Language-Conditioned Offline RL for Multi-Robot Navigation

0

Sign in to get full access
Overview
- The paper explores a language-conditioned offline reinforcement learning (RL) approach for multi-robot navigation tasks.
- The proposed method uses natural language instructions to guide the robots' decision-making during navigation.
- The authors train the RL model on a large dataset of human-robot interactions, allowing the robots to learn from past experience.
- The system is designed to enable robots to navigate more effectively and robustly in complex, real-world environments.
Plain English Explanation
The research paper presents a new way for robots to learn how to navigate through different environments. The key idea is to use language instructions to guide the robots' decision-making process. For example, a robot might receive a command like "Go to the kitchen and avoid obstacles on the way."
The researchers trained the robots using a large dataset of previous interactions between humans and robots. This allows the robots to learn from past experiences and get better at following language-based instructions. The goal is to help robots navigate more effectively and safely in complex, real-world settings, where they may encounter a variety of obstacles and challenges.
The language-based approach is important because it allows the robots to understand high-level commands and adapt their behavior accordingly, rather than simply following pre-programmed routes. This should make the robots more flexible and able to handle unexpected situations.
Technical Explanation
The paper introduces a language-conditioned offline reinforcement learning (RL) approach for multi-robot navigation tasks. The key innovation is the use of natural language instructions to guide the robots' decision-making during navigation.
The authors train the RL model on a large dataset of human-robot interactions, allowing the robots to learn from past experience. The dataset includes a variety of navigation scenarios, with corresponding language instructions and robot actions.
During deployment, the robots receive natural language commands that are conditioned on the current state of the environment. The RL model then uses this language input to select appropriate actions to navigate through the environment.
The experiments demonstrate that the language-conditioned RL approach outperforms traditional RL methods in terms of navigation efficiency and robustness to environmental changes.
Critical Analysis
The paper presents an interesting and promising approach to multi-robot navigation, but there are a few potential limitations and areas for further research:
-
Limited Evaluation Environments: The experiments were conducted in simulated environments, and it's unclear how well the system would perform in more complex, real-world settings. Further testing in diverse, physical environments would be helpful to fully assess the system's capabilities.
-
Language Generalization: The paper does not explicitly address how the system would handle language instructions that are more complex or differ significantly from the training data. Evaluating the system's ability to generalize to novel language inputs would be an important next step.
-
Scalability to Large Teams: The paper focuses on a single-robot scenario, but it's unclear how the approach would scale to larger teams of robots. Exploring coordination mechanisms for language-guided multi-robot navigation could be a valuable area of future research.
Conclusion
The language-conditioned offline RL approach presented in this paper is a promising step towards more flexible and adaptable multi-robot navigation systems. By leveraging natural language instructions to guide the robots' decision-making, the researchers have demonstrated improved navigation efficiency and robustness compared to traditional RL methods.
This work has the potential to contribute to the development of more intuitive and user-friendly robotic assistants that can operate effectively in complex, real-world environments. Further research on language generalization, multi-robot coordination, and real-world deployments could help unlock the full potential of this approach.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Language-Conditioned Offline RL for Multi-Robot Navigation
Steven Morad, Ajay Shankar, Jan Blumenkamp, Amanda Prorok
