LaMDA: Large Model Fine-Tuning via Spectrally Decomposed Low-Dimensional Adaptation

0
Sign in to get full access
Overview
- The paper introduces a novel fine-tuning technique called LaMDA (Large Model Fine-Tuning via Spectrally Decomposed Low-Dimensional Adaptation) for large language models.
- LaMDA aims to adapt large pre-trained models to specific tasks or domains while preserving the original model's performance on other tasks.
- The key idea behind LaMDA is to decompose the model's parameters into a low-dimensional subspace, which is then fine-tuned, while the remainder of the parameters are kept frozen.
- This approach allows for efficient fine-tuning of large models without catastrophic forgetting or significant increases in model size.
Plain English Explanation
LaMDA is a new way to fine-tune large language models, like LORA or OLORA, to specific tasks or domains. The key idea is to focus the fine-tuning on a small, low-dimensional part of the model, while leaving the rest of the model unchanged.
Imagine you have a large, pre-trained language model that can do many different things, like answering questions, translating text, or generating stories. If you want to use this model for a specific task, like customer service chatbots, you usually need to fine-tune the entire model on the new task data. This can be time-consuming and may cause the model to forget how to do its original tasks well.
With LaMDA, the researchers found a way to fine-tune just a small part of the model, leaving the rest unchanged. This allows the model to learn the new task without losing its original capabilities. It's like teaching a smart assistant a new skill, like booking appointments, without forgetting how to do its other tasks, like answering questions or setting reminders.
The researchers achieved this by decomposing the model's parameters into a low-dimensional subspace that captures the task-specific information, and a high-dimensional subspace that retains the model's general knowledge. During fine-tuning, only the low-dimensional subspace is updated, while the rest of the model remains frozen.
This approach, called LORA, OLORA, LORA-LAND, or ALORA, has been shown to be efficient and effective, allowing large language models to be quickly adapted to new tasks without significant increases in model size or catastrophic forgetting of their original capabilities.
Technical Explanation
The key technical components of LaMDA are:
-
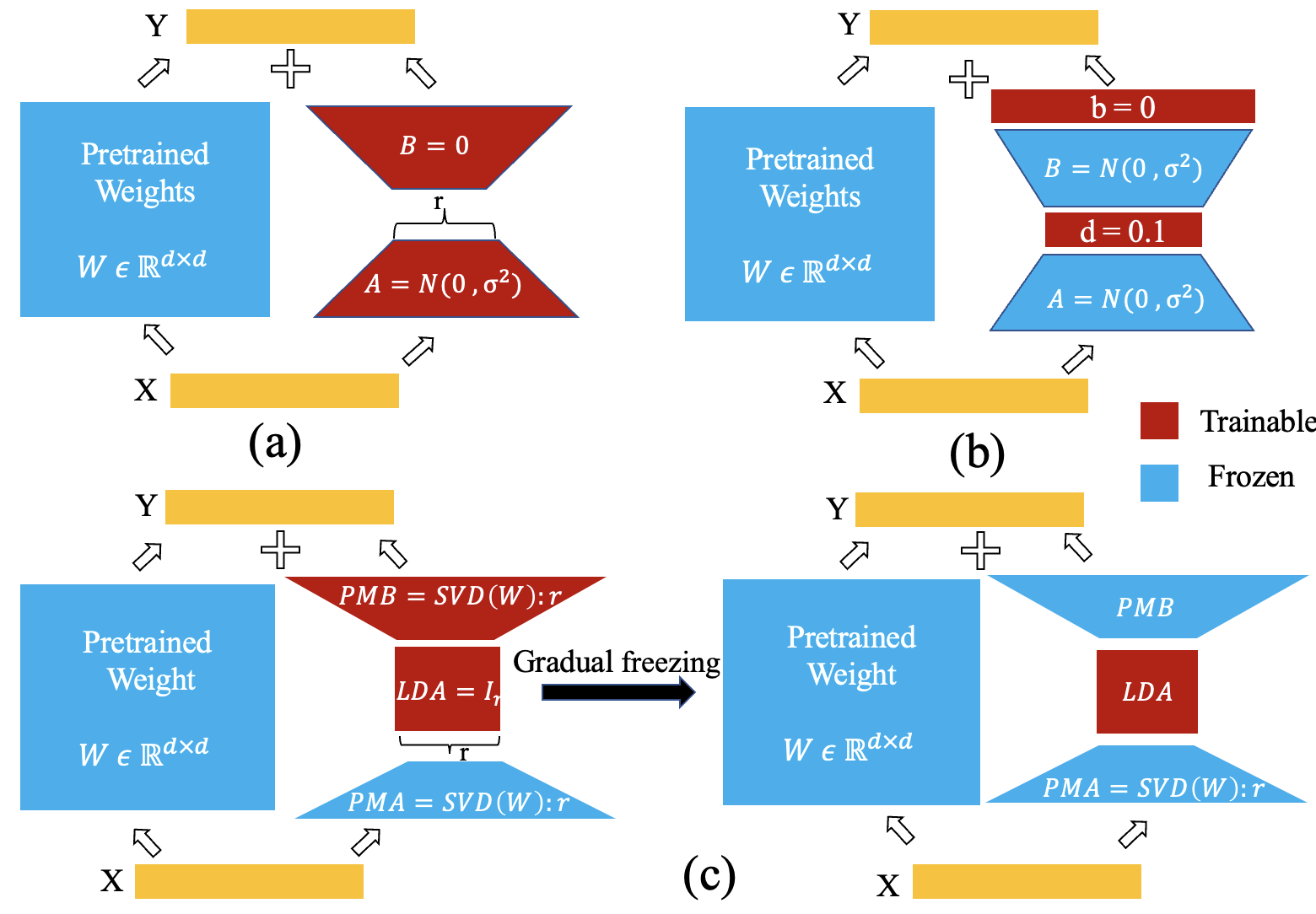
Spectral Decomposition: The model's parameters are decomposed into a low-dimensional subspace and a high-dimensional subspace using a singular value decomposition (SVD) approach. This allows the model to be efficiently adapted to new tasks.
