Enforcing Paraphrase Generation via Controllable Latent Diffusion
2404.08938
0
0
Abstract
Paraphrase generation aims to produce high-quality and diverse utterances of a given text. Though state-of-the-art generation via the diffusion model reconciles generation quality and diversity, textual diffusion suffers from a truncation issue that hinders efficiency and quality control. In this work, we propose textit{L}atent textit{D}iffusion textit{P}araphraser~(LDP), a novel paraphrase generation by modeling a controllable diffusion process given a learned latent space. LDP achieves superior generation efficiency compared to its diffusion counterparts. It facilitates only input segments to enforce paraphrase semantics, which further improves the results without external features. Experiments show that LDP achieves improved and diverse paraphrase generation compared to baselines. Further analysis shows that our method is also helpful to other similar text generations and domain adaptations. Our code and data are available at https://github.com/NIL-zhuang/ld4pg.
Create account to get full access
Overview
- This paper introduces a novel method for generating paraphrased text using a controllable latent diffusion model.
- The key idea is to learn a latent representation of the input text that can be manipulated to produce diverse paraphrases.
- The model is trained to generate paraphrases that preserve the semantic content while altering the surface form of the input.
- Experiments show the method outperforms existing paraphrase generation approaches on several benchmarks.
Plain English Explanation
The paper presents a new way to automatically create paraphrased versions of a given text. Paraphrasing is the process of expressing the same idea using different words or phrasing.
The core of the approach is a neural network model that learns to represent the input text in a special "latent" space. This latent representation captures the underlying meaning of the text, but abstracts away the specific words and grammar used.
The model is then trained to manipulate this latent representation in controlled ways, in order to generate new text that conveys the same core meaning but uses different language. This allows the model to produce diverse paraphrases of the original input.
The key innovation is the use of a diffusion model - a type of deep learning model that can gradually transform one representation into another. In this case, the diffusion model learns to transform the latent representation of the input text into new latent representations that correspond to valid paraphrases.
Technical Explanation
The paper proposes a paraphrase generation method based on a latent diffusion model. The model consists of an encoder that maps the input text into a latent representation, and a diffusion-based decoder that generates paraphrased text from this latent space.
The key technical innovations are:
-
Controllable Latent Diffusion: The diffusion model is trained to manipulate the latent representation in a controlled way, allowing the generation of paraphrases that preserve semantic content while altering surface form.
-
Paraphrase-Specific Pre-training: The model is pre-trained on a large corpus of paraphrase data, enabling it to learn effective representations and generation strategies for this task.
-
Latent Space Regularization: The model incorporates regularization terms that encourage the latent space to capture semantically meaningful information and promote diversity in the generated paraphrases.
Experiments on several paraphrase benchmarks show that this approach outperforms existing paraphrase generation methods in terms of semantic preservation, lexical diversity, and other metrics. The authors also demonstrate the model's ability to control specific attributes of the generated paraphrases, such as sentence length and sentiment.
Critical Analysis
The paper presents a compelling approach to paraphrase generation that leverages the representational power of latent diffusion models. By learning to manipulate the latent space in a controlled way, the model is able to generate diverse paraphrases that preserve the core meaning of the input text.
One potential limitation is the reliance on a large corpus of paraphrase data for pre-training. In practice, such datasets may not always be available, especially for specialized domains. It would be interesting to see how the model performs with limited training data or in a few-shot learning setting.
Additionally, the paper does not extensively explore the model's ability to handle longer or more complex input texts. The experiments focus on relatively short sentences, and it's unclear how well the approach would scale to longer passages or more nuanced language.
Finally, while the authors discuss potential applications of the technology, such as text simplification and dialogue generation, they do not provide a deeper analysis of the societal implications or potential misuse of such a system. As with any advanced language model, there are concerns around bias, fairness, and the unintended consequences of widespread deployment.
