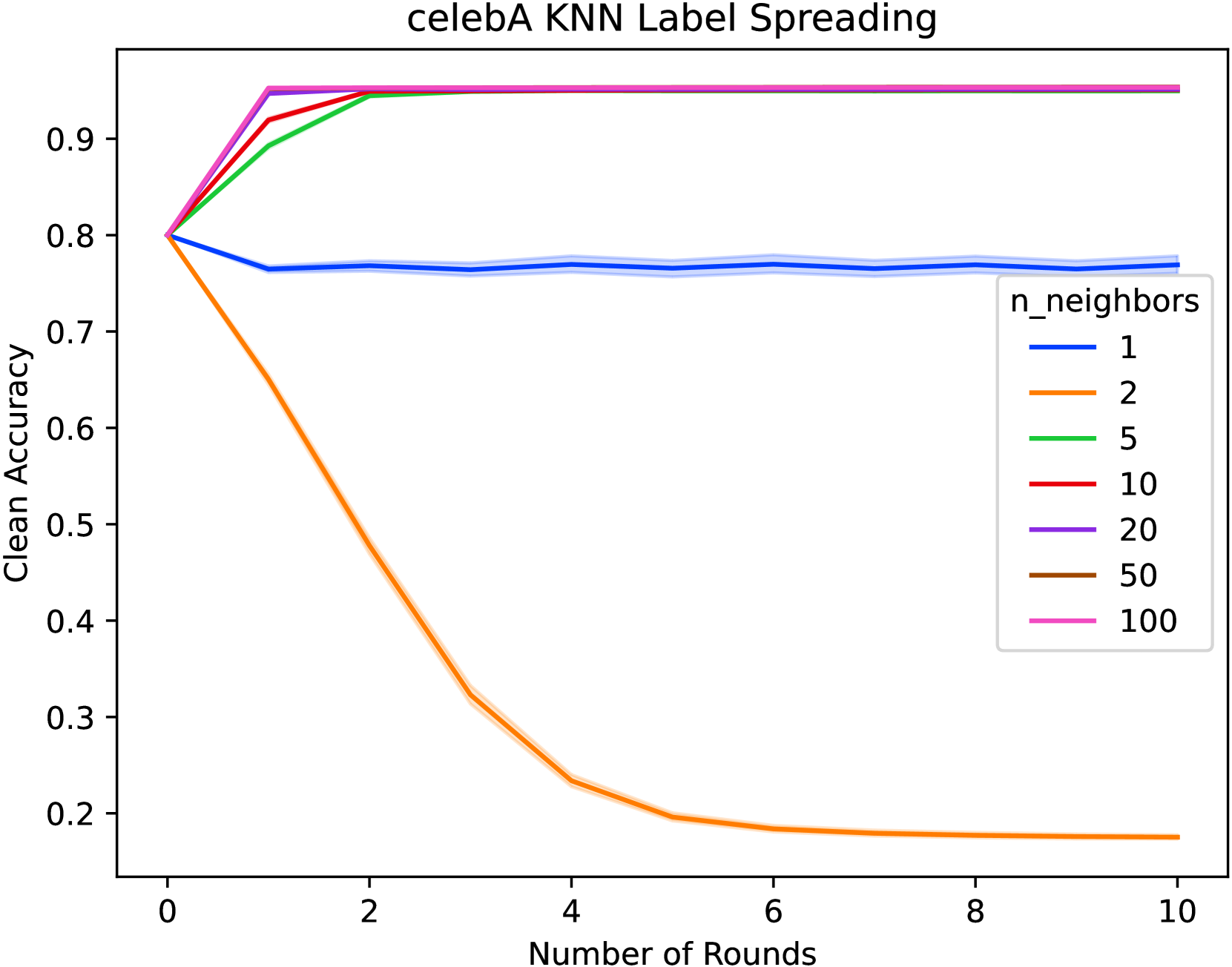
Last-layer retraining methods have emerged as an efficient framework for correcting existing base models. Within this framework, several methods have been proposed to deal with correcting models for subgroup fairness with and without group membership information. Importantly, prior work has demonstrated that many methods are susceptible to noisy labels. To this end, we propose a drop-in correction for label noise in last-layer retraining, and demonstrate that it achieves state-of-the-art worst-group accuracy for a broad range of symmetric label noise and across a wide variety of datasets exhibiting spurious correlations. Our proposed approach uses label spreading on a latent nearest neighbors graph and has minimal computational overhead compared to existing methods.
6/17/2024

Estimating Noisy Class Posterior with Part-level Labels for Noisy Label Learning
Rui Zhao, Bin Shi, Jianfei Ruan, Tianze Pan, Bo Dong
0
0
In noisy label learning, estimating noisy class posteriors plays a fundamental role for developing consistent classifiers, as it forms the basis for estimating clean class posteriors and the transition matrix. Existing methods typically learn noisy class posteriors by training a classification model with noisy labels. However, when labels are incorrect, these models may be misled to overemphasize the feature parts that do not reflect the instance characteristics, resulting in significant errors in estimating noisy class posteriors. To address this issue, this paper proposes to augment the supervised information with part-level labels, encouraging the model to focus on and integrate richer information from various parts. Specifically, our method first partitions features into distinct parts by cropping instances, yielding part-level labels associated with these various parts. Subsequently, we introduce a novel single-to-multiple transition matrix to model the relationship between the noisy and part-level labels, which incorporates part-level labels into a classifier-consistent framework. Utilizing this framework with part-level labels, we can learn the noisy class posteriors more precisely by guiding the model to integrate information from various parts, ultimately improving the classification performance. Our method is theoretically sound, while experiments show that it is empirically effective in synthetic and real-world noisy benchmarks.
5/10/2024
👀
Almost exact recovery in noisy semi-supervised learning
Konstantin Avrachenkov, Maximilien Dreveton
0
0
Graph-based semi-supervised learning methods combine the graph structure and labeled data to classify unlabeled data. In this work, we study the effect of a noisy oracle on classification. In particular, we derive the Maximum A Posteriori (MAP) estimator for clustering a Degree Corrected Stochastic Block Model (DC-SBM) when a noisy oracle reveals a fraction of the labels. We then propose an algorithm derived from a continuous relaxation of the MAP, and we establish its consistency. Numerical experiments show that our approach achieves promising performance on synthetic and real data sets, even in the case of very noisy labeled data.
6/6/2024

Provably Robust Cost-Sensitive Learning via Randomized Smoothing
Yuan Xin, Michael Backes, Xiao Zhang
0
0
We study the problem of robust learning against adversarial perturbations under cost-sensitive scenarios, where the potential harm of different types of misclassifications is encoded in a cost matrix. Existing approaches are either empirical and cannot certify robustness or suffer from inherent scalability issues. In this work, we investigate whether randomized smoothing, a scalable framework for robustness certification, can be leveraged to certify and train for cost-sensitive robustness. Built upon the notion of cost-sensitive certified radius, we first illustrate how to adapt the standard certification algorithm of randomized smoothing to produce tight robustness certificates for any binary cost matrix, and then develop a robust training method to promote certified cost-sensitive robustness while maintaining the model's overall accuracy. Through extensive experiments on image benchmarks, we demonstrate the superiority of our proposed certification algorithm and training method under various cost-sensitive scenarios. Our implementation is available as open source code at: https://github.com/TrustMLRG/CS-RS.
5/31/2024