DeiT-LT Distillation Strikes Back for Vision Transformer Training on Long-Tailed Datasets
2404.02900
0
0

Abstract
Vision Transformer (ViT) has emerged as a prominent architecture for various computer vision tasks. In ViT, we divide the input image into patch tokens and process them through a stack of self attention blocks. However, unlike Convolutional Neural Networks (CNN), ViTs simple architecture has no informative inductive bias (e.g., locality,etc. ). Due to this, ViT requires a large amount of data for pre-training. Various data efficient approaches (DeiT) have been proposed to train ViT on balanced datasets effectively. However, limited literature discusses the use of ViT for datasets with long-tailed imbalances. In this work, we introduce DeiT-LT to tackle the problem of training ViTs from scratch on long-tailed datasets. In DeiT-LT, we introduce an efficient and effective way of distillation from CNN via distillation DIST token by using out-of-distribution images and re-weighting the distillation loss to enhance focus on tail classes. This leads to the learning of local CNN-like features in early ViT blocks, improving generalization for tail classes. Further, to mitigate overfitting, we propose distilling from a flat CNN teacher, which leads to learning low-rank generalizable features for DIST tokens across all ViT blocks. With the proposed DeiT-LT scheme, the distillation DIST token becomes an expert on the tail classes, and the classifier CLS token becomes an expert on the head classes. The experts help to effectively learn features corresponding to both the majority and minority classes using a distinct set of tokens within the same ViT architecture. We show the effectiveness of DeiT-LT for training ViT from scratch on datasets ranging from small-scale CIFAR-10 LT to large-scale iNaturalist-2018.
Create account to get full access
Overview
- This paper introduces DeiT-LT, a distillation-based approach for training Vision Transformer (ViT) models on long-tailed datasets.
- Long-tailed datasets have a skewed distribution where a few classes have many examples while most classes have few examples.
- DeiT-LT leverages distillation from a teacher network to improve the performance of ViT models on long-tailed datasets.
Plain English Explanation
In machine learning, datasets used to train models often have an unbalanced distribution, where some classes (categories) have many examples while others have very few. This is known as a
The authors of this paper propose a new approach called DeiT-LT that aims to address this problem for Vision Transformer (ViT) models. ViTs are a type of deep learning model that excel at computer vision tasks like image classification.
The key idea behind DeiT-LT is to use
By leveraging distillation, the authors show that DeiT-LT can significantly improve the performance of ViT models on long-tailed datasets compared to standard training approaches. This is an important advance, as long-tailed datasets are common in real-world applications, and being able to train high-performing models on them is crucial.
Technical Explanation
The paper introduces DeiT-LT, a distillation-based approach for training Vision Transformer (ViT) models on
The authors propose using
Specifically, DeiT-LT uses a ViT as the student model and a pre-trained DeiT model as the teacher. The teacher model is fine-tuned on the long-tailed dataset, and its outputs are used to provide soft targets for the student ViT model during training. This helps the student model learn more effectively from the classes with few examples.
The authors evaluate DeiT-LT on several long-tailed image classification benchmarks, including ImageNet-LT and iNaturalist2017. They show that DeiT-LT significantly outperforms standard ViT training, as well as other state-of-the-art long-tailed learning approaches like Task Integration and Distillation and ViTAMIN.
Critical Analysis
The authors provide a thorough evaluation of DeiT-LT on multiple long-tailed datasets, demonstrating its effectiveness at improving ViT performance in these challenging scenarios. However, the paper does not delve into the potential limitations or caveats of the approach.
One area that could be explored further is the impact of the teacher model's architecture and performance on the final results. The paper uses a pre-trained DeiT model as the teacher, but it's unclear how the choice of teacher model might affect the distillation process and the student ViT's performance.
Additionally, the paper focuses solely on image classification tasks. It would be interesting to see how well the DeiT-LT approach generalizes to other computer vision tasks, such as object detection or segmentation, where long-tailed datasets are also prevalent.
Finally, the authors do not discuss the computational overhead or training time of the DeiT-LT approach compared to standard ViT training. This information would be valuable for practitioners considering the practical implementation of the method.
Conclusion
The DeiT-LT approach introduced in this paper represents a significant advancement in training Vision Transformer models on long-tailed datasets. By leveraging knowledge distillation from a pre-trained teacher model, the authors demonstrate that ViT performance can be substantially improved on these challenging, real-world datasets.
