Large Language Models can Share Images, Too!

0
💬
Sign in to get full access
Overview
- This paper explores the image-sharing capabilities of Large Language Models (LLMs) like GPT-4 and LLaMA 2 in a zero-shot setting.
- The researchers introduce the PhotoChat++ dataset with enriched annotations to facilitate a comprehensive evaluation of LLMs.
- They present the Decide, Describe, and Retrieve (DribeR) framework, a gradient-free and extensible approach.
- Extensive experiments unlock the image-sharing capability of DribeR equipped with LLMs in zero-shot prompting, with ChatGPT achieving the best performance.
- The paper demonstrates the emergent image-sharing ability in LLMs under zero-shot conditions and the practical applications of the DribeR framework.
Plain English Explanation
The paper investigates how well large language models, such as GPT-4 and LLaMA 2, can share and describe images without being explicitly trained on that task. The researchers created a new dataset called PhotoChat++ that includes additional information about the images, like the intent behind sharing the image and what the important parts of the image are. They also developed a framework called DribeR that can take a language model, like ChatGPT, and use it to both decide when to share an image and then describe the relevant parts of that image. Through their experiments, the researchers found that language models do have an emergent ability to share and describe images, even without being trained on that specific task. They demonstrate how this DribeR framework could be useful in real-world scenarios, like improving human-bot interactions and helping to expand image datasets.
Technical Explanation
The paper explores the image-sharing capabilities of Large Language Models (LLMs) in a zero-shot setting, where the models are not explicitly trained on the task of image sharing. To facilitate a comprehensive evaluation, the researchers introduce the PhotoChat++ dataset, which includes enriched annotations such as intent, triggering sentence, image description, and salient information.
The researchers present the Decide, Describe, and Retrieve (DribeR) framework, a gradient-free and extensible approach that leverages LLMs to perform image-sharing tasks. Through extensive experiments, they unlock the image-sharing capability of DribeR equipped with various LLMs, including GPT-4 and LLaMA 2, in a zero-shot prompting setting. The results show that ChatGPT achieves the best performance, demonstrating the emergent image-sharing ability in LLMs under zero-shot conditions.
The paper also showcases the practical applications of the DribeR framework in two real-world scenarios: (1) human-bot interaction, where the system can engage in natural conversations and share relevant images, and (2) dataset augmentation, where the framework can generate image descriptions to expand existing datasets. To the best of the researchers' knowledge, this is the first study to assess the image-sharing ability of various LLMs in a zero-shot setting.
Critical Analysis
The paper presents a comprehensive and well-designed study on the image-sharing capabilities of Large Language Models (LLMs) in a zero-shot setting. The introduction of the PhotoChat++ dataset with enriched annotations is a valuable contribution, as it allows for a more thorough evaluation of LLMs' performance in this task.
The Decide, Describe, and Retrieve (DribeR) framework is a promising approach that leverages the inherent capabilities of LLMs to perform image-sharing tasks. The authors' extensive experiments and the superior performance of ChatGPT suggest that LLMs do possess an emergent ability to share and describe images, even without being explicitly trained on this task.
However, the paper could have explored additional aspects to provide a more comprehensive understanding of the limitations and potential issues with this approach. For example, the authors could have delved deeper into the biases and failures of the LLMs in the zero-shot image-sharing task, as well as the impact of the dataset's composition and quality on the model's performance.
Furthermore, the paper could have discussed the scalability and generalizability of the DribeR framework, as it is currently evaluated on a specific dataset and set of LLMs. Exploring the framework's performance with larger and more diverse datasets, as well as its applicability to a broader range of LLMs, would provide valuable insights.
Despite these minor limitations, the paper makes a significant contribution to the understanding of LLMs' emergent capabilities in the realm of image sharing, and the DribeR framework presents a promising approach for practical applications in human-bot interactions and dataset augmentation.
Conclusion
This paper presents a comprehensive exploration of the image-sharing capabilities of Large Language Models (LLMs) in a zero-shot setting. By introducing the PhotoChat++ dataset and the Decide, Describe, and Retrieve (DribeR) framework, the researchers have made valuable contributions to the field.