We present a method for developing navigation policies for multi-robot teams that interpret and follow natural language instructions. We condition these policies on embeddings from pretrained Large Language Models (LLMs), and train them via offline reinforcement learning with as little as 20 minutes of randomly-collected data. Experiments on a team of five real robots show that these policies generalize well to unseen commands, indicating an understanding of the LLM latent space. Our method requires no simulators or environment models, and produces low-latency control policies that can be deployed directly to real robots without finetuning. We provide videos of our experiments at https://sites.google.com/view/llm-marl.
Read more7/30/2024
0
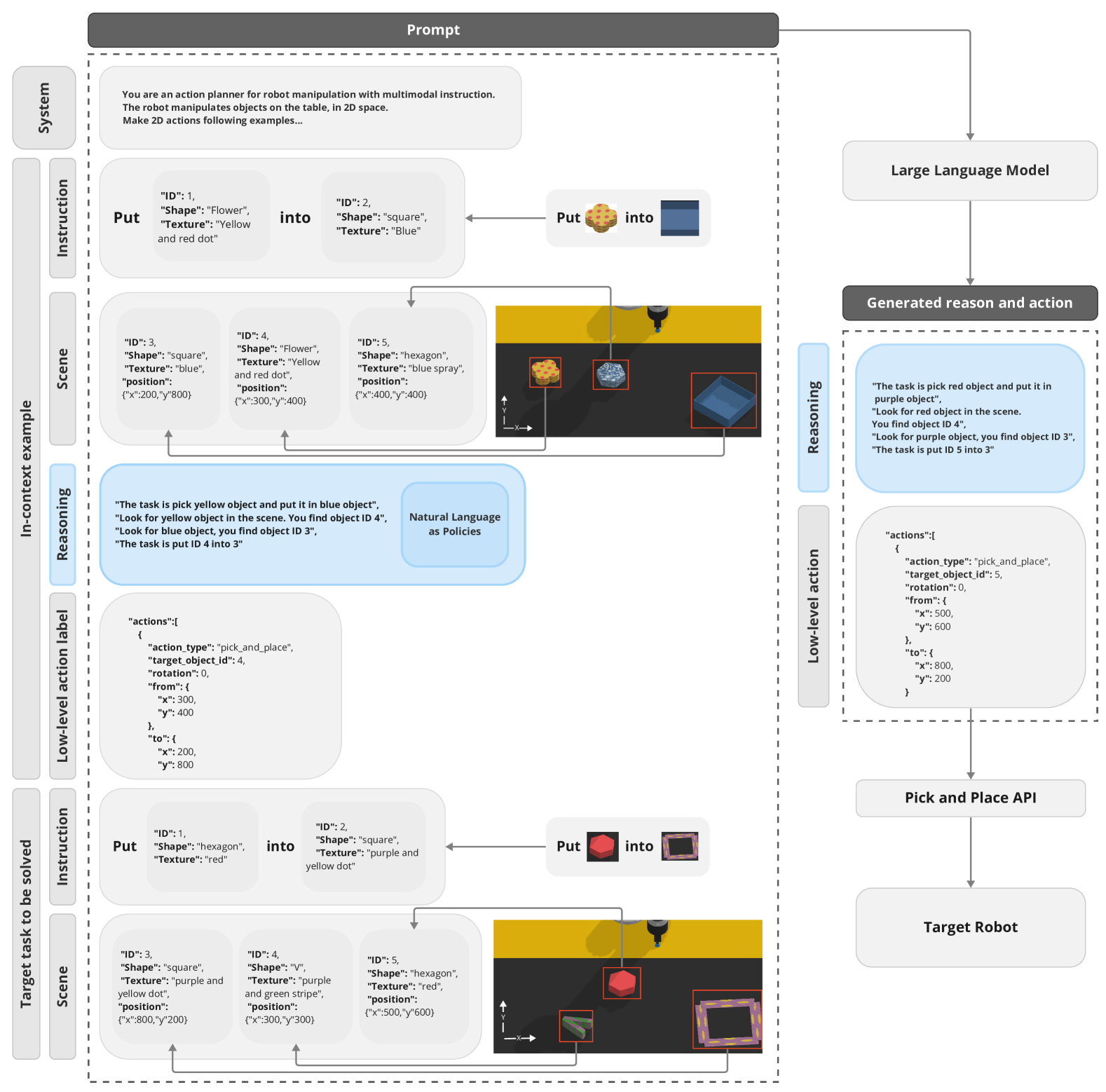
Natural Language as Policies: Reasoning for Coordinate-Level Embodied Control with LLMs
Yusuke Mikami, Andrew Melnik, Jun Miura, Ville Hautamaki
We demonstrate experimental results with LLMs that address robotics task planning problems. Recently, LLMs have been applied in robotics task planning, particularly using a code generation approach that converts complex high-level instructions into mid-level policy codes. In contrast, our approach acquires text descriptions of the task and scene objects, then formulates task planning through natural language reasoning, and outputs coordinate level control commands, thus reducing the necessity for intermediate representation code as policies with pre-defined APIs. Our approach is evaluated on a multi-modal prompt simulation benchmark, demonstrating that our prompt engineering experiments with natural language reasoning significantly enhance success rates compared to its absence. Furthermore, our approach illustrates the potential for natural language descriptions to transfer robotics skills from known tasks to previously unseen tasks. The project website: https://natural-language-as-policies.github.io/
Read more4/9/2024
💬
0
Large Language Models as Generalizable Policies for Embodied Tasks
Andrew Szot, Max Schwarzer, Harsh Agrawal, Bogdan Mazoure, Walter Talbott, Katherine Metcalf, Natalie Mackraz, Devon Hjelm, Alexander Toshev
We show that large language models (LLMs) can be adapted to be generalizable policies for embodied visual tasks. Our approach, called Large LAnguage model Reinforcement Learning Policy (LLaRP), adapts a pre-trained frozen LLM to take as input text instructions and visual egocentric observations and output actions directly in the environment. Using reinforcement learning, we train LLaRP to see and act solely through environmental interactions. We show that LLaRP is robust to complex paraphrasings of task instructions and can generalize to new tasks that require novel optimal behavior. In particular, on 1,000 unseen tasks it achieves 42% success rate, 1.7x the success rate of other common learned baselines or zero-shot applications of LLMs. Finally, to aid the community in studying language conditioned, massively multi-task, embodied AI problems we release a novel benchmark, Language Rearrangement, consisting of 150,000 training and 1,000 testing tasks for language-conditioned rearrangement. Video examples of LLaRP in unseen Language Rearrangement instructions are at https://llm-rl.github.io.
Read more4/17/2024

0
Grounding Language Models in Autonomous Loco-manipulation Tasks
Jin Wang, Nikos Tsagarakis
Humanoid robots with behavioral autonomy have consistently been regarded as ideal collaborators in our daily lives and promising representations of embodied intelligence. Compared to fixed-based robotic arms, humanoid robots offer a larger operational space while significantly increasing the difficulty of control and planning. Despite the rapid progress towards general-purpose humanoid robots, most studies remain focused on locomotion ability with few investigations into whole-body coordination and tasks planning, thus limiting the potential to demonstrate long-horizon tasks involving both mobility and manipulation under open-ended verbal instructions. In this work, we propose a novel framework that learns, selects, and plans behaviors based on tasks in different scenarios. We combine reinforcement learning (RL) with whole-body optimization to generate robot motions and store them into a motion library. We further leverage the planning and reasoning features of the large language model (LLM), constructing a hierarchical task graph that comprises a series of motion primitives to bridge lower-level execution with higher-level planning. Experiments in simulation and real-world using the CENTAURO robot show that the language model based planner can efficiently adapt to new loco-manipulation tasks, demonstrating high autonomy from free-text commands in unstructured scenes.
Read more9/4/2024