LAMPAT: Low-Rank Adaption for Multilingual Paraphrasing Using Adversarial Training
2401.04348
0
0
Abstract
Paraphrases are texts that convey the same meaning while using different words or sentence structures. It can be used as an automatic data augmentation tool for many Natural Language Processing tasks, especially when dealing with low-resource languages, where data shortage is a significant problem. To generate a paraphrase in multilingual settings, previous studies have leveraged the knowledge from the machine translation field, i.e., forming a paraphrase through zero-shot machine translation in the same language. Despite good performance on human evaluation, those methods still require parallel translation datasets, thus making them inapplicable to languages that do not have parallel corpora. To mitigate that problem, we proposed the first unsupervised multilingual paraphrasing model, LAMPAT ($textbf{L}$ow-rank $textbf{A}$daptation for $textbf{M}$ultilingual $textbf{P}$araphrasing using $textbf{A}$dversarial $textbf{T}$raining), by which monolingual dataset is sufficient enough to generate a human-like and diverse sentence. Throughout the experiments, we found out that our method not only works well for English but can generalize on unseen languages as well. Data and code are available at https://github.com/VinAIResearch/LAMPAT.
Create account to get full access
Overview
- Proposes a low-rank adaptation method called LAMPAT for multilingual paraphrasing using adversarial training
- Develops a synthetic parallel corpus generation approach to address the lack of large-scale paraphrasing datasets in multiple languages
- Demonstrates the effectiveness of LAMPAT in improving paraphrasing performance across multiple languages compared to existing methods
Plain English Explanation
The paper introduces a new technique called LAMPAT (Low-Rank Adaption for Multilingual Paraphrasing Using Adversarial Training) that aims to improve the ability of language models to generate paraphrases in multiple languages. Paraphrasing - the task of rewriting a given text while preserving its meaning - is an important skill for language understanding and generation, but existing methods often struggle with generating high-quality paraphrases, especially across different languages.
LAMPAT works by adapting a pre-trained language model to the paraphrasing task in a space-efficient way using low-rank adaptation. This means the model only needs to learn a small number of additional parameters on top of the original model, rather than having to learn everything from scratch. The model is also trained using adversarial techniques, which helps it generate paraphrases that are indistinguishable from human-written text.
To address the lack of large paraphrasing datasets in multiple languages, the researchers also developed a method to automatically generate synthetic parallel corpora for training and evaluating paraphrasing models. This allows them to test LAMPAT on a wide range of languages and demonstrate its effectiveness compared to previous approaches.
Technical Explanation
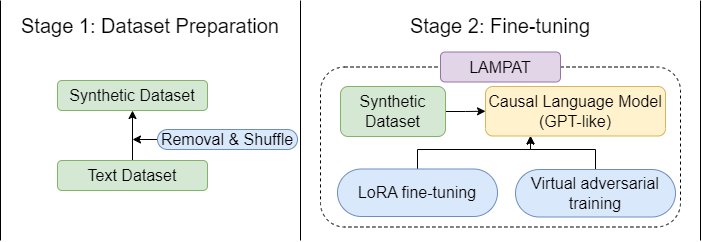
The paper first defines the problem of multilingual paraphrasing, where the goal is to generate paraphrases of a given input text in multiple target languages. To address the challenge of limited paraphrasing datasets, especially for non-English languages, the researchers propose a Synthetic Parallel Corpora generation approach. This involves using machine translation to translate text in a source language to multiple target languages, and then applying back-translation techniques to generate paraphrases of the original text.
The core of the paper is the LAMPAT model, which uses low-rank adaptation to fine-tune a pre-trained language model for the paraphrasing task. This means only a small number of additional parameters are learned on top of the original model, making the approach more efficient than training the entire model from scratch. The model is also trained using adversarial techniques, where a discriminator network tries to distinguish between real and generated paraphrases, forcing the paraphrasing model to produce more realistic outputs.
The researchers evaluate LAMPAT on a range of paraphrasing datasets in multiple languages, including English, German, and Chinese. They show that LAMPAT outperforms previous state-of-the-art methods in terms of paraphrasing quality and diversity, as measured by automatic metrics as well as human evaluation. They also analyze the impact of different components of the LAMPAT model, such as the low-rank adaptation and adversarial training, on its performance.
Critical Analysis
The paper makes a strong contribution by addressing the challenge of multilingual paraphrasing, which is an important yet understudied problem in natural language processing. The synthetic parallel corpus generation approach is a clever way to overcome the lack of large-scale paraphrasing datasets in multiple languages, and the LAMPAT model demonstrates state-of-the-art performance on this task.
However, the paper does not discuss potential limitations or ethical considerations of the research. For example, while the synthetic corpus generation method is useful for training and evaluation, it is not clear how the quality and diversity of the generated paraphrases compares to human-written text. There may also be concerns about biases or harmful content being amplified in the synthetic data.
