Large Language Models as Markov Chains

3

Sign in to get full access
Overview
- Large language models (LLMs) are powerful AI systems that can generate human-like text.
- This paper explores how LLMs can be understood as Markov chains, a type of statistical model.
- The paper also discusses in-context learning (ICL), a technique used by LLMs to generate text.
Plain English Explanation
Markov Chains and Large Language Models
LLMs can be viewed as Markov chains - statistical models that predict the next state (in this case, the next word) based only on the current state (the current word or phrase), without considering the full history. This provides a way to understand how LLMs generate text.
In-Context Learning (ICL)
In-context learning (ICL) is a technique used by LLMs to generate text. LLMs use the provided context (the prompt or previous text) to inform their next prediction, rather than relying solely on their training data. This allows LLMs to adapt to the specific task or topic at hand.
Technical Explanation
Markov Chains and Large Language Models
The paper demonstrates how LLMs can be modeled as Markov chains. Markov chains are a type of statistical model that predict the next state (word) based only on the current state (word or phrase), without considering the full history. The authors show that this Markov property holds for LLMs, providing a framework for understanding their text generation process.
In-Context Learning (ICL)
The paper also discusses in-context learning (ICL), a technique used by LLMs to generate text. ICL allows LLMs to adapt their predictions based on the provided context (the prompt or previous text), rather than relying solely on their training data. This enables LLMs to be more flexible and task-specific in their text generation.
Critical Analysis
The paper provides a valuable theoretical framework for understanding LLMs as Markov chains, which can help researchers and developers better analyze and optimize these models. However, the paper does not address potential limitations of this view, such as the fact that LLMs may not always strictly adhere to the Markov property due to their complex internal mechanisms.
Similarly, the discussion of in-context learning (ICL) is insightful, but the paper could have delved deeper into the nuances and potential issues with this technique, such as the risk of LLMs overfitting to the provided context or generating biased or harmful content.
Conclusion
This paper offers a Markov chain perspective on LLMs and explores the role of in-context learning (ICL) in their text generation capabilities. While the theoretical framework is valuable, the paper could have provided a more comprehensive analysis of the limitations and potential issues with these approaches. Nevertheless, the insights presented in this work contribute to our understanding of the inner workings of large language models and may inform future research and development in this rapidly evolving field.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
3
Large Language Models as Markov Chains
Oussama Zekri, Ambroise Odonnat, Abdelhakim Benechehab, Linus Bleistein, Nicolas Boull'e, Ievgen Redko
Large language models (LLMs) have proven to be remarkably efficient, both across a wide range of natural language processing tasks and well beyond them. However, a comprehensive theoretical analysis of the origins of their impressive performance remains elusive. In this paper, we approach this challenging task by drawing an equivalence between generic autoregressive language models with vocabulary of size $T$ and context window of size $K$ and Markov chains defined on a finite state space of size $mathcal{O}(T^K)$. We derive several surprising findings related to the existence of a stationary distribution of Markov chains that capture the inference power of LLMs, their speed of convergence to it, and the influence of the temperature on the latter. We then prove pre-training and in-context generalization bounds and show how the drawn equivalence allows us to enrich their interpretation. Finally, we illustrate our theoretical guarantees with experiments on several recent LLMs to highlight how they capture the behavior observed in practice.
Read more10/4/2024
💬
0
Why Can Large Language Models Generate Correct Chain-of-Thoughts?
Rasul Tutunov, Antoine Grosnit, Juliusz Ziomek, Jun Wang, Haitham Bou-Ammar
This paper delves into the capabilities of large language models (LLMs), specifically focusing on advancing the theoretical comprehension of chain-of-thought prompting. We investigate how LLMs can be effectively induced to generate a coherent chain of thoughts. To achieve this, we introduce a two-level hierarchical graphical model tailored for natural language generation. Within this framework, we establish a compelling geometrical convergence rate that gauges the likelihood of an LLM-generated chain of thoughts compared to those originating from the true language. Our findings provide a theoretical justification for the ability of LLMs to produce the correct sequence of thoughts (potentially) explaining performance gains in tasks demanding reasoning skills.
Read more6/7/2024

0
LLMs learn governing principles of dynamical systems, revealing an in-context neural scaling law
Toni J. B. Liu, Nicolas Boull'e, Raphael Sarfati, Christopher J. Earls
Pretrained large language models (LLMs) are surprisingly effective at performing zero-shot tasks, including time-series forecasting. However, understanding the mechanisms behind such capabilities remains highly challenging due to the complexity of the models. We study LLMs' ability to extrapolate the behavior of dynamical systems whose evolution is governed by principles of physical interest. Our results show that LLaMA 2, a language model trained primarily on texts, achieves accurate predictions of dynamical system time series without fine-tuning or prompt engineering. Moreover, the accuracy of the learned physical rules increases with the length of the input context window, revealing an in-context version of neural scaling law. Along the way, we present a flexible and efficient algorithm for extracting probability density functions of multi-digit numbers directly from LLMs.
Read more10/10/2024
0
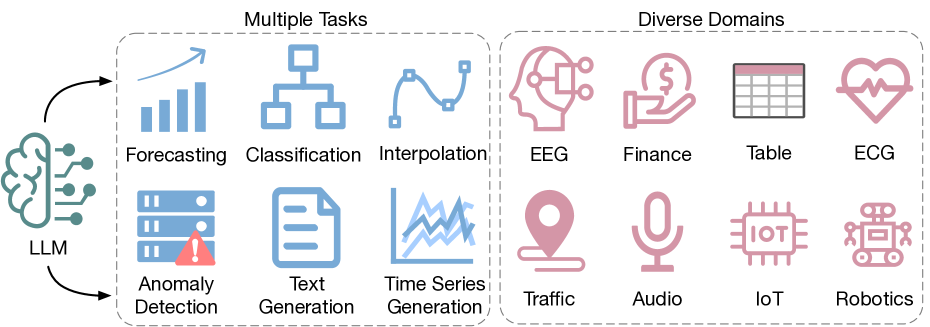
Large Language Models for Time Series: A Survey
Xiyuan Zhang, Ranak Roy Chowdhury, Rajesh K. Gupta, Jingbo Shang
Large Language Models (LLMs) have seen significant use in domains such as natural language processing and computer vision. Going beyond text, image and graphics, LLMs present a significant potential for analysis of time series data, benefiting domains such as climate, IoT, healthcare, traffic, audio and finance. This survey paper provides an in-depth exploration and a detailed taxonomy of the various methodologies employed to harness the power of LLMs for time series analysis. We address the inherent challenge of bridging the gap between LLMs' original text data training and the numerical nature of time series data, and explore strategies for transferring and distilling knowledge from LLMs to numerical time series analysis. We detail various methodologies, including (1) direct prompting of LLMs, (2) time series quantization, (3) aligning techniques, (4) utilization of the vision modality as a bridging mechanism, and (5) the combination of LLMs with tools. Additionally, this survey offers a comprehensive overview of the existing multimodal time series and text datasets and delves into the challenges and future opportunities of this emerging field. We maintain an up-to-date Github repository which includes all the papers and datasets discussed in the survey.
Read more5/8/2024