Language Grounded Multi-agent Communication for Ad-hoc Teamwork

0
Sign in to get full access
Overview
- Examines how language-grounded communication can improve multi-agent teamwork in ad-hoc scenarios
- Proposes a framework for learning communication policies that leverage natural language grounding
- Demonstrates improved coordination and task performance compared to baselines in simulated environments
Plain English Explanation
The paper explores how language-grounded communication can enhance the teamwork of multiple intelligent agents in dynamic, unplanned situations.
The key idea is to give the agents the ability to communicate using natural language that is grounded in their understanding of the environment and task. This allows them to coordinate more effectively compared to using predefined communication protocols or signals.
The framework they propose learns communication policies that leverage this language grounding. In simulated experiments, this approach demonstrated improved coordination and task performance compared to baseline methods that rely on more limited forms of communication.
Technical Explanation
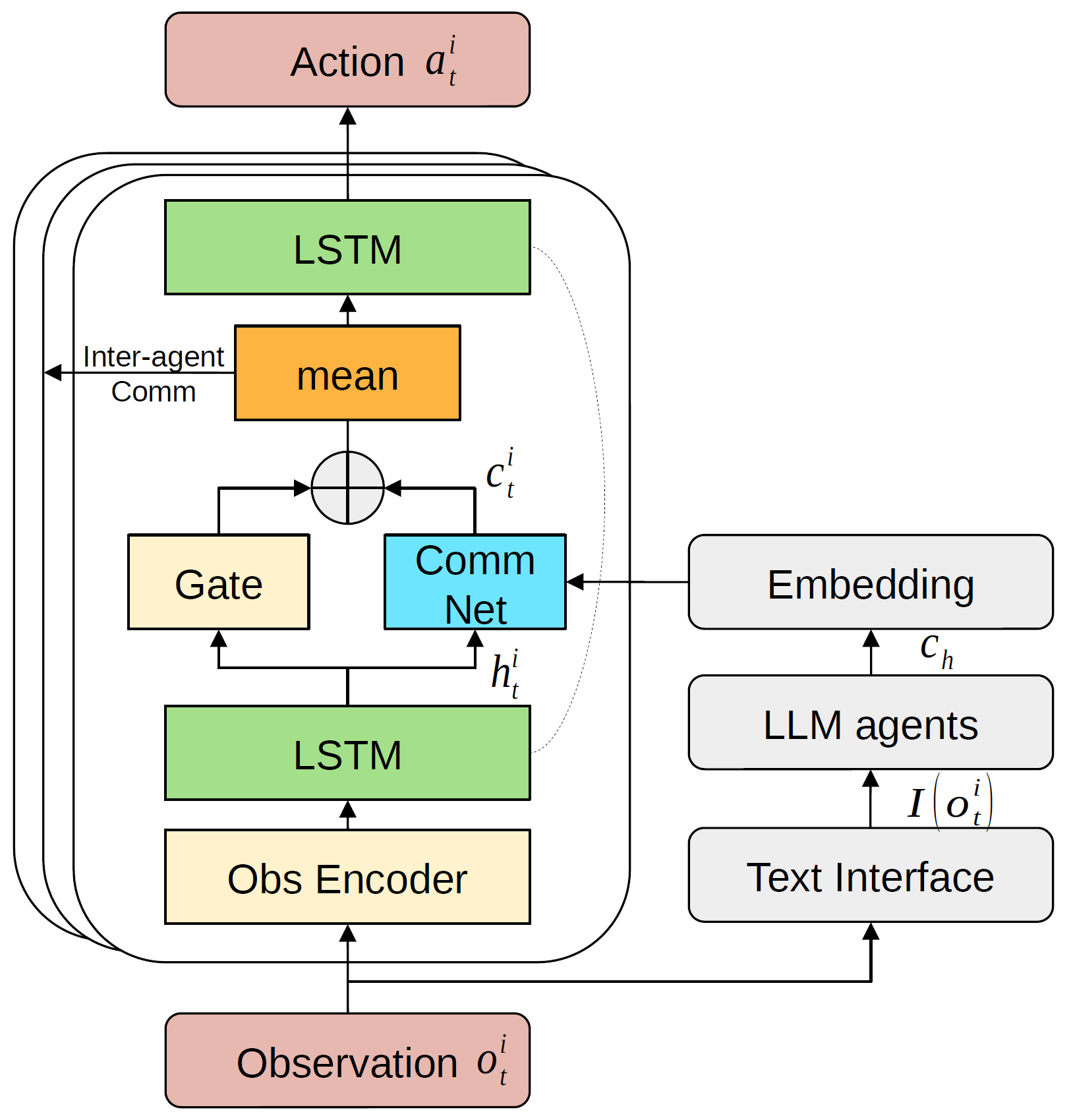
The paper presents a framework for multi-agent reinforcement learning that enables language-grounded communication. This allows agents to coordinate their actions by exchanging messages that are meaningful within the context of their shared environment and goals.
The key components include:
- Language Grounding: Agents learn to map their observations and actions to natural language expressions, allowing them to communicate in an intuitive way.
- Communication Policy: A neural network module that takes in the agents' individual states and generates relevant messages to share with teammates.
- Coordination Mechanism: Agents incorporate the received messages from teammates into their decision-making process to improve joint task performance.
The authors evaluate this approach in simulated multi-agent environments, demonstrating improved coordination and task completion compared to baselines that use more limited communication protocols.
Critical Analysis
The paper makes a convincing case for the benefits of language-grounded communication in multi-agent systems. The experiments show promising results, but the authors acknowledge some limitations:
- The environments and tasks used are still relatively simple, and further testing is needed to see how the approach scales to more complex, real-world scenarios.
- The communication policy is learned end-to-end, which may make it difficult to interpret and debug. Incorporating more structured or modular elements could improve transparency and controllability.
- The paper does not explore the impact of different levels of shared language understanding among the agents, which could be an important factor in more heterogeneous teams.
Despite these caveats, the research represents an important step towards developing more natural and effective communication capabilities for artificial agents working together in dynamic, ad-hoc teamwork situations.
Conclusion
This paper demonstrates how language-grounded communication can enhance the coordination and task performance of multi-agent systems in unplanned, ad-hoc scenarios. By enabling agents to exchange meaningful messages grounded in their shared understanding of the environment and objectives, the proposed framework shows promise for improving the collaborative capabilities of artificial agents working alongside humans or in complex, unpredictable settings.
The research highlights the value of developing communication abilities that go beyond predefined protocols and leverage the richness of natural language. As multi-agent systems become more prevalent, this work contributes to the ongoing effort to create more intelligent and collaborative artificial agents that can seamlessly integrate with human teams and adapt to dynamic, real-world situations.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Language Grounded Multi-agent Communication for Ad-hoc Teamwork
Huao Li, Hossein Nourkhiz Mahjoub, Behdad Chalaki, Vaishnav Tadiparthi, Kwonjoon Lee, Ehsan Moradi-Pari, Charles Michael Lewis, Katia P Sycara
Multi-Agent Reinforcement Learning (MARL) methods have shown promise in enabling agents to learn a shared communication protocol from scratch and accomplish challenging team tasks. However, the learned language is usually not interpretable to humans or other agents not co-trained together, limiting its applicability in ad-hoc teamwork scenarios. In this work, we propose a novel computational pipeline that aligns the communication space between MARL agents with an embedding space of human natural language by grounding agent communications on synthetic data generated by embodied Large Language Models (LLMs) in interactive teamwork scenarios. Our results demonstrate that introducing language grounding not only maintains task performance but also accelerates the emergence of communication. Furthermore, the learned communication protocols exhibit zero-shot generalization capabilities in ad-hoc teamwork scenarios with unseen teammates and novel task states. This work presents a significant step toward enabling effective communication and collaboration between artificial agents and humans in real-world teamwork settings.
Read more9/27/2024

