LLMs learn governing principles of dynamical systems, revealing an in-context neural scaling law
2402.00795
0
0

Abstract
Pretrained large language models (LLMs) are surprisingly effective at performing zero-shot tasks, including time-series forecasting. However, understanding the mechanisms behind such capabilities remains highly challenging due to the complexity of the models. We study LLMs' ability to extrapolate the behavior of dynamical systems whose evolution is governed by principles of physical interest. Our results show that LLaMA 2, a language model trained primarily on texts, achieves accurate predictions of dynamical system time series without fine-tuning or prompt engineering. Moreover, the accuracy of the learned physical rules increases with the length of the input context window, revealing an in-context version of neural scaling law. Along the way, we present a flexible and efficient algorithm for extracting probability density functions of multi-digit numbers directly from LLMs.
Create account to get full access
Overview
- This paper investigates how large language models (LLMs) can learn the underlying principles that govern the behavior of dynamical systems.
- The researchers found that LLMs exhibit an "in-context neural scaling law" that reveals their ability to extract and apply the fundamental mathematical relationships that describe the dynamics of complex systems.
- This work has implications for using LLMs as powerful tools for scientific discovery, modeling, and prediction across a wide range of domains.
Plain English Explanation
Dynamical systems are mathematical models that describe how things change and evolve over time, like the motion of planets or the stock market. This paper shows how large language models (LLMs) can learn the fundamental rules or "governing principles" that underlie these dynamic systems.
The researchers discovered that when LLMs are asked to predict the future behavior of a dynamical system, they exhibit a particular pattern or "scaling law" in how their performance improves as the model size increases. This scaling law reveals that the LLMs are actually learning and applying the core mathematical relationships that describe the system's dynamics, rather than just memorizing patterns.
In other words, the LLMs are able to extract the essential governing equations that govern how the system evolves over time. This is a significant finding because it shows that these powerful language models can be used as general-purpose "discovery engines" to uncover the fundamental principles underlying complex, data-driven phenomena. This capability could make LLMs invaluable tools for scientific research, forecasting, and decision-making across many different fields.
Technical Explanation
The researchers trained large language models (LLMs) to predict the future behavior of a variety of dynamical systems, ranging from classical mechanics problems to fluid dynamics and nonlinear oscillators. They found that the models' predictive performance scaled in a characteristic way as a function of the model size, following a power law relationship.
This "in-context neural scaling law" suggests that the LLMs are not just memorizing patterns in the data, but are actually learning and applying the fundamental mathematical relationships that govern the dynamics of the systems. The exponent of the scaling law corresponds to the effective dimensionality of the system, providing a quantitative measure of the models' ability to capture the system's underlying structure.
The researchers hypothesize that this scaling behavior arises because the LLMs are able to extract the governing equations of the dynamical systems and use them to make accurate predictions. This indicates that these models are not just pattern matchers, but can act as powerful "discovery engines" that can uncover the fundamental principles driving complex, data-driven phenomena.
Critical Analysis
The researchers provide a compelling demonstration of how large language models can be used to uncover the governing principles of dynamical systems. However, the paper does not explore the limitations of this approach or the potential sources of error.
For example, the researchers only tested the LLMs on a limited set of well-understood dynamical systems. It's unclear how well the models would perform on more complex, chaotic, or high-dimensional systems where the governing equations are not as well-defined. Additionally, the paper does not address the potential for LLMs to amplify or propagate errors in their predictions, which could be particularly problematic for long-term forecasting tasks.
Further research is needed to better understand the model's failure modes and the scope of systems for which this approach is most applicable. Additionally, the paper does not discuss the computational or sample efficiency of this method compared to more traditional system identification techniques.
Conclusion
This paper presents an exciting new direction for leveraging the capabilities of large language models beyond just natural language processing. By demonstrating that LLMs can learn the fundamental governing principles of dynamical systems, the researchers have shown the potential for these models to serve as powerful "discovery engines" across a wide range of scientific and engineering domains.