The study's findings reveal the emergent image-sharing ability of LLMs, with ChatGPT demonstrating the best performance. This discovery has important implications for the development of more versatile and natural language-based systems, capable of seamlessly integrating image-sharing capabilities into their interactions.
The practical applications of the DribeR framework, such as enhancing human-bot interactions and dataset augmentation, further highlight the significance of this research. As the field of natural language processing continues to evolve, studies like this one will play a crucial role in unlocking the full potential of Large Language Models and shaping the future of human-AI collaboration.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
0
Large Language Models can Share Images, Too!
Young-Jun Lee, Dokyong Lee, Joo Won Sung, Jonghwan Hyeon, Ho-Jin Choi
This paper explores the image-sharing capability of Large Language Models (LLMs), such as GPT-4 and LLaMA 2, in a zero-shot setting. To facilitate a comprehensive evaluation of LLMs, we introduce the PhotoChat++ dataset, which includes enriched annotations (i.e., intent, triggering sentence, image description, and salient information). Furthermore, we present the gradient-free and extensible Decide, Describe, and Retrieve (DribeR) framework. With extensive experiments, we unlock the image-sharing capability of DribeR equipped with LLMs in zero-shot prompting, with ChatGPT achieving the best performance. Our findings also reveal the emergent image-sharing ability in LLMs under zero-shot conditions, validating the effectiveness of DribeR. We use this framework to demonstrate its practicality and effectiveness in two real-world scenarios: (1) human-bot interaction and (2) dataset augmentation. To the best of our knowledge, this is the first study to assess the image-sharing ability of various LLMs in a zero-shot setting. We make our source code and dataset publicly available at https://github.com/passing2961/DribeR.
Read more7/8/2024
0
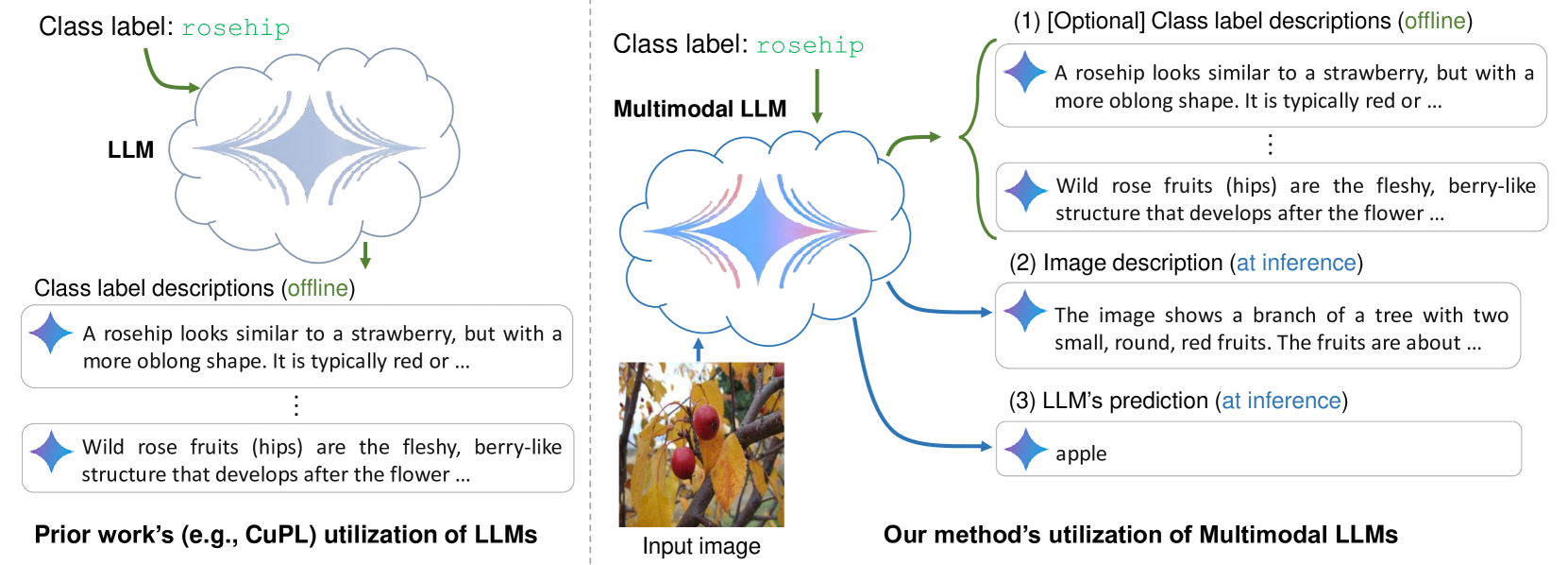
What Do You See? Enhancing Zero-Shot Image Classification with Multimodal Large Language Models
Abdelrahman Abdelhamed, Mahmoud Afifi, Alec Go
Large language models (LLMs) has been effectively used for many computer vision tasks, including image classification. In this paper, we present a simple yet effective approach for zero-shot image classification using multimodal LLMs. By employing multimodal LLMs, we generate comprehensive textual representations from input images. These textual representations are then utilized to generate fixed-dimensional features in a cross-modal embedding space. Subsequently, these features are fused together to perform zero-shot classification using a linear classifier. Our method does not require prompt engineering for each dataset; instead, we use a single, straightforward, set of prompts across all datasets. We evaluated our method on several datasets, and our results demonstrate its remarkable effectiveness, surpassing benchmark accuracy on multiple datasets. On average over ten benchmarks, our method achieved an accuracy gain of 4.1 percentage points, with an increase of 6.8 percentage points on the ImageNet dataset, compared to prior methods. Our findings highlight the potential of multimodal LLMs to enhance computer vision tasks such as zero-shot image classification, offering a significant improvement over traditional methods.
