Learning 3D-Aware GANs from Unposed Images with Template Feature Field

0

Sign in to get full access
Overview
- This paper presents a novel approach to learning 3D-aware Generative Adversarial Networks (GANs) from unposed images using a Template Feature Field.
- The method aims to address the challenge of 3D-aware image generation from 2D images without relying on 3D annotations or posed data.
- The key contributions include a 3D template feature field representation, a 3D-aware GAN architecture, and a training strategy that leverages semantic features.
Plain English Explanation
The paper describes a new way to create 3D-aware images using a machine learning technique called Generative Adversarial Networks (GANs). GANs are a type of AI model that can generate new images that look similar to a set of training images.
The main innovation in this paper is the use of a "template feature field" to help the GAN understand the 3D structure of the objects it's generating, even though the training images don't have any 3D information. The template feature field acts like a 3D map that guides the GAN to create images with realistic depth and perspective, without needing 3D annotations or posed data.
This is an important advance because most existing 3D-aware image generation methods rely on having 3D information about the objects in the training data, which can be expensive or difficult to obtain. This new approach allows 3D-aware image generation from regular 2D photos, which opens up new possibilities for applications like 3D content creation, virtual reality, and augmented reality.
The authors demonstrate that their 3D-aware GAN can generate high-quality 3D-looking images from regular 2D photos, and show that it outperforms previous methods on standard benchmarks. Overall, this research represents a significant step forward in the field of 3D-aware image generation.
Technical Explanation
The paper introduces a novel approach for learning 3D-aware GANs from unposed 2D images using a Template Feature Field. The key elements of their method include:
-
Template Feature Field: The authors propose a 3D template feature field representation that encodes semantic information about the 3D structure of the objects in the training data. This template feature field acts as a guiding signal for the GAN during training to help it learn a 3D-aware image generation model.
-
3D-Aware GAN Architecture: The authors design a 3D-aware GAN architecture that takes the template feature field as input, along with the 2D image, to generate 3D-aware images. This architecture includes 3D-aware components like a 3D feature extractor and a 3D-aware discriminator.
-
Semantic-Aware Training Strategy: The authors employ a training strategy that jointly optimizes the GAN to generate realistic images and align the generated images with the semantic information encoded in the template feature field. This helps the GAN learn to generate images with accurate 3D structure.
The authors evaluate their approach on several benchmarks for 3D-aware image generation and show that it outperforms previous state-of-the-art methods. The results demonstrate the effectiveness of their 3D template feature field representation and 3D-aware GAN architecture in generating high-quality 3D-aware images from unposed 2D data.
Critical Analysis
The paper presents a compelling approach to 3D-aware image generation from 2D data, which is an important problem in computer vision and graphics. The use of a template feature field to guide the GAN's 3D understanding is a clever solution to the challenge of lacking 3D annotations in the training data.
However, the paper does not discuss the limitations of the template feature field representation, such as how it scales to more complex 3D shapes or how sensitive the approach is to the quality and coverage of the template features. Additionally, the authors do not provide much insight into the failure modes of their method or how it might perform in real-world applications with more diverse and noisy data.
Further research could explore ways to make the template feature field representation more flexible and generalizable, perhaps by learning it directly from data rather than relying on a predefined template. Investigating the robustness of the approach to different types of 2D input data and evaluating its performance in downstream tasks like 3D content creation or augmented reality would also be valuable.
Overall, this paper represents a significant contribution to the field of 3D-aware image generation, and the authors' use of a template feature field is a creative and promising solution to the challenge of learning 3D structure from 2D data. With further research and refinement, this approach could have important implications for a wide range of applications.
Conclusion
This paper presents a novel method for learning 3D-aware GANs from unposed 2D images using a Template Feature Field. The key innovations include a 3D template feature field representation, a 3D-aware GAN architecture, and a semantic-aware training strategy.
The results demonstrate that this approach can generate high-quality 3D-aware images from regular 2D photos, without relying on 3D annotations or posed data. This is a significant advancement over previous methods, as it opens up new possibilities for 3D content creation, virtual reality, and augmented reality applications that can leverage 3D-aware image generation from readily available 2D data.
While the paper does not address all the potential limitations of the approach, it represents an important step forward in the field of 3D-aware image generation. With further research and refinement, the techniques described in this paper could have far-reaching implications for a wide range of industries and applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Learning 3D-Aware GANs from Unposed Images with Template Feature Field
Xinya Chen, Hanlei Guo, Yanrui Bin, Shangzhan Zhang, Yuanbo Yang, Yue Wang, Yujun Shen, Yiyi Liao
Collecting accurate camera poses of training images has been shown to well serve the learning of 3D-aware generative adversarial networks (GANs) yet can be quite expensive in practice. This work targets learning 3D-aware GANs from unposed images, for which we propose to perform on-the-fly pose estimation of training images with a learned template feature field (TeFF). Concretely, in addition to a generative radiance field as in previous approaches, we ask the generator to also learn a field from 2D semantic features while sharing the density from the radiance field. Such a framework allows us to acquire a canonical 3D feature template leveraging the dataset mean discovered by the generative model, and further efficiently estimate the pose parameters on real data. Experimental results on various challenging datasets demonstrate the superiority of our approach over state-of-the-art alternatives from both the qualitative and the quantitative perspectives.
Read more4/9/2024
🏋️
0
Training and Tuning Generative Neural Radiance Fields for Attribute-Conditional 3D-Aware Face Generation
Jichao Zhang, Aliaksandr Siarohin, Yahui Liu, Hao Tang, Nicu Sebe, Wei Wang
Generative Neural Radiance Fields (GNeRF)-based 3D-aware GANs have showcased remarkable prowess in crafting high-fidelity images while upholding robust 3D consistency, particularly face generation. However, specific existing models prioritize view consistency over disentanglement, leading to constrained semantic or attribute control during the generation process. While many methods have explored incorporating semantic masks or leveraging 3D Morphable Models (3DMM) priors to imbue models with semantic control, these methods often demand training from scratch, entailing significant computational overhead. In this paper, we propose a novel approach: a conditional GNeRF model that integrates specific attribute labels as input, thus amplifying the controllability and disentanglement capabilities of 3D-aware generative models. Our approach builds upon a pre-trained 3D-aware face model, and we introduce a Training as Init and Optimizing for Tuning (TRIOT) method to train a conditional normalized flow module to enable the facial attribute editing, then optimize the latent vector to improve attribute-editing precision further. Our extensive experiments substantiate the efficacy of our model, showcasing its ability to generate high-quality edits with enhanced view consistency while safeguarding non-target regions. The code for our model is publicly available at https://github.com/zhangqianhui/TT-GNeRF.
Read more9/4/2024
0