Conclusion
This paper presents a novel approach to paraphrase generation using a controllable latent diffusion model. By learning to manipulate the latent representation of input text, the model can produce diverse paraphrases that preserve semantic content while altering surface form. The technical innovations and strong experimental results suggest this method could be a valuable tool for a variety of natural language processing applications. However, further research is needed to understand the limitations and potential societal impact of such language generation technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
DiffusionDialog: A Diffusion Model for Diverse Dialog Generation with Latent Space
Jianxiang Xiang, Zhenhua Liu, Haodong Liu, Yin Bai, Jia Cheng, Wenliang Chen
0
0
In real-life conversations, the content is diverse, and there exists the one-to-many problem that requires diverse generation. Previous studies attempted to introduce discrete or Gaussian-based continuous latent variables to address the one-to-many problem, but the diversity is limited. Recently, diffusion models have made breakthroughs in computer vision, and some attempts have been made in natural language processing. In this paper, we propose DiffusionDialog, a novel approach to enhance the diversity of dialogue generation with the help of diffusion model. In our approach, we introduce continuous latent variables into the diffusion model. The problem of using latent variables in the dialog task is how to build both an effective prior of the latent space and an inferring process to obtain the proper latent given the context. By combining the encoder and latent-based diffusion model, we encode the response's latent representation in a continuous space as the prior, instead of fixed Gaussian distribution or simply discrete ones. We then infer the latent by denoising step by step with the diffusion model. The experimental results show that our model greatly enhances the diversity of dialog responses while maintaining coherence. Furthermore, in further analysis, we find that our diffusion model achieves high inference efficiency, which is the main challenge of applying diffusion models in natural language processing.
4/11/2024
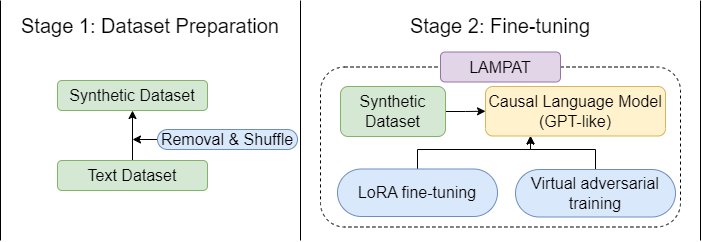
LAMPAT: Low-Rank Adaption for Multilingual Paraphrasing Using Adversarial Training
Khoi M. Le, Trinh Pham, Tho Quan, Anh Tuan Luu
0
0