Read more5/27/2024

0
Large Language Models are Good Prompt Learners for Low-Shot Image Classification
Zhaoheng Zheng, Jingmin Wei, Xuefeng Hu, Haidong Zhu, Ram Nevatia
Low-shot image classification, where training images are limited or inaccessible, has benefited from recent progress on pre-trained vision-language (VL) models with strong generalizability, e.g. CLIP. Prompt learning methods built with VL models generate text features from the class names that only have confined class-specific information. Large Language Models (LLMs), with their vast encyclopedic knowledge, emerge as the complement. Thus, in this paper, we discuss the integration of LLMs to enhance pre-trained VL models, specifically on low-shot classification. However, the domain gap between language and vision blocks the direct application of LLMs. Thus, we propose LLaMP, Large Language Models as Prompt learners, that produces adaptive prompts for the CLIP text encoder, establishing it as the connecting bridge. Experiments show that, compared with other state-of-the-art prompt learning methods, LLaMP yields better performance on both zero-shot generalization and few-shot image classification, over a spectrum of 11 datasets. Code will be made available at: https://github.com/zhaohengz/LLaMP.
Read more4/4/2024

0
Language Models as Zero-Shot Trajectory Generators
Teyun Kwon, Norman Di Palo, Edward Johns
Large Language Models (LLMs) have recently shown promise as high-level planners for robots when given access to a selection of low-level skills. However, it is often assumed that LLMs do not possess sufficient knowledge to be used for the low-level trajectories themselves. In this work, we address this assumption thoroughly, and investigate if an LLM (GPT-4) can directly predict a dense sequence of end-effector poses for manipulation tasks, when given access to only object detection and segmentation vision models. We designed a single, task-agnostic prompt, without any in-context examples, motion primitives, or external trajectory optimisers. Then we studied how well it can perform across 30 real-world language-based tasks, such as open the bottle cap and wipe the plate with the sponge, and we investigated which design choices in this prompt are the most important. Our conclusions raise the assumed limit of LLMs for robotics, and we reveal for the first time that LLMs do indeed possess an understanding of low-level robot control sufficient for a range of common tasks, and that they can additionally detect failures and then re-plan trajectories accordingly. Videos, prompts, and code are available at: https://www.robot-learning.uk/language-models-trajectory-generators.
Read more6/19/2024