Label-Synchronous Neural Transducer for E2E Simultaneous Speech Translation

0

Sign in to get full access
Overview
- This paper presents a novel approach called the Label-Synchronous Neural Transducer (LSNT) for end-to-end simultaneous speech translation.
- The LSNT model aims to generate target language text in a label-synchronous manner, where the output is produced in sync with the input speech.
- The research explores techniques to enable simultaneous translation without compromising translation quality, a key challenge in this field.
Plain English Explanation
The paper describes a new method for simultaneous speech translation, where a machine translates spoken language into another language in real-time.
The key idea is to generate the translated text synchronously with the original speech, rather than waiting until the full speech is complete before translating. This label-synchronous approach allows for faster, more responsive translation.
The researchers developed a neural network model called the Label-Synchronous Neural Transducer (LSNT) to achieve this. The LSNT model learns to predict the next word in the translation as each word is spoken, without having to wait for the entire speech to finish.
This is a challenging problem because translating speech accurately requires understanding the full context. The LSNT model uses techniques to maintain translation quality even when working in a simultaneous fashion, without the full context available.
Technical Explanation
The paper introduces the Label-Synchronous Neural Transducer (LSNT), a novel neural network architecture for end-to-end simultaneous speech translation.
Unlike traditional speech translation models that wait for the full speech input before generating the translation, the LSNT model produces target language output synchronously with the input speech. This label-synchronous approach aims to enable real-time, responsive translation.
The LSNT model consists of an encoder that processes the input speech features, and a label-synchronous decoder that predicts the next target language token at each step. The key innovation is the use of a triggered attention mechanism that allows the decoder to selectively focus on relevant parts of the encoder output, even though the full input sequence is not yet available.
The researchers also propose beam search with target length prediction, a technique to generate full translation hypotheses during the synchronous decoding process. This helps maintain translation quality despite the limited context available in the simultaneous setting.
The LSNT model is evaluated on standard speech translation benchmarks, demonstrating improved latency and competitive translation quality compared to prior work on simultaneous speech translation.
Critical Analysis
The paper presents a compelling approach to the challenging problem of simultaneous speech translation. By generating translations synchronously with the input speech, the LSNT model can provide faster, more responsive translation than traditional wait-for-full-input methods.
However, the authors acknowledge that the LSNT model may suffer from some translation quality degradation compared to non-simultaneous translation approaches. This is a fundamental tradeoff in simultaneous translation - generating output before the full context is available can lead to less accurate translations.
The paper also does not explore the impact of the LSNT model on prosody transfer or the ability to convey important paralinguistic information in the translated output. This could be an important consideration for applications like simultaneous interpretation.
Further research could investigate techniques to better balance the latency-quality tradeoff, or explore ways to preserve prosodic and expressive elements of the source speech in the simultaneous translation output.
Conclusion
The Label-Synchronous Neural Transducer (LSNT) proposed in this paper represents an important advance in end-to-end simultaneous speech translation. By generating translations in sync with the input speech, the LSNT model can provide faster, more responsive translation than traditional approaches.
While there may be some translation quality tradeoffs, the LSNT architecture demonstrates the potential for label-synchronous techniques to enable practical simultaneous translation systems. Further research in this area could lead to even more seamless and expressive simultaneous translation capabilities.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Label-Synchronous Neural Transducer for E2E Simultaneous Speech Translation
Keqi Deng, Philip C. Woodland
While the neural transducer is popular for online speech recognition, simultaneous speech translation (SST) requires both streaming and re-ordering capabilities. This paper presents the LS-Transducer-SST, a label-synchronous neural transducer for SST, which naturally possesses these two properties. The LS-Transducer-SST dynamically decides when to emit translation tokens based on an Auto-regressive Integrate-and-Fire (AIF) mechanism. A latency-controllable AIF is also proposed, which can control the quality-latency trade-off either only during decoding, or it can be used in both decoding and training. The LS-Transducer-SST can naturally utilise monolingual text-only data via its prediction network which helps alleviate the key issue of data sparsity for E2E SST. During decoding, a chunk-based incremental joint decoding technique is designed to refine and expand the search space. Experiments on the Fisher-CallHome Spanish (Es-En) and MuST-C En-De data show that the LS-Transducer-SST gives a better quality-latency trade-off than existing popular methods. For example, the LS-Transducer-SST gives a 3.1/2.9 point BLEU increase (Es-En/En-De) relative to CAAT at a similar latency and a 1.4 s reduction in average lagging latency with similar BLEU scores relative to Wait-k.
Read more6/10/2024

0
CMU's IWSLT 2024 Simultaneous Speech Translation System
Xi Xu, Siqi Ouyang, Brian Yan, Patrick Fernandes, William Chen, Lei Li, Graham Neubig, Shinji Watanabe
This paper describes CMU's submission to the IWSLT 2024 Simultaneous Speech Translation (SST) task for translating English speech to German text in a streaming manner. Our end-to-end speech-to-text (ST) system integrates the WavLM speech encoder, a modality adapter, and the Llama2-7B-Base model as the decoder. We employ a two-stage training approach: initially, we align the representations of speech and text, followed by full fine-tuning. Both stages are trained on MuST-c v2 data with cross-entropy loss. We adapt our offline ST model for SST using a simple fixed hold-n policy. Experiments show that our model obtains an offline BLEU score of 31.1 and a BLEU score of 29.5 under 2 seconds latency on the MuST-C-v2 tst-COMMON.
Read more8/15/2024

