Large Language Models for Information Retrieval: A Survey

1
💬
Sign in to get full access
Overview
- Information retrieval (IR) systems, such as search engines, are a primary means of information acquisition in our daily lives.
- These systems also serve as components of dialogue, question-answering, and recommender systems.
- The trajectory of IR has evolved from term-based methods to integration with advanced neural models.
- While neural models excel at capturing complex contextual signals and semantic nuances, they face challenges like data scarcity, interpretability, and generating potentially inaccurate responses.
- The evolution of IR requires a combination of traditional methods (term-based sparse retrieval) and modern neural architectures (language models with powerful understanding).
- The emergence of large language models (LLMs), like ChatGPT and GPT-4, has revolutionized natural language processing with their remarkable abilities.
- Recent research has sought to leverage LLMs to improve IR systems.
Plain English Explanation
Information retrieval (IR) systems, such as search engines, have become a vital part of our daily lives. These systems help us find the information we need, whether it's answering a question, finding a product, or discovering new content.
Over time, IR systems have evolved from using simple keyword-based methods to incorporating advanced neural neural networks that can better understand the nuances and context of our queries. These neural models are particularly good at capturing the subtle meanings and relationships between words, which can lead to more relevant and accurate search results.
However, neural models also face some challenges, such as data scarcity, the difficulty in understanding how they arrive at their results (interpretability), and the potential to generate responses that are contextually plausible but not entirely accurate.
To address these challenges, researchers are exploring ways to combine traditional term-based IR methods, which are fast and reliable, with the powerful language understanding capabilities of modern neural architectures, like large language models (LLMs).
LLMs, exemplified by ChatGPT and GPT-4, have revolutionized natural language processing (NLP) with their remarkable abilities to understand, generate, and reason about language. Recent research has focused on leveraging these advanced LLMs to further improve the performance and capabilities of IR systems.
Technical Explanation
The paper examines the confluence of large language models (LLMs) and information retrieval (IR) systems, including crucial components like query rewriters, retrievers, rerankers, and readers.
The authors highlight the dynamic evolution of IR, from its origins in term-based methods to its integration with advanced neural models. While the neural models excel at capturing complex contextual signals and semantic nuances, they still face challenges such as data scarcity, interpretability, and the generation of contextually plausible yet potentially inaccurate responses.
To address these challenges, the paper advocates for a combination of traditional methods (such as term-based sparse retrieval methods with rapid response) and modern neural architectures (such as language models with powerful language understanding capacity). This approach aims to leverage the strengths of both traditional and modern techniques to enhance IR system performance.
The emergence of LLMs, like ChatGPT and GPT-4, has further revolutionized natural language processing. These models have demonstrated remarkable language understanding, generation, generalization, and reasoning abilities, prompting recent research to explore ways of integrating them into IR systems to improve their overall effectiveness.
The paper provides a comprehensive overview of the methodologies and insights related to the integration of LLMs and IR systems, including query rewriters, retrievers, rerankers, and readers. Additionally, it explores promising directions, such as the development of search agents, within this expanding field.
Critical Analysis
The paper highlights the significant challenges faced by neural models in IR systems, such as data scarcity, interpretability, and the generation of potentially inaccurate responses. These are critical issues that need to be addressed to ensure the reliability and trustworthiness of IR systems, especially as they become more integrated into our daily lives.
While the paper acknowledges the benefits of combining traditional term-based methods with modern neural architectures, it does not delve deeply into the specific trade-offs and implementation details of this approach. Further research is needed to understand the optimal balance and integration strategies between these different techniques.
Additionally, the paper focuses primarily on the technical aspects of LLM-IR integration, but it could be valuable to explore the broader societal implications and ethical considerations of these advancements. As IR systems become more powerful and influential, it is crucial to consider issues such as algorithmic bias, privacy, and the potential for misuse or unintended consequences.
Conclusion
The paper presents a comprehensive overview of the evolving landscape of information retrieval (IR) systems, with a focus on the integration of large language models (LLMs) to enhance their capabilities. It highlights the dynamic trajectory of IR, from term-based methods to the incorporation of advanced neural models, as well as the challenges that these neural models face, such as data scarcity, interpretability, and the generation of potentially inaccurate responses.
To address these challenges, the paper advocates for a combination of traditional and modern techniques, leveraging the strengths of both term-based sparse retrieval methods and powerful language models. The emergence of LLMs, exemplified by ChatGPT and GPT-4, has further revolutionized natural language processing, prompting recent research to explore ways of integrating these models into IR systems.
The paper provides insights into the methodologies and promising directions, such as search agents, within the expanding field of LLM-IR integration. While the technical aspects are well-covered, the paper could benefit from a deeper exploration of the broader societal implications and ethical considerations surrounding these advancements.