-
Low-Dimensional Adaptation: During fine-tuning, only the low-dimensional subspace is updated, while the high-dimensional subspace is kept frozen. This preserves the model's general knowledge and prevents catastrophic forgetting.
-
Task-Specific Projection: The input and output of the model are projected onto the low-dimensional subspace during fine-tuning, ensuring that the adaptation is focused on the task-specific components.
-
Efficient Optimization: The researchers use a specialized optimization technique, called DORA, to efficiently update the low-dimensional subspace while keeping the rest of the model frozen.
The experiments in the paper demonstrate that LaMDA can achieve strong performance on a variety of tasks while requiring significantly fewer parameters to be updated compared to standard fine-tuning approaches. This makes LaMDA particularly useful for adapting large, pre-trained language models to specific applications without sacrificing their general capabilities.
Critical Analysis
The paper provides a compelling and well-designed approach to fine-tuning large language models. The key strengths of LaMDA include:
- Efficiency: By updating only a small, low-dimensional subspace of the model, LaMDA can fine-tune large models with significantly fewer parameters, making the process more efficient and scalable.
- Preservation of General Knowledge: Keeping the high-dimensional subspace of the model frozen during fine-tuning helps preserve the model's general knowledge and prevents catastrophic forgetting.
- Broad Applicability: The LaMDA approach is applicable to a wide range of large language models and can be used for various fine-tuning tasks, as demonstrated by the experiments in the paper.
However, the paper also acknowledges some potential limitations and areas for further research:
- Task-Specific Subspace: The assumption that the task-specific information can be captured in a low-dimensional subspace may not hold for all types of tasks or domains, which could limit the effectiveness of LaMDA in certain scenarios.
- Interpretability: The paper does not provide much insight into the nature of the low-dimensional subspace and how it relates to the task-specific information, which could limit the interpretability and explainability of the approach.
- Scalability: While LaMDA is more efficient than standard fine-tuning, the computational and memory requirements of the spectral decomposition and low-dimensional adaptation may still be a concern for extremely large language models or resource-constrained environments.
Overall, the LaMDA approach is a promising and well-designed technique for fine-tuning large language models, and the paper presents a solid foundation for further research and development in this area.
Conclusion
The LaMDA paper introduces a novel fine-tuning technique that allows large language models to be efficiently adapted to specific tasks or domains without catastrophic forgetting or significant increases in model size. By decomposing the model's parameters into a low-dimensional, task-specific subspace and a high-dimensional, general-knowledge subspace, LaMDA can fine-tune the model while preserving its original capabilities.
The key contributions of LaMDA include its efficiency, ability to preserve general knowledge, and broad applicability across a range of large language models and tasks. While the paper acknowledges some potential limitations, such as the assumption of a task-specific low-dimensional subspace and the computational requirements of the spectral decomposition, the overall approach represents a significant advancement in the field of large language model fine-tuning.