0
When Robots Get Chatty: Grounding Multimodal Human-Robot Conversation and Collaboration
Philipp Allgeuer, Hassan Ali, Stefan Wermter
We investigate the use of Large Language Models (LLMs) to equip neural robotic agents with human-like social and cognitive competencies, for the purpose of open-ended human-robot conversation and collaboration. We introduce a modular and extensible methodology for grounding an LLM with the sensory perceptions and capabilities of a physical robot, and integrate multiple deep learning models throughout the architecture in a form of system integration. The integrated models encompass various functions such as speech recognition, speech generation, open-vocabulary object detection, human pose estimation, and gesture detection, with the LLM serving as the central text-based coordinating unit. The qualitative and quantitative results demonstrate the huge potential of LLMs in providing emergent cognition and interactive language-oriented control of robots in a natural and social manner.
Read more7/2/2024

0
Towards Collaborative Intelligence: Propagating Intentions and Reasoning for Multi-Agent Coordination with Large Language Models
Xihe Qiu, Haoyu Wang, Xiaoyu Tan, Chao Qu, Yujie Xiong, Yuan Cheng, Yinghui Xu, Wei Chu, Yuan Qi
Effective collaboration in multi-agent systems requires communicating goals and intentions between agents. Current agent frameworks often suffer from dependencies on single-agent execution and lack robust inter-module communication, frequently leading to suboptimal multi-agent reinforcement learning (MARL) policies and inadequate task coordination. To address these challenges, we present a framework for training large language models (LLMs) as collaborative agents to enable coordinated behaviors in cooperative MARL. Each agent maintains a private intention consisting of its current goal and associated sub-tasks. Agents broadcast their intentions periodically, allowing other agents to infer coordination tasks. A propagation network transforms broadcast intentions into teammate-specific communication messages, sharing relevant goals with designated teammates. The architecture of our framework is structured into planning, grounding, and execution modules. During execution, multiple agents interact in a downstream environment and communicate intentions to enable coordinated behaviors. The grounding module dynamically adapts comprehension strategies based on emerging coordination patterns, while feedback from execution agents influnces the planning module, enabling the dynamic re-planning of sub-tasks. Results in collaborative environment simulation demonstrate intention propagation reduces miscoordination errors by aligning sub-task dependencies between agents. Agents learn when to communicate intentions and which teammates require task details, resulting in emergent coordinated behaviors. This demonstrates the efficacy of intention sharing for cooperative multi-agent RL based on LLMs.
Read more7/18/2024
🏅
0
LLM-based Multi-Agent Reinforcement Learning: Current and Future Directions
Chuanneng Sun, Songjun Huang, Dario Pompili
In recent years, Large Language Models (LLMs) have shown great abilities in various tasks, including question answering, arithmetic problem solving, and poem writing, among others. Although research on LLM-as-an-agent has shown that LLM can be applied to Reinforcement Learning (RL) and achieve decent results, the extension of LLM-based RL to Multi-Agent System (MAS) is not trivial, as many aspects, such as coordination and communication between agents, are not considered in the RL frameworks of a single agent. To inspire more research on LLM-based MARL, in this letter, we survey the existing LLM-based single-agent and multi-agent RL frameworks and provide potential research directions for future research. In particular, we focus on the cooperative tasks of multiple agents with a common goal and communication among them. We also consider human-in/on-the-loop scenarios enabled by the language component in the framework.
Read more5/21/2024