Paraphrases are texts that convey the same meaning while using different words or sentence structures. It can be used as an automatic data augmentation tool for many Natural Language Processing tasks, especially when dealing with low-resource languages, where data shortage is a significant problem. To generate a paraphrase in multilingual settings, previous studies have leveraged the knowledge from the machine translation field, i.e., forming a paraphrase through zero-shot machine translation in the same language. Despite good performance on human evaluation, those methods still require parallel translation datasets, thus making them inapplicable to languages that do not have parallel corpora. To mitigate that problem, we proposed the first unsupervised multilingual paraphrasing model, LAMPAT ($textbf{L}$ow-rank $textbf{A}$daptation for $textbf{M}$ultilingual $textbf{P}$araphrasing using $textbf{A}$dversarial $textbf{T}$raining), by which monolingual dataset is sufficient enough to generate a human-like and diverse sentence. Throughout the experiments, we found out that our method not only works well for English but can generalize on unseen languages as well. Data and code are available at https://github.com/VinAIResearch/LAMPAT.
6/26/2024
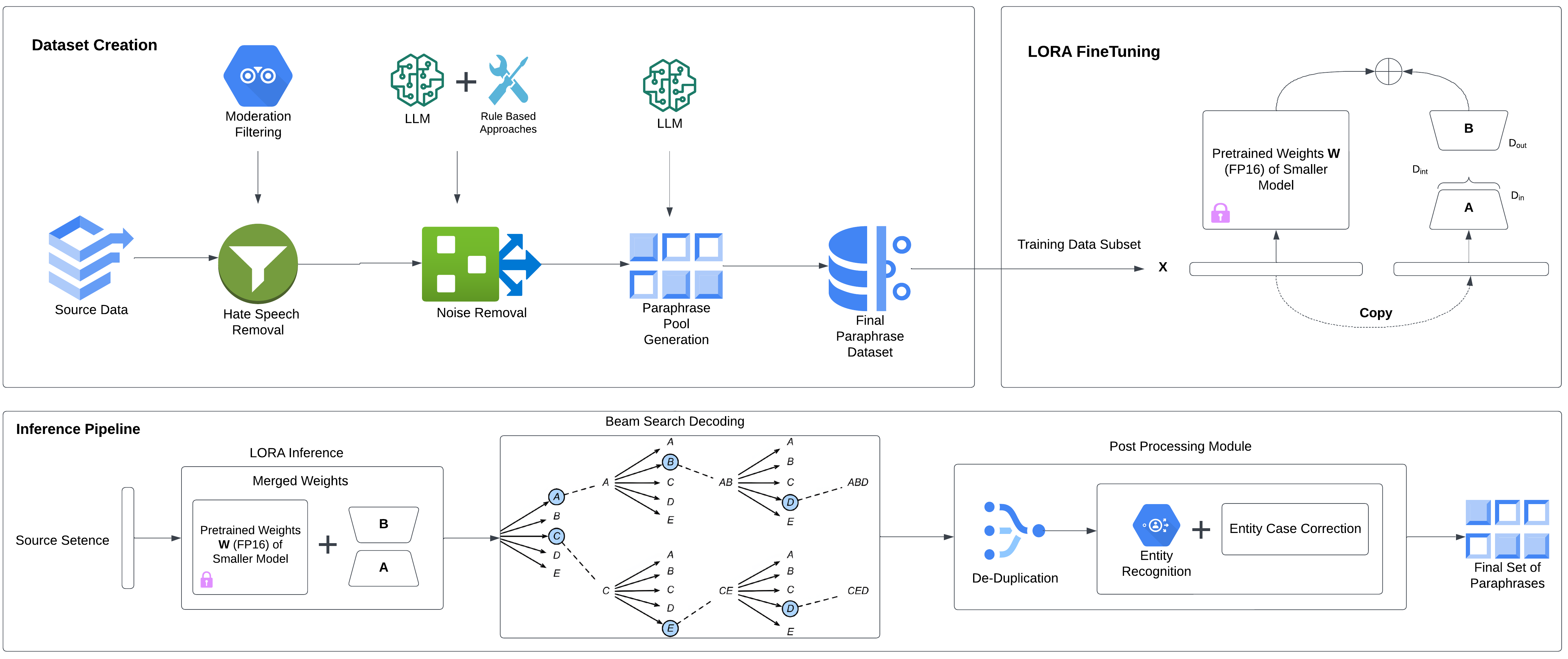
Parameter Efficient Diverse Paraphrase Generation Using Sequence-Level Knowledge Distillation
Lasal Jayawardena, Prasan Yapa
0
0
Over the past year, the field of Natural Language Generation (NLG) has experienced an exponential surge, largely due to the introduction of Large Language Models (LLMs). These models have exhibited the most effective performance in a range of domains within the Natural Language Processing and Generation domains. However, their application in domain-specific tasks, such as paraphrasing, presents significant challenges. The extensive number of parameters makes them difficult to operate on commercial hardware, and they require substantial time for inference, leading to high costs in a production setting. In this study, we tackle these obstacles by employing LLMs to develop three distinct models for the paraphrasing field, applying a method referred to as sequence-level knowledge distillation. These distilled models are capable of maintaining the quality of paraphrases generated by the LLM. They demonstrate faster inference times and the ability to generate diverse paraphrases of comparable quality. A notable characteristic of these models is their ability to exhibit syntactic diversity while also preserving lexical diversity, features previously uncommon due to existing data quality issues in datasets and not typically observed in neural-based approaches. Human evaluation of our models shows that there is only a 4% drop in performance compared to the LLM teacher model used in the distillation process, despite being 1000 times smaller. This research provides a significant contribution to the NLG field, offering a more efficient and cost-effective solution for paraphrasing tasks.