As the demand for adaptable and efficient AI systems continues to grow, techniques like LaMDA will play an increasingly important role in enabling the widespread deployment of large language models in real-world applications. This research paves the way for further innovations in this area, with the potential to unlock new capabilities and applications for large-scale language AI.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
LaMDA: Large Model Fine-Tuning via Spectrally Decomposed Low-Dimensional Adaptation
Seyedarmin Azizi, Souvik Kundu, Massoud Pedram
Low-rank adaptation (LoRA) has become the default approach to fine-tune large language models (LLMs) due to its significant reduction in trainable parameters. However, trainable parameter demand for LoRA increases with increasing model embedding dimensions, leading to high compute costs. Additionally, its backward updates require storing high-dimensional intermediate activations and optimizer states, demanding high peak GPU memory. In this paper, we introduce large model fine-tuning via spectrally decomposed low-dimensional adaptation (LaMDA), a novel approach to fine-tuning large language models, which leverages low-dimensional adaptation to achieve significant reductions in trainable parameters and peak GPU memory footprint. LaMDA freezes a first projection matrix (PMA) in the adaptation path while introducing a low-dimensional trainable square matrix, resulting in substantial reductions in trainable parameters and peak GPU memory usage. LaMDA gradually freezes a second projection matrix (PMB) during the early fine-tuning stages, reducing the compute cost associated with weight updates to enhance parameter efficiency further. We also present an enhancement, LaMDA++, incorporating a ``lite-weight adaptive rank allocation for the LoRA path via normalized spectrum analysis of pre-trained model weights. We evaluate LaMDA/LaMDA++ across various tasks, including natural language understanding with the GLUE benchmark, text summarization, natural language generation, and complex reasoning on different LLMs. Results show that LaMDA matches or surpasses the performance of existing alternatives while requiring up to 17.7x fewer parameter updates and up to 1.32x lower peak GPU memory usage during fine-tuning. Code will be publicly available.
Read more6/19/2024
💬
12
LQ-LoRA: Low-rank Plus Quantized Matrix Decomposition for Efficient Language Model Finetuning
Han Guo, Philip Greengard, Eric P. Xing, Yoon Kim
We propose a simple approach for memory-efficient adaptation of pretrained language models. Our approach uses an iterative algorithm to decompose each pretrained matrix into a high-precision low-rank component and a memory-efficient quantized component. During finetuning, the quantized component remains fixed and only the low-rank component is updated. We present an integer linear programming formulation of the quantization component which enables dynamic configuration of quantization parameters (e.g., bit-width, block size) for each matrix given an overall target memory budget. We further explore a data-aware version of the algorithm which uses an approximation of the Fisher information matrix to weight the reconstruction objective during matrix decomposition. Experiments on finetuning RoBERTa and LLaMA-2 (7B and 70B) demonstrate that our low-rank plus quantized matrix decomposition approach (LQ-LoRA) outperforms strong QLoRA and GPTQ-LoRA baselines and enables aggressive quantization to sub-3 bits with only minor performance degradations. When finetuned on a language modeling calibration dataset, LQ-LoRA can also be used for model compression; in this setting our 2.75-bit LLaMA-2-70B model (which has 2.85 bits on average when including the low-rank components and requires 27GB of GPU memory) performs respectably compared to the 16-bit baseline.
Read more8/28/2024
🌀
0
LoRA-XS: Low-Rank Adaptation with Extremely Small Number of Parameters
Klaudia Ba{l}azy, Mohammadreza Banaei, Karl Aberer, Jacek Tabor
The recent trend in scaling language models has led to a growing demand for parameter-efficient tuning (PEFT) methods such as LoRA (Low-Rank Adaptation). LoRA consistently matches or surpasses the full fine-tuning baseline with fewer parameters. However, handling numerous task-specific or user-specific LoRA modules on top of a base model still presents significant storage challenges. To address this, we introduce LoRA-XS (Low-Rank Adaptation with eXtremely Small number of parameters), a novel approach leveraging Singular Value Decomposition (SVD) for parameter-efficient fine-tuning. LoRA-XS introduces a small r x r weight matrix between frozen LoRA matrices, which are constructed by SVD of the original weight matrix. Training only r x r weight matrices ensures independence from model dimensions, enabling more parameter-efficient fine-tuning, especially for larger models. LoRA-XS achieves a remarkable reduction of trainable parameters by over 100x in 7B models compared to LoRA. Our benchmarking across various scales, including GLUE, GSM8k, and MATH benchmarks, shows that our approach outperforms LoRA and recent state-of-the-art approaches like VeRA in terms of parameter efficiency while maintaining competitive performance.
Read more5/29/2024

0
Enhancing Parameter Efficiency and Generalization in Large-Scale Models: A Regularized and Masked Low-Rank Adaptation Approach
Yuzhu Mao, Siqi Ping, Zihao Zhao, Yang Liu, Wenbo Ding
Large pre-trained models, such as large language models (LLMs), present significant resource challenges for fine-tuning due to their extensive parameter sizes, especially for applications in mobile systems. To address this, Low-Rank Adaptation (LoRA) has been developed to reduce resource consumption while maintaining satisfactory fine-tuning results. Despite its effectiveness, the original LoRA method faces challenges of suboptimal performance and overfitting. This paper investigates the intrinsic dimension of the matrix updates approximated by the LoRA method and reveals the performance benefits of increasing this intrinsic dimension. By employing regularization and a gradient masking method that encourages higher intrinsic dimension, the proposed method, termed Regularized and Masked LoRA (RM-LoRA), achieves superior generalization performance with the same or lower trainable parameter budget compared to the original LoRA and its latest variants across various open-source vision and language datasets.
Read more7/18/2024