The in-context neural scaling law uncovered in this work provides a quantitative measure of an LLM's ability to capture the underlying structure of a system, opening up new possibilities for using these models for scientific research, forecasting, and decision-making. As the field of large language models continues to rapidly evolve, this work highlights the exciting and far-reaching implications of these technologies for advancing our understanding of the natural world.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🌿
LLM Processes: Numerical Predictive Distributions Conditioned on Natural Language
James Requeima, John Bronskill, Dami Choi, Richard E. Turner, David Duvenaud
0
0
Machine learning practitioners often face significant challenges in formally integrating their prior knowledge and beliefs into predictive models, limiting the potential for nuanced and context-aware analyses. Moreover, the expertise needed to integrate this prior knowledge into probabilistic modeling typically limits the application of these models to specialists. Our goal is to build a regression model that can process numerical data and make probabilistic predictions at arbitrary locations, guided by natural language text which describes a user's prior knowledge. Large Language Models (LLMs) provide a useful starting point for designing such a tool since they 1) provide an interface where users can incorporate expert insights in natural language and 2) provide an opportunity for leveraging latent problem-relevant knowledge encoded in LLMs that users may not have themselves. We start by exploring strategies for eliciting explicit, coherent numerical predictive distributions from LLMs. We examine these joint predictive distributions, which we call LLM Processes, over arbitrarily-many quantities in settings such as forecasting, multi-dimensional regression, black-box optimization, and image modeling. We investigate the practical details of prompting to elicit coherent predictive distributions, and demonstrate their effectiveness at regression. Finally, we demonstrate the ability to usefully incorporate text into numerical predictions, improving predictive performance and giving quantitative structure that reflects qualitative descriptions. This lets us begin to explore the rich, grounded hypothesis space that LLMs implicitly encode.
5/28/2024
Large Language Models for Time Series: A Survey
Xiyuan Zhang, Ranak Roy Chowdhury, Rajesh K. Gupta, Jingbo Shang
0
0
Large Language Models (LLMs) have seen significant use in domains such as natural language processing and computer vision. Going beyond text, image and graphics, LLMs present a significant potential for analysis of time series data, benefiting domains such as climate, IoT, healthcare, traffic, audio and finance. This survey paper provides an in-depth exploration and a detailed taxonomy of the various methodologies employed to harness the power of LLMs for time series analysis. We address the inherent challenge of bridging the gap between LLMs' original text data training and the numerical nature of time series data, and explore strategies for transferring and distilling knowledge from LLMs to numerical time series analysis. We detail various methodologies, including (1) direct prompting of LLMs, (2) time series quantization, (3) aligning techniques, (4) utilization of the vision modality as a bridging mechanism, and (5) the combination of LLMs with tools. Additionally, this survey offers a comprehensive overview of the existing multimodal time series and text datasets and delves into the challenges and future opportunities of this emerging field. We maintain an up-to-date Github repository which includes all the papers and datasets discussed in the survey.