Additionally, the paper focuses on improving paraphrasing performance using automatic metrics, but does not address the potential societal impacts of more advanced paraphrasing technology. For instance, such systems could be misused for plagiarism or to spread misinformation. Further research is needed to understand and mitigate these risks.
Conclusion
The LAMPAT method proposed in this paper represents an important step forward in multilingual paraphrasing, a crucial task for language understanding and generation. By leveraging low-rank adaptation and adversarial training, the researchers have developed a space-efficient and high-performing paraphrasing model that can be applied across a variety of languages. The synthetic parallel corpus generation approach is also a valuable contribution, as it helps address the lack of large-scale paraphrasing datasets.
However, the paper could be strengthened by a more thorough discussion of the limitations and potential risks of the proposed techniques. As natural language processing systems become more advanced, it is crucial to consider the broader societal implications of these technologies and ensure they are developed and deployed responsibly.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Enforcing Paraphrase Generation via Controllable Latent Diffusion
Wei Zou, Ziyuan Zhuang, Shujian Huang, Jia Liu, Jiajun Chen
0
0
Paraphrase generation aims to produce high-quality and diverse utterances of a given text. Though state-of-the-art generation via the diffusion model reconciles generation quality and diversity, textual diffusion suffers from a truncation issue that hinders efficiency and quality control. In this work, we propose textit{L}atent textit{D}iffusion textit{P}araphraser~(LDP), a novel paraphrase generation by modeling a controllable diffusion process given a learned latent space. LDP achieves superior generation efficiency compared to its diffusion counterparts. It facilitates only input segments to enforce paraphrase semantics, which further improves the results without external features. Experiments show that LDP achieves improved and diverse paraphrase generation compared to baselines. Further analysis shows that our method is also helpful to other similar text generations and domain adaptations. Our code and data are available at https://github.com/NIL-zhuang/ld4pg.
4/16/2024

PlagBench: Exploring the Duality of Large Language Models in Plagiarism Generation and Detection
Jooyoung Lee, Toshini Agrawal, Adaku Uchendu, Thai Le, Jinghui Chen, Dongwon Lee
0
0
Recent literature has highlighted potential risks to academic integrity associated with large language models (LLMs), as they can memorize parts of training instances and reproduce them in the generated texts without proper attribution. In addition, given their capabilities in generating high-quality texts, plagiarists can exploit LLMs to generate realistic paraphrases or summaries indistinguishable from original work. In response to possible malicious use of LLMs in plagiarism, we introduce PlagBench, a comprehensive dataset consisting of 46.5K synthetic plagiarism cases generated using three instruction-tuned LLMs across three writing domains. The quality of PlagBench is ensured through fine-grained automatic evaluation for each type of plagiarism, complemented by human annotation. We then leverage our proposed dataset to evaluate the plagiarism detection performance of five modern LLMs and three specialized plagiarism checkers. Our findings reveal that GPT-3.5 tends to generates paraphrases and summaries of higher quality compared to Llama2 and GPT-4. Despite LLMs' weak performance in summary plagiarism identification, they can surpass current commercial plagiarism detectors. Overall, our results highlight the potential of LLMs to serve as robust plagiarism detection tools.
6/26/2024

AAdaM at SemEval-2024 Task 1: Augmentation and Adaptation for Multilingual Semantic Textual Relatedness
Miaoran Zhang, Mingyang Wang, Jesujoba O. Alabi, Dietrich Klakow
0
0
This paper presents our system developed for the SemEval-2024 Task 1: Semantic Textual Relatedness for African and Asian Languages. The shared task aims at measuring the semantic textual relatedness between pairs of sentences, with a focus on a range of under-represented languages. In this work, we propose using machine translation for data augmentation to address the low-resource challenge of limited training data. Moreover, we apply task-adaptive pre-training on unlabeled task data to bridge the gap between pre-training and task adaptation. For model training, we investigate both full fine-tuning and adapter-based tuning, and adopt the adapter framework for effective zero-shot cross-lingual transfer. We achieve competitive results in the shared task: our system performs the best among all ranked teams in both subtask A (supervised learning) and subtask C (cross-lingual transfer).
6/10/2024
💬
LlamaTurk: Adapting Open-Source Generative Large Language Models for Low-Resource Language
Cagri Toraman
0
0
Despite advancements in English-dominant generative large language models, further development is needed for low-resource languages to enhance global accessibility. The primary methods for representing these languages are monolingual and multilingual pretraining. Monolingual pretraining is expensive due to hardware requirements, and multilingual models often have uneven performance across languages. This study explores an alternative solution by adapting large language models, primarily trained on English, to low-resource languages. We assess various strategies, including continual training, instruction fine-tuning, task-specific fine-tuning, and vocabulary extension. The results show that continual training improves language comprehension, as reflected in perplexity scores, and task-specific tuning generally enhances performance of downstream tasks. However, extending the vocabulary shows no substantial benefits. Additionally, while larger models improve task performance with few-shot tuning, multilingual models perform worse than their monolingual counterparts when adapted.
5/14/2024