Overall, the paper offers a valuable contribution to the understanding of the current state and future trajectories of information retrieval systems, highlighting the significance of the ongoing efforts to harness the power of large language models to enhance the effectiveness and reliability of these crucial tools in our daily lives.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
1
Large Language Models for Information Retrieval: A Survey
Yutao Zhu, Huaying Yuan, Shuting Wang, Jiongnan Liu, Wenhan Liu, Chenlong Deng, Haonan Chen, Zheng Liu, Zhicheng Dou, Ji-Rong Wen
As a primary means of information acquisition, information retrieval (IR) systems, such as search engines, have integrated themselves into our daily lives. These systems also serve as components of dialogue, question-answering, and recommender systems. The trajectory of IR has evolved dynamically from its origins in term-based methods to its integration with advanced neural models. While the neural models excel at capturing complex contextual signals and semantic nuances, thereby reshaping the IR landscape, they still face challenges such as data scarcity, interpretability, and the generation of contextually plausible yet potentially inaccurate responses. This evolution requires a combination of both traditional methods (such as term-based sparse retrieval methods with rapid response) and modern neural architectures (such as language models with powerful language understanding capacity). Meanwhile, the emergence of large language models (LLMs), typified by ChatGPT and GPT-4, has revolutionized natural language processing due to their remarkable language understanding, generation, generalization, and reasoning abilities. Consequently, recent research has sought to leverage LLMs to improve IR systems. Given the rapid evolution of this research trajectory, it is necessary to consolidate existing methodologies and provide nuanced insights through a comprehensive overview. In this survey, we delve into the confluence of LLMs and IR systems, including crucial aspects such as query rewriters, retrievers, rerankers, and readers. Additionally, we explore promising directions, such as search agents, within this expanding field.
Read more9/5/2024
2
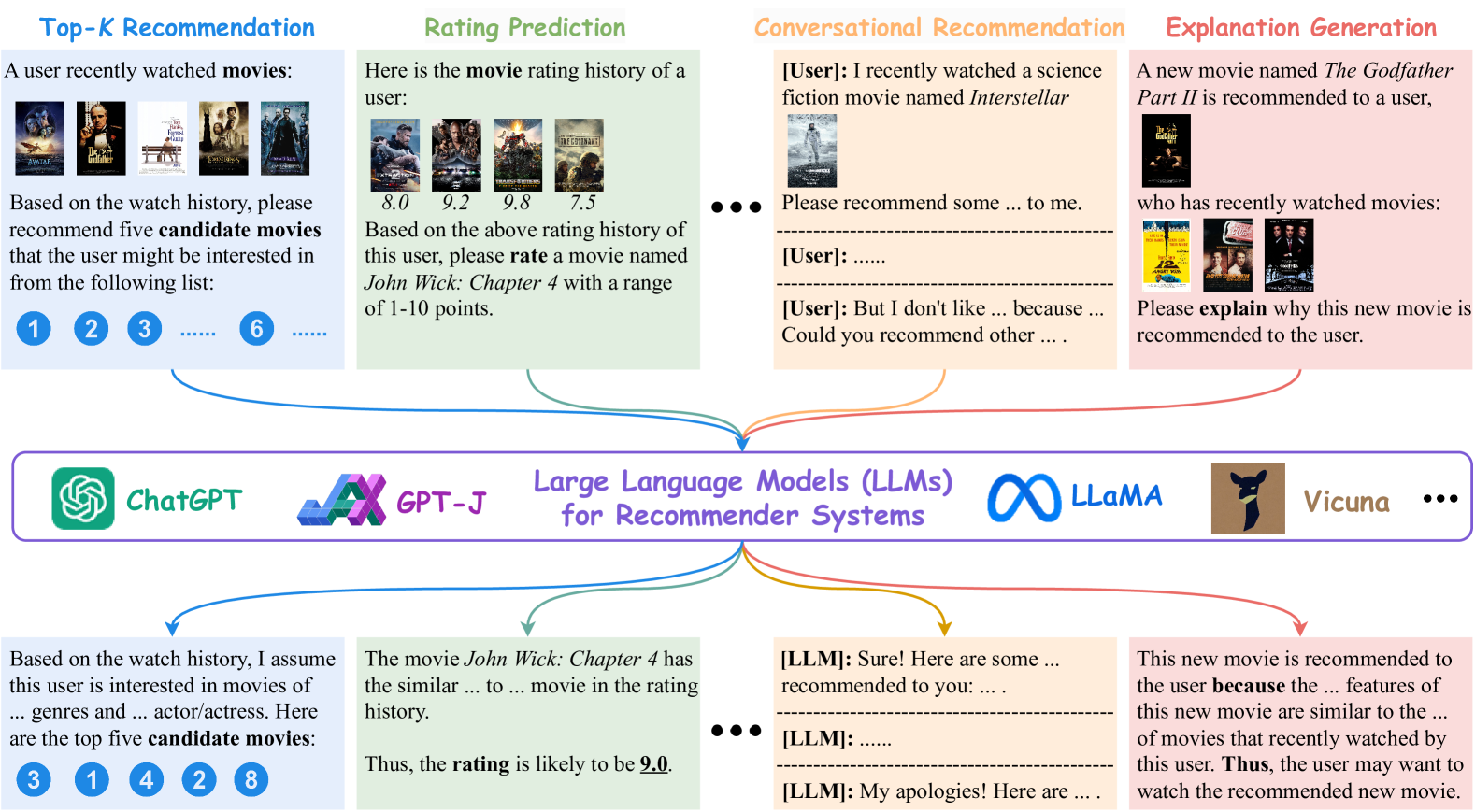
Recommender Systems in the Era of Large Language Models (LLMs)
Zihuai Zhao, Wenqi Fan, Jiatong Li, Yunqing Liu, Xiaowei Mei, Yiqi Wang, Zhen Wen, Fei Wang, Xiangyu Zhao, Jiliang Tang, Qing Li
With the prosperity of e-commerce and web applications, Recommender Systems (RecSys) have become an important component of our daily life, providing personalized suggestions that cater to user preferences. While Deep Neural Networks (DNNs) have made significant advancements in enhancing recommender systems by modeling user-item interactions and incorporating textual side information, DNN-based methods still face limitations, such as difficulties in understanding users' interests and capturing textual side information, inabilities in generalizing to various recommendation scenarios and reasoning on their predictions, etc. Meanwhile, the emergence of Large Language Models (LLMs), such as ChatGPT and GPT4, has revolutionized the fields of Natural Language Processing (NLP) and Artificial Intelligence (AI), due to their remarkable abilities in fundamental responsibilities of language understanding and generation, as well as impressive generalization and reasoning capabilities. As a result, recent studies have attempted to harness the power of LLMs to enhance recommender systems. Given the rapid evolution of this research direction in recommender systems, there is a pressing need for a systematic overview that summarizes existing LLM-empowered recommender systems, to provide researchers