The results highlight the potential of distillation-based methods for addressing the long-tailed data distribution problem, which is a common challenge in many practical machine learning applications. While the paper leaves room for further investigation, it provides a promising direction for enhancing the robustness and applicability of ViT models in diverse real-world scenarios.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
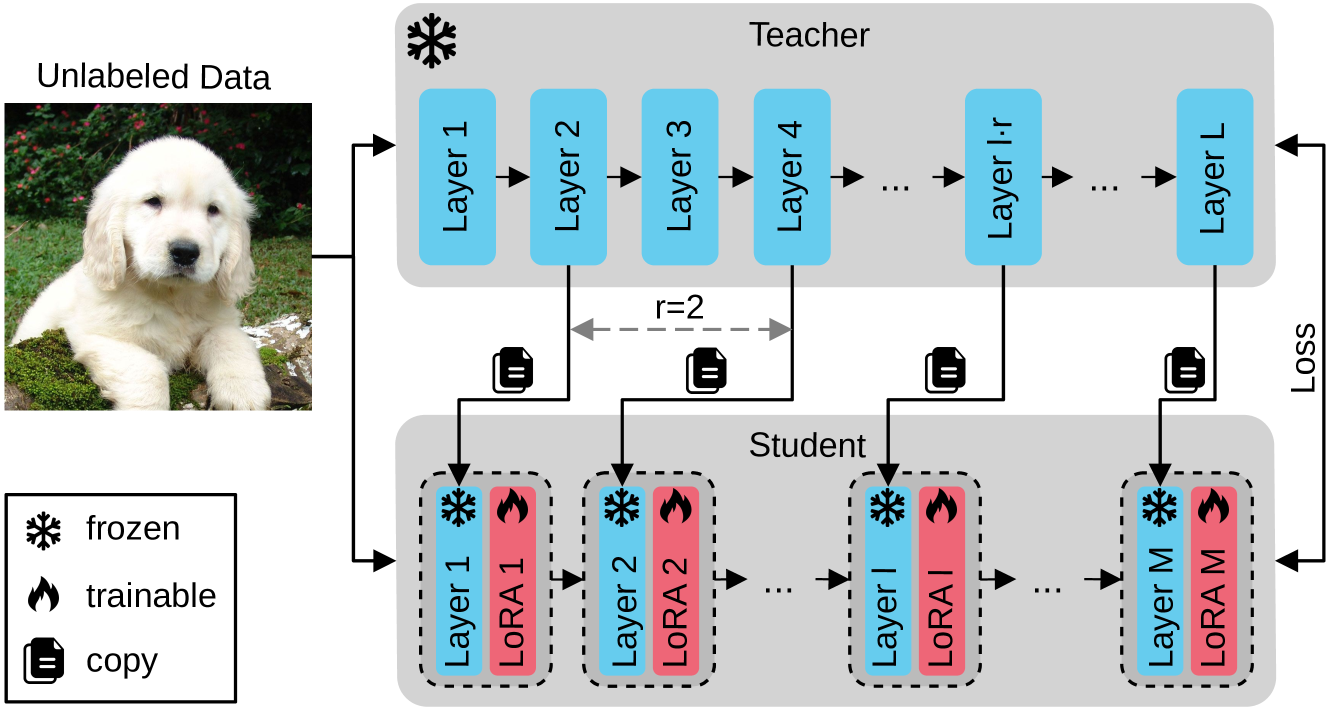
Weight Copy and Low-Rank Adaptation for Few-Shot Distillation of Vision Transformers
Diana-Nicoleta Grigore, Mariana-Iuliana Georgescu, Jon Alvarez Justo, Tor Johansen, Andreea Iuliana Ionescu, Radu Tudor Ionescu
0
0
Few-shot knowledge distillation recently emerged as a viable approach to harness the knowledge of large-scale pre-trained models, using limited data and computational resources. In this paper, we propose a novel few-shot feature distillation approach for vision transformers. Our approach is based on two key steps. Leveraging the fact that vision transformers have a consistent depth-wise structure, we first copy the weights from intermittent layers of existing pre-trained vision transformers (teachers) into shallower architectures (students), where the intermittence factor controls the complexity of the student transformer with respect to its teacher. Next, we employ an enhanced version of Low-Rank Adaptation (LoRA) to distill knowledge into the student in a few-shot scenario, aiming to recover the information processing carried out by the skipped teacher layers. We present comprehensive experiments with supervised and self-supervised transformers as teachers, on five data sets from various domains, including natural, medical and satellite images. The empirical results confirm the superiority of our approach over competitive baselines. Moreover, the ablation results demonstrate the usefulness of each component of the proposed pipeline.