4/22/2024
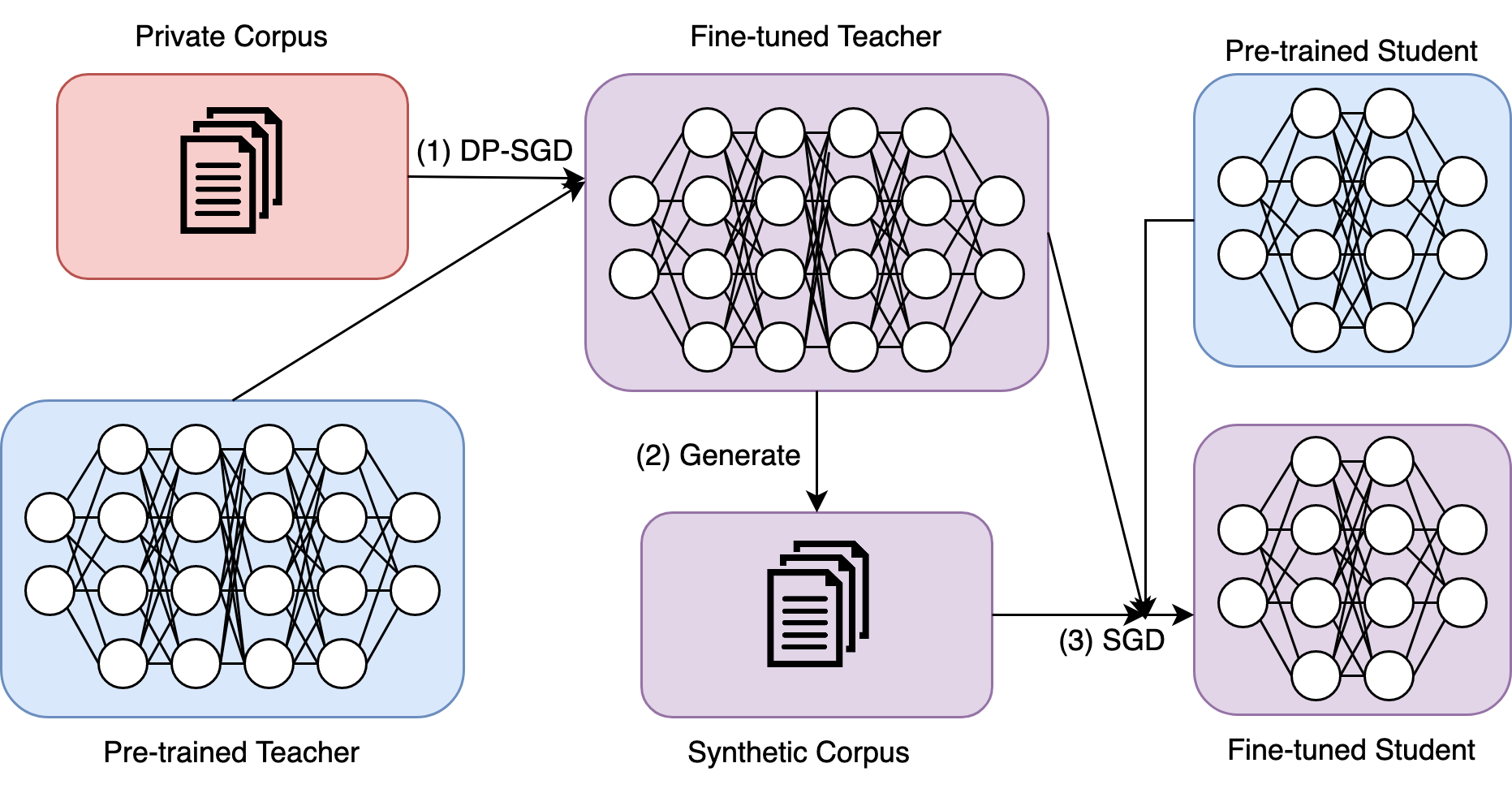
Differentially Private Knowledge Distillation via Synthetic Text Generation
James Flemings, Murali Annavaram
0
0
Large Language models (LLMs) are achieving state-of-the-art performance in many different downstream tasks. However, the increasing urgency of data privacy puts pressure on practitioners to train LLMs with Differential Privacy (DP) on private data. Concurrently, the exponential growth in parameter size of LLMs necessitates model compression before deployment of LLMs on resource-constrained devices or latency-sensitive applications. Differential privacy and model compression generally must trade off utility loss to achieve their objectives. Moreover, simultaneously applying both schemes can compound the utility degradation. To this end, we propose DistilDP: a novel differentially private knowledge distillation algorithm that exploits synthetic data generated by a differentially private teacher LLM. The knowledge of a teacher LLM is transferred onto the student in two ways: one way from the synthetic data itself -- the hard labels, and the other way by the output distribution of the teacher evaluated on the synthetic data -- the soft labels. Furthermore, if the teacher and student share a similar architectural structure, we can further distill knowledge by aligning the hidden representations between both. Our experimental results demonstrate that DistilDP can substantially improve the utility over existing baselines, at least $9.0$ PPL on the Big Patent dataset, with strong privacy parameters, $epsilon=2$. These promising results progress privacy-preserving compression of autoregressive LLMs. Our code can be accessed here: https://github.com/james-flemings/dp_compress.
6/6/2024