in relevant fields with an in-depth understanding. Therefore, in this paper, we conduct a comprehensive review of LLM-empowered recommender systems from various aspects including Pre-training, Fine-tuning, and Prompting. More specifically, we first introduce representative methods to harness the power of LLMs (as a feature encoder) for learning representations of users and items. Then, we review recent techniques of LLMs for enhancing recommender systems from three paradigms, namely pre-training, fine-tuning, and prompting. Finally, we comprehensively discuss future directions in this emerging field.
Read more4/23/2024
💬
0
Redefining Information Retrieval of Structured Database via Large Language Models
Mingzhu Wang, Yuzhe Zhang, Qihang Zhao, Juanyi Yang, Hong Zhang
Retrieval augmentation is critical when Language Models (LMs) exploit non-parametric knowledge related to the query through external knowledge bases before reasoning. The retrieved information is incorporated into LMs as context alongside the query, enhancing the reliability of responses towards factual questions. Prior researches in retrieval augmentation typically follow a retriever-generator paradigm. In this context, traditional retrievers encounter challenges in precisely and seamlessly extracting query-relevant information from knowledge bases. To address this issue, this paper introduces a novel retrieval augmentation framework called ChatLR that primarily employs the powerful semantic understanding ability of Large Language Models (LLMs) as retrievers to achieve precise and concise information retrieval. Additionally, we construct an LLM-based search and question answering system tailored for the financial domain by fine-tuning LLM on two tasks including Text2API and API-ID recognition. Experimental results demonstrate the effectiveness of ChatLR in addressing user queries, achieving an overall information retrieval accuracy exceeding 98.8%.
Read more5/10/2024
💬
1
A Survey on Large Language Models for Recommendation
Likang Wu, Zhi Zheng, Zhaopeng Qiu, Hao Wang, Hongchao Gu, Tingjia Shen, Chuan Qin, Chen Zhu, Hengshu Zhu, Qi Liu, Hui Xiong, Enhong Chen
Large Language Models (LLMs) have emerged as powerful tools in the field of Natural Language Processing (NLP) and have recently gained significant attention in the domain of Recommendation Systems (RS). These models, trained on massive amounts of data using self-supervised learning, have demonstrated remarkable success in learning universal representations and have the potential to enhance various aspects of recommendation systems by some effective transfer techniques such as fine-tuning and prompt tuning, and so on. The crucial aspect of harnessing the power of language models in enhancing recommendation quality is the utilization of their high-quality representations of textual features and their extensive coverage of external knowledge to establish correlations between items and users. To provide a comprehensive understanding of the existing LLM-based recommendation systems, this survey presents a taxonomy that categorizes these models into two major paradigms, respectively Discriminative LLM for Recommendation (DLLM4Rec) and Generative LLM for Recommendation (GLLM4Rec), with the latter being systematically sorted out for the first time. Furthermore, we systematically review and analyze existing LLM-based recommendation systems within each paradigm, providing insights into their methodologies, techniques, and performance. Additionally, we identify key challenges and several valuable findings to provide researchers and practitioners with inspiration. We have also created a GitHub repository to index relevant papers on LLMs for recommendation, https://github.com/WLiK/LLM4Rec.
Read more6/19/2024