4/16/2024

Latent-based Diffusion Model for Long-tailed Recognition
Pengxiao Han, Changkun Ye, Jieming Zhou, Jing Zhang, Jie Hong, Xuesong Li
0
0
Long-tailed imbalance distribution is a common issue in practical computer vision applications. Previous works proposed methods to address this problem, which can be categorized into several classes: re-sampling, re-weighting, transfer learning, and feature augmentation. In recent years, diffusion models have shown an impressive generation ability in many sub-problems of deep computer vision. However, its powerful generation has not been explored in long-tailed problems. We propose a new approach, the Latent-based Diffusion Model for Long-tailed Recognition (LDMLR), as a feature augmentation method to tackle the issue. First, we encode the imbalanced dataset into features using the baseline model. Then, we train a Denoising Diffusion Implicit Model (DDIM) using these encoded features to generate pseudo-features. Finally, we train the classifier using the encoded and pseudo-features from the previous two steps. The model's accuracy shows an improvement on the CIFAR-LT and ImageNet-LT datasets by using the proposed method.
4/24/2024
👀
AViT: Adapting Vision Transformers for Small Skin Lesion Segmentation Datasets
Siyi Du, Nourhan Bayasi, Ghassan Hamarneh, Rafeef Garbi
0
0
Skin lesion segmentation (SLS) plays an important role in skin lesion analysis. Vision transformers (ViTs) are considered an auspicious solution for SLS, but they require more training data compared to convolutional neural networks (CNNs) due to their inherent parameter-heavy structure and lack of some inductive biases. To alleviate this issue, current approaches fine-tune pre-trained ViT backbones on SLS datasets, aiming to leverage the knowledge learned from a larger set of natural images to lower the amount of skin training data needed. However, fully fine-tuning all parameters of large backbones is computationally expensive and memory intensive. In this paper, we propose AViT, a novel efficient strategy to mitigate ViTs' data-hunger by transferring any pre-trained ViTs to the SLS task. Specifically, we integrate lightweight modules (adapters) within the transformer layers, which modulate the feature representation of a ViT without updating its pre-trained weights. In addition, we employ a shallow CNN as a prompt generator to create a prompt embedding from the input image, which grasps fine-grained information and CNN's inductive biases to guide the segmentation task on small datasets. Our quantitative experiments on 4 skin lesion datasets demonstrate that AViT achieves competitive, and at times superior, performance to SOTA but with significantly fewer trainable parameters. Our code is available at https://github.com/siyi-wind/AViT.
6/13/2024
👀
DiffiT: Diffusion Vision Transformers for Image Generation
Ali Hatamizadeh, Jiaming Song, Guilin Liu, Jan Kautz, Arash Vahdat
0
0
Diffusion models with their powerful expressivity and high sample quality have achieved State-Of-The-Art (SOTA) performance in the generative domain. The pioneering Vision Transformer (ViT) has also demonstrated strong modeling capabilities and scalability, especially for recognition tasks. In this paper, we study the effectiveness of ViTs in diffusion-based generative learning and propose a new model denoted as Diffusion Vision Transformers (DiffiT). Specifically, we propose a methodology for finegrained control of the denoising process and introduce the Time-dependant Multihead Self Attention (TMSA) mechanism. DiffiT is surprisingly effective in generating high-fidelity images with significantly better parameter efficiency. We also propose latent and image space DiffiT models and show SOTA performance on a variety of class-conditional and unconditional synthesis tasks at different resolutions. The Latent DiffiT model achieves a new SOTA FID score of 1.73 on ImageNet-256 dataset while having 19.85%, 16.88% less parameters than other Transformer-based diffusion models such as MDT and DiT, respectively. Code: https://github.com/NVlabs/DiffiT
4/3/2024