0
FASST: Fast LLM-based Simultaneous Speech Translation
Siqi Ouyang, Xi Xu, Chinmay Dandekar, Lei Li
Simultaneous speech translation (SST) takes streaming speech input and generates text translation on the fly. Existing methods either have high latency due to recomputation of input representations, or fall behind of offline ST in translation quality. In this paper, we propose FASST, a fast large language model based method for streaming speech translation. We propose blockwise-causal speech encoding and consistency mask, so that streaming speech input can be encoded incrementally without recomputation. Furthermore, we develop a two-stage training strategy to optimize FASST for simultaneous inference. We evaluate FASST and multiple strong prior models on MuST-C dataset. Experiment results show that FASST achieves the best quality-latency trade-off. It outperforms the previous best model by an average of 1.5 BLEU under the same latency for English to Spanish translation.
Read more8/20/2024
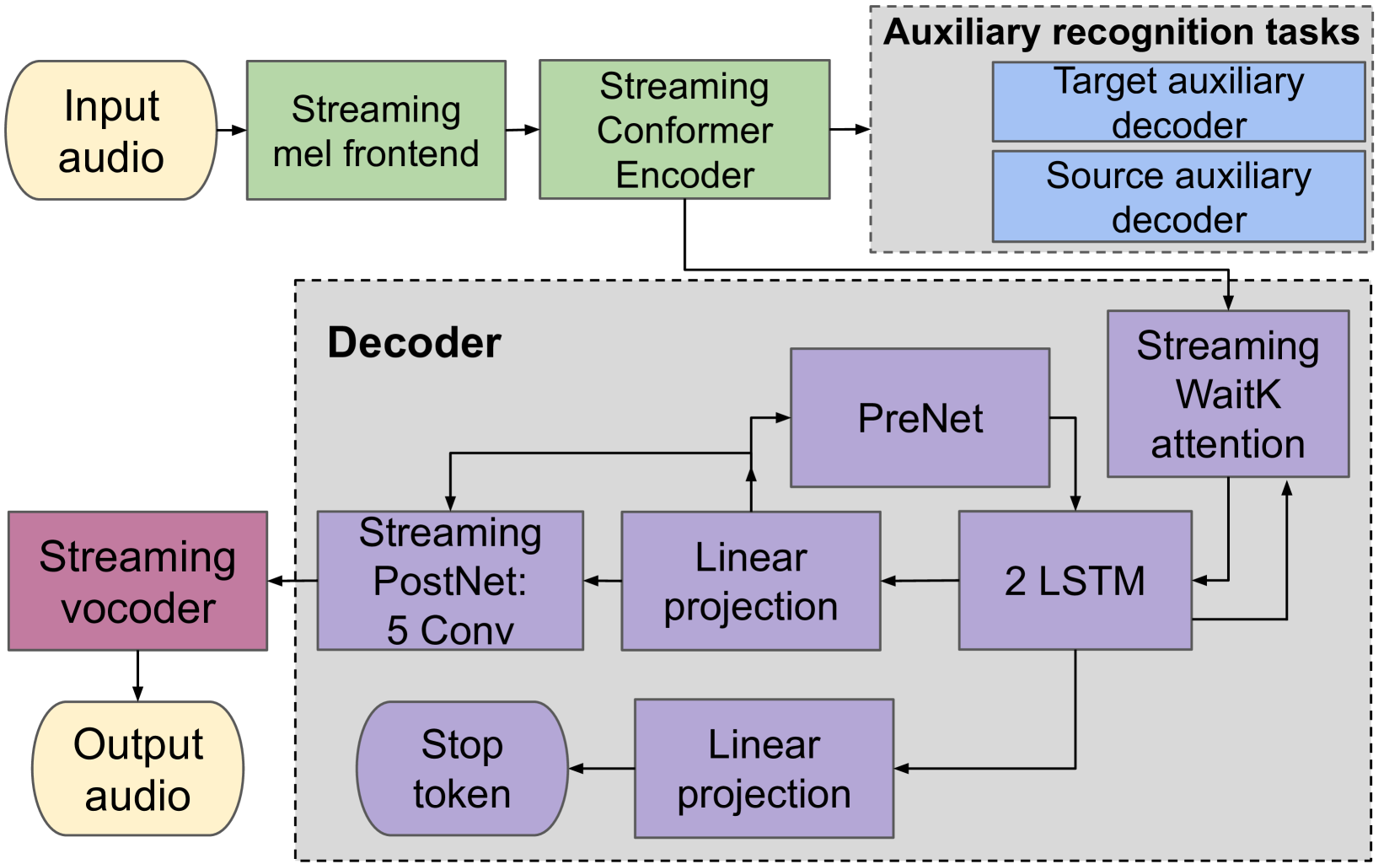
0
SimulTron: On-Device Simultaneous Speech to Speech Translation
Alex Agranovich, Eliya Nachmani, Oleg Rybakov, Yifan Ding, Ye Jia, Nadav Bar, Heiga Zen, Michelle Tadmor Ramanovich
Simultaneous speech-to-speech translation (S2ST) holds the promise of breaking down communication barriers and enabling fluid conversations across languages. However, achieving accurate, real-time translation through mobile devices remains a major challenge. We introduce SimulTron, a novel S2ST architecture designed to tackle this task. SimulTron is a lightweight direct S2ST model that uses the strengths of the Translatotron framework while incorporating key modifications for streaming operation, and an adjustable fixed delay. Our experiments show that SimulTron surpasses Translatotron 2 in offline evaluations. Furthermore, real-time evaluations reveal that SimulTron improves upon the performance achieved by Translatotron 1. Additionally, SimulTron achieves superior BLEU scores and latency compared to previous real-time S2ST method on the MuST-C dataset. Significantly, we have successfully deployed SimulTron on a Pixel 7 Pro device, show its potential for simultaneous S2ST on-device.
Read more6/5/2024