5/8/2024
Temporal Scaling Law for Large Language Models
Yizhe Xiong, Xiansheng Chen, Xin Ye, Hui Chen, Zijia Lin, Haoran Lian, Zhenpeng Su, Jianwei Niu, Guiguang Ding
0
0
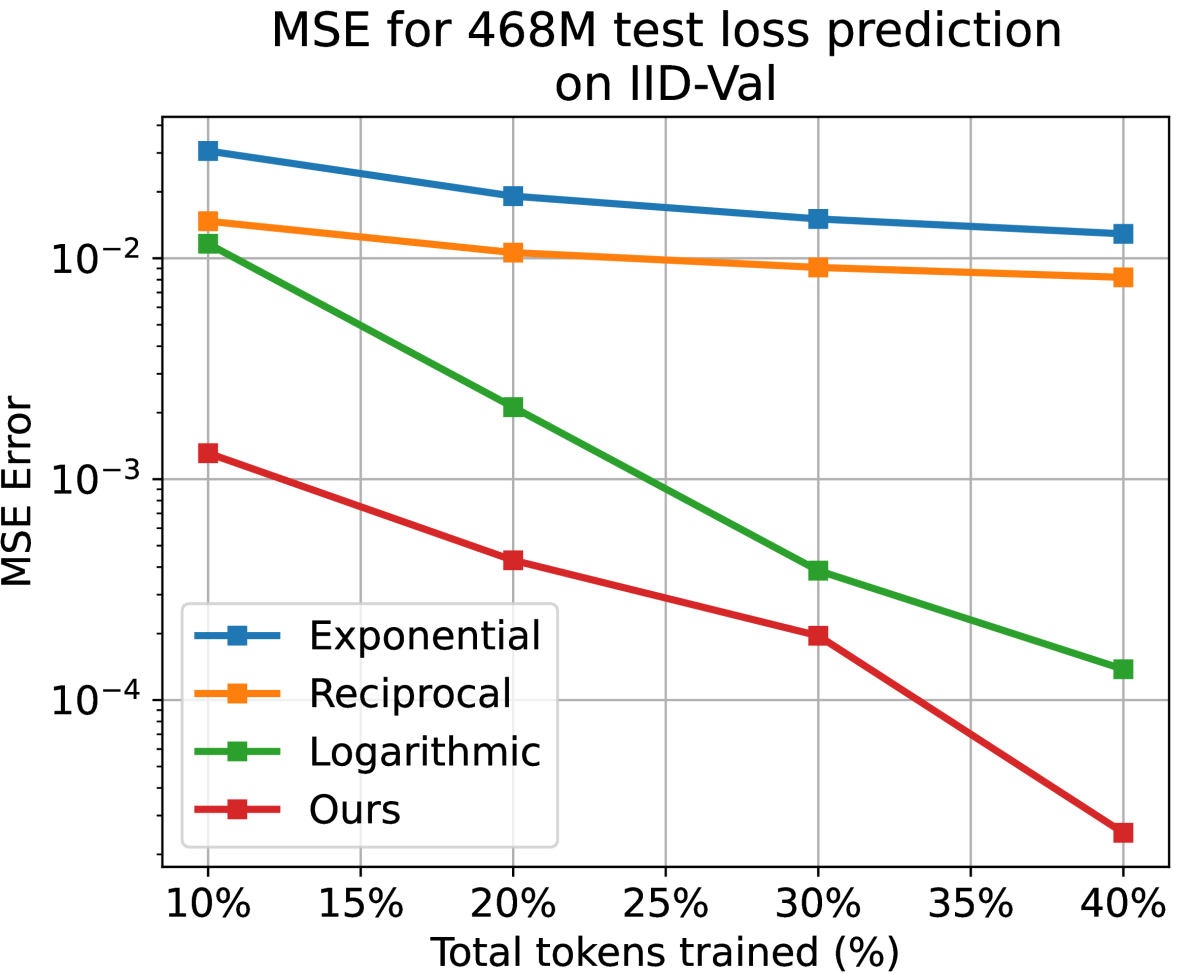
Recently, Large Language Models (LLMs) have been widely adopted in a wide range of tasks, leading to increasing attention towards the research on how scaling LLMs affects their performance. Existing works, termed Scaling Laws, have discovered that the final test loss of LLMs scales as power-laws with model size, computational budget, and dataset size. However, the temporal change of the test loss of an LLM throughout its pre-training process remains unexplored, though it is valuable in many aspects, such as selecting better hyperparameters textit{directly} on the target LLM. In this paper, we propose the novel concept of Temporal Scaling Law, studying how the test loss of an LLM evolves as the training steps scale up. In contrast to modeling the test loss as a whole in a coarse-grained manner, we break it down and dive into the fine-grained test loss of each token position, and further develop a dynamic hyperbolic-law. Afterwards, we derive the much more precise temporal scaling law by studying the temporal patterns of the parameters in the dynamic hyperbolic-law. Results on both in-distribution (ID) and out-of-distribution (OOD) validation datasets demonstrate that our temporal scaling law accurately predicts the test loss of LLMs across training steps. Our temporal scaling law has broad practical applications. First, it enables direct and efficient hyperparameter selection on the target LLM, such as data mixture proportions. Secondly, viewing the LLM pre-training dynamics from the token position granularity provides some insights to enhance the understanding of LLM pre-training.
6/18/2024
💬
LLM4ED: Large Language Models for Automatic Equation Discovery
Mengge Du, Yuntian Chen, Zhongzheng Wang, Longfeng Nie, Dongxiao Zhang
0
0
Equation discovery is aimed at directly extracting physical laws from data and has emerged as a pivotal research domain. Previous methods based on symbolic mathematics have achieved substantial advancements, but often require the design of implementation of complex algorithms. In this paper, we introduce a new framework that utilizes natural language-based prompts to guide large language models (LLMs) in automatically mining governing equations from data. Specifically, we first utilize the generation capability of LLMs to generate diverse equations in string form, and then evaluate the generated equations based on observations. In the optimization phase, we propose two alternately iterated strategies to optimize generated equations collaboratively. The first strategy is to take LLMs as a black-box optimizer and achieve equation self-improvement based on historical samples and their performance. The second strategy is to instruct LLMs to perform evolutionary operators for global search. Experiments are extensively conducted on both partial differential equations and ordinary differential equations. Results demonstrate that our framework can discover effective equations to reveal the underlying physical laws under various nonlinear dynamic systems. Further comparisons are made with state-of-the-art models, demonstrating good stability and usability. Our framework substantially lowers the barriers to learning and applying equation discovery techniques, demonstrating the application potential of LLMs in the field of knowledge discovery.
5/14/2024