Label Propagation for Zero-shot Classification with Vision-Language Models
2404.04072
0
0
🏷️
Abstract
Vision-Language Models (VLMs) have demonstrated impressive performance on zero-shot classification, i.e. classification when provided merely with a list of class names. In this paper, we tackle the case of zero-shot classification in the presence of unlabeled data. We leverage the graph structure of the unlabeled data and introduce ZLaP, a method based on label propagation (LP) that utilizes geodesic distances for classification. We tailor LP to graphs containing both text and image features and further propose an efficient method for performing inductive inference based on a dual solution and a sparsification step. We perform extensive experiments to evaluate the effectiveness of our method on 14 common datasets and show that ZLaP outperforms the latest related works. Code: https://github.com/vladan-stojnic/ZLaP
Create account to get full access
Overview
- The paper focuses on the problem of zero-shot classification, where a machine learning model is asked to classify data without having seen labeled examples of all the classes.
- The authors introduce a new method called ZLaP that leverages the graph structure of unlabeled data and label propagation to improve zero-shot classification performance.
- ZLaP is tailored to work with vision-language models that can process both text and image features.
- The authors demonstrate that ZLaP outperforms the latest related methods on 14 common datasets.
Plain English Explanation
Zero-Shot Classification Imagine you have a machine learning model that can identify different types of animals in images. Normally, you would need to show the model many examples of each animal (like cats, dogs, and horses) so it can learn to recognize them.
Zero-Shot Learning But what if you want the model to also recognize new types of animals it hasn't seen before, like pandas or koalas? This is called zero-shot learning - the model has to classify something it's never seen examples of before.
Using Unlabeled Data The key insight in this paper is that even if you don't have labeled examples of all the classes, you may have a lot of unlabeled data (images without labels). The authors show how you can use the relationships between this unlabeled data to help the model learn to recognize new classes.
Label Propagation Specifically, the authors introduce a method called ZLaP that uses label propagation - starting with a few labeled examples, it can "spread" those labels through the unlabeled data based on how similar the examples are. This helps the model learn to recognize new classes.
Vision-Language Models ZLaP is designed to work well with vision-language models - machine learning models that can process both text and images. This allows the method to leverage both the image and textual information in the data.
Technical Explanation
The key technical contributions of this paper are:
-
ZLaP Method: The authors introduce a novel zero-shot classification method called ZLaP that leverages the graph structure of unlabeled data and label propagation. ZLaP is designed to work with vision-language models that can process both text and image features.
-
Geodesic Distance-based Label Propagation: ZLaP uses geodesic distances (shortest paths) within the data graph to perform label propagation, which the authors show is more effective than Euclidean distance-based approaches.
-
Efficient Inductive Inference: The authors propose an efficient method for performing inductive inference (classifying new, unseen examples) using a dual solution and a sparsification step.
-
Extensive Evaluation: The paper presents a thorough experimental evaluation of ZLaP on 14 common datasets, demonstrating that it outperforms the latest related methods in zero-shot classification performance.
Critical Analysis
The paper makes a compelling case for the effectiveness of the ZLaP method in zero-shot classification tasks. However, a few potential limitations and areas for further research are worth noting:
-
Dependence on Graph Structure: The performance of ZLaP relies heavily on the quality and structure of the unlabeled data graph. In scenarios where the graph structure is less informative or noisy, the method's effectiveness may be diminished.
-
Sensitivity to Hyperparameters: The authors mention that ZLaP has several hyperparameters that need to be tuned, which could be a challenge in practical applications where the optimal settings are not known in advance.
-
Generalization to Other Domains: While the paper demonstrates strong results on the evaluated datasets, it would be valuable to see how ZLaP performs on a wider range of zero-shot learning tasks, such as zero-shot topic classification, to assess its broader applicability.
Overall, the ZLaP method represents an interesting and promising approach to zero-shot classification that leverages unlabeled data in a novel way. The authors have provided a solid technical foundation, and further research exploring the method's robustness and generalizability could yield valuable insights for the field.
Conclusion
This paper introduces a novel zero-shot classification method called ZLaP that leverages the graph structure of unlabeled data and label propagation to improve performance. ZLaP is designed to work well with vision-language models that can process both text and image features.
The authors demonstrate that ZLaP outperforms the latest related methods on 14 common datasets, showcasing the potential of their approach. While the method has some limitations, such as its dependence on the quality of the data graph and sensitivity to hyperparameters, the paper represents an important contribution to the field of zero-shot learning. Further research exploring the robustness and generalizability of ZLaP could yield valuable insights and drive the development of more effective zero-shot classification techniques.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
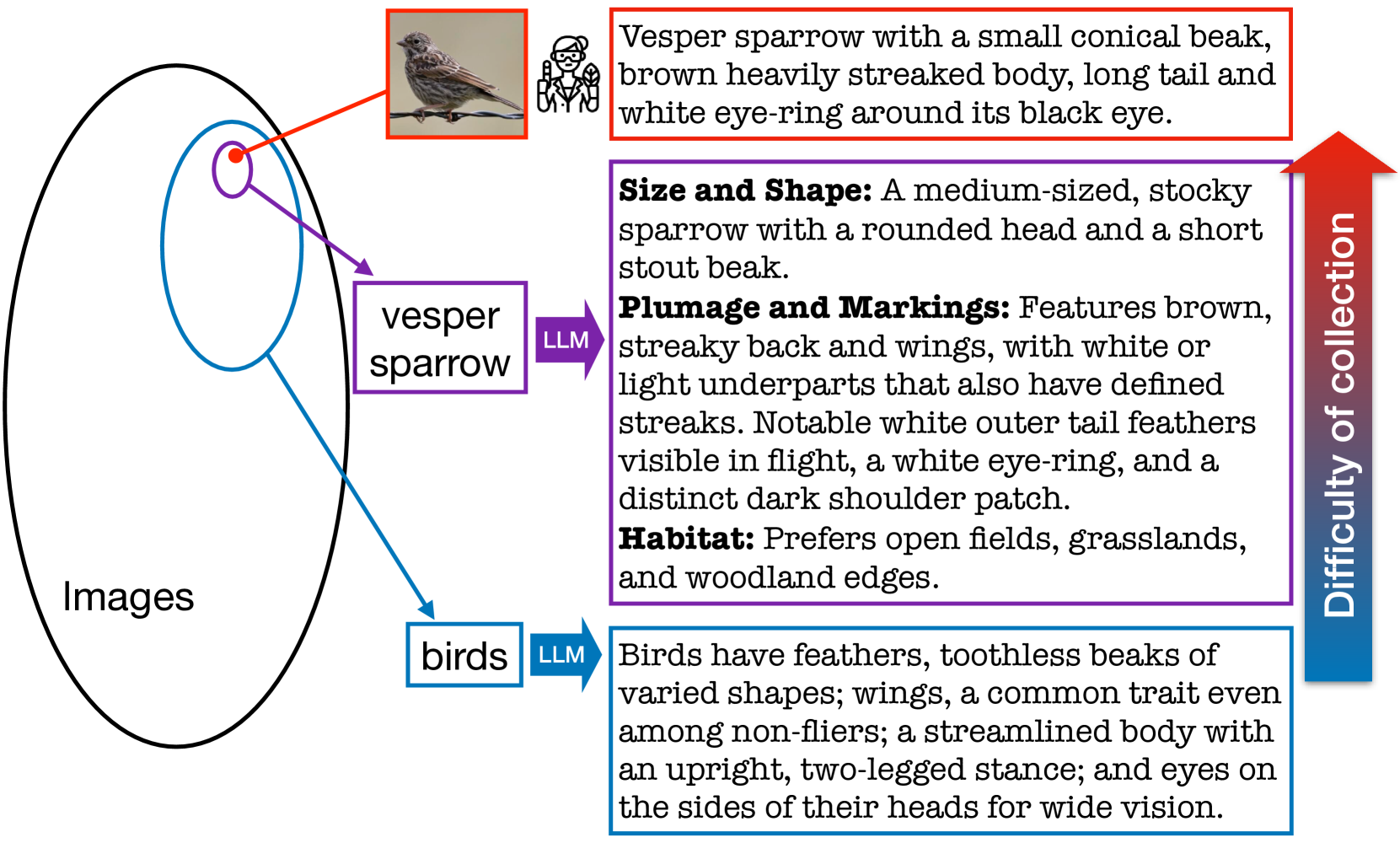
Improved Zero-Shot Classification by Adapting VLMs with Text Descriptions
Oindrila Saha, Grant Van Horn, Subhransu Maji
0
0
The zero-shot performance of existing vision-language models (VLMs) such as CLIP is limited by the availability of large-scale, aligned image and text datasets in specific domains. In this work, we leverage two complementary sources of information -- descriptions of categories generated by large language models (LLMs) and abundant, fine-grained image classification datasets -- to improve the zero-shot classification performance of VLMs across fine-grained domains. On the technical side, we develop methods to train VLMs with this bag-level image-text supervision. We find that simply using these attributes at test-time does not improve performance, but our training strategy, for example, on the iNaturalist dataset, leads to an average improvement of 4-5% in zero-shot classification accuracy for novel categories of birds and flowers. Similar improvements are observed in domains where a subset of the categories was used to fine-tune the model. By prompting LLMs in various ways, we generate descriptions that capture visual appearance, habitat, and geographic regions and pair them with existing attributes such as the taxonomic structure of the categories. We systematically evaluate their ability to improve zero-shot categorization in natural domains. Our findings suggest that geographic priors can be just as effective and are complementary to visual appearance. Our method also outperforms prior work on prompt-based tuning of VLMs. We release the benchmark, consisting of 14 datasets at https://github.com/cvl-umass/AdaptCLIPZS , which will contribute to future research in zero-shot recognition.
4/5/2024
🏷️
LLM meets Vision-Language Models for Zero-Shot One-Class Classification
Yassir Bendou, Giulia Lioi, Bastien Pasdeloup, Lukas Mauch, Ghouthi Boukli Hacene, Fabien Cardinaux, Vincent Gripon
0
0
We consider the problem of zero-shot one-class visual classification, extending traditional one-class classification to scenarios where only the label of the target class is available. This method aims to discriminate between positive and negative query samples without requiring examples from the target class. We propose a two-step solution that first queries large language models for visually confusing objects and then relies on vision-language pre-trained models (e.g., CLIP) to perform classification. By adapting large-scale vision benchmarks, we demonstrate the ability of the proposed method to outperform adapted off-the-shelf alternatives in this setting. Namely, we propose a realistic benchmark where negative query samples are drawn from the same original dataset as positive ones, including a granularity-controlled version of iNaturalist, where negative samples are at a fixed distance in the taxonomy tree from the positive ones. To our knowledge, we are the first to demonstrate the ability to discriminate a single category from other semantically related ones using only its label.
5/28/2024
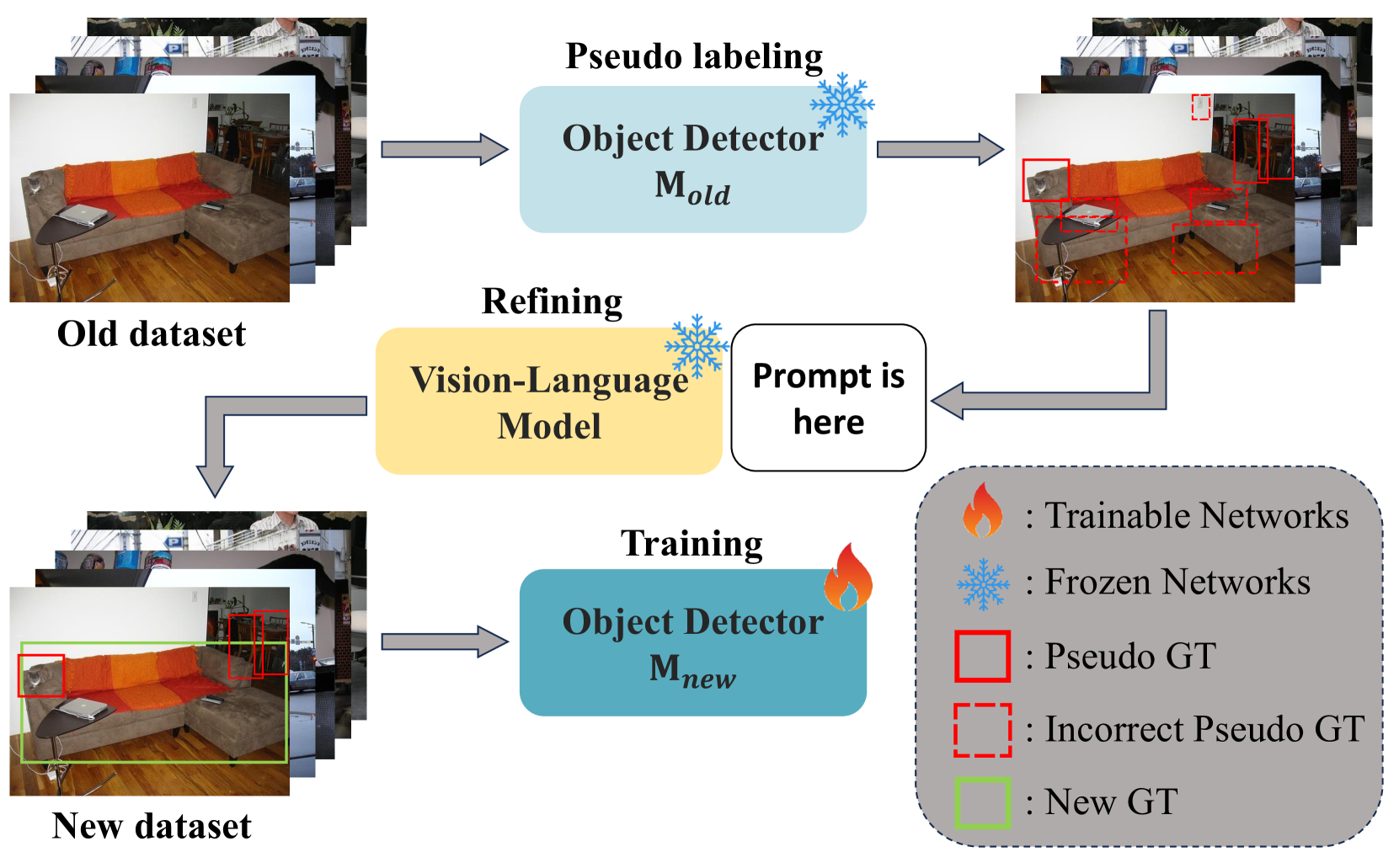
VLM-PL: Advanced Pseudo Labeling Approach for Class Incremental Object Detection via Vision-Language Model
Junsu Kim, Yunhoe Ku, Jihyeon Kim, Junuk Cha, Seungryul Baek
0
0
In the field of Class Incremental Object Detection (CIOD), creating models that can continuously learn like humans is a major challenge. Pseudo-labeling methods, although initially powerful, struggle with multi-scenario incremental learning due to their tendency to forget past knowledge. To overcome this, we introduce a new approach called Vision-Language Model assisted Pseudo-Labeling (VLM-PL). This technique uses Vision-Language Model (VLM) to verify the correctness of pseudo ground-truths (GTs) without requiring additional model training. VLM-PL starts by deriving pseudo GTs from a pre-trained detector. Then, we generate custom queries for each pseudo GT using carefully designed prompt templates that combine image and text features. This allows the VLM to classify the correctness through its responses. Furthermore, VLM-PL integrates refined pseudo and real GTs from upcoming training, effectively combining new and old knowledge. Extensive experiments conducted on the Pascal VOC and MS COCO datasets not only highlight VLM-PL's exceptional performance in multi-scenario but also illuminate its effectiveness in dual-scenario by achieving state-of-the-art results in both.
5/10/2024

Large Language Models are Good Prompt Learners for Low-Shot Image Classification
Zhaoheng Zheng, Jingmin Wei, Xuefeng Hu, Haidong Zhu, Ram Nevatia
0
0
Low-shot image classification, where training images are limited or inaccessible, has benefited from recent progress on pre-trained vision-language (VL) models with strong generalizability, e.g. CLIP. Prompt learning methods built with VL models generate text features from the class names that only have confined class-specific information. Large Language Models (LLMs), with their vast encyclopedic knowledge, emerge as the complement. Thus, in this paper, we discuss the integration of LLMs to enhance pre-trained VL models, specifically on low-shot classification. However, the domain gap between language and vision blocks the direct application of LLMs. Thus, we propose LLaMP, Large Language Models as Prompt learners, that produces adaptive prompts for the CLIP text encoder, establishing it as the connecting bridge. Experiments show that, compared with other state-of-the-art prompt learning methods, LLaMP yields better performance on both zero-shot generalization and few-shot image classification, over a spectrum of 11 datasets. Code will be made available at: https://github.com/zhaohengz/LLaMP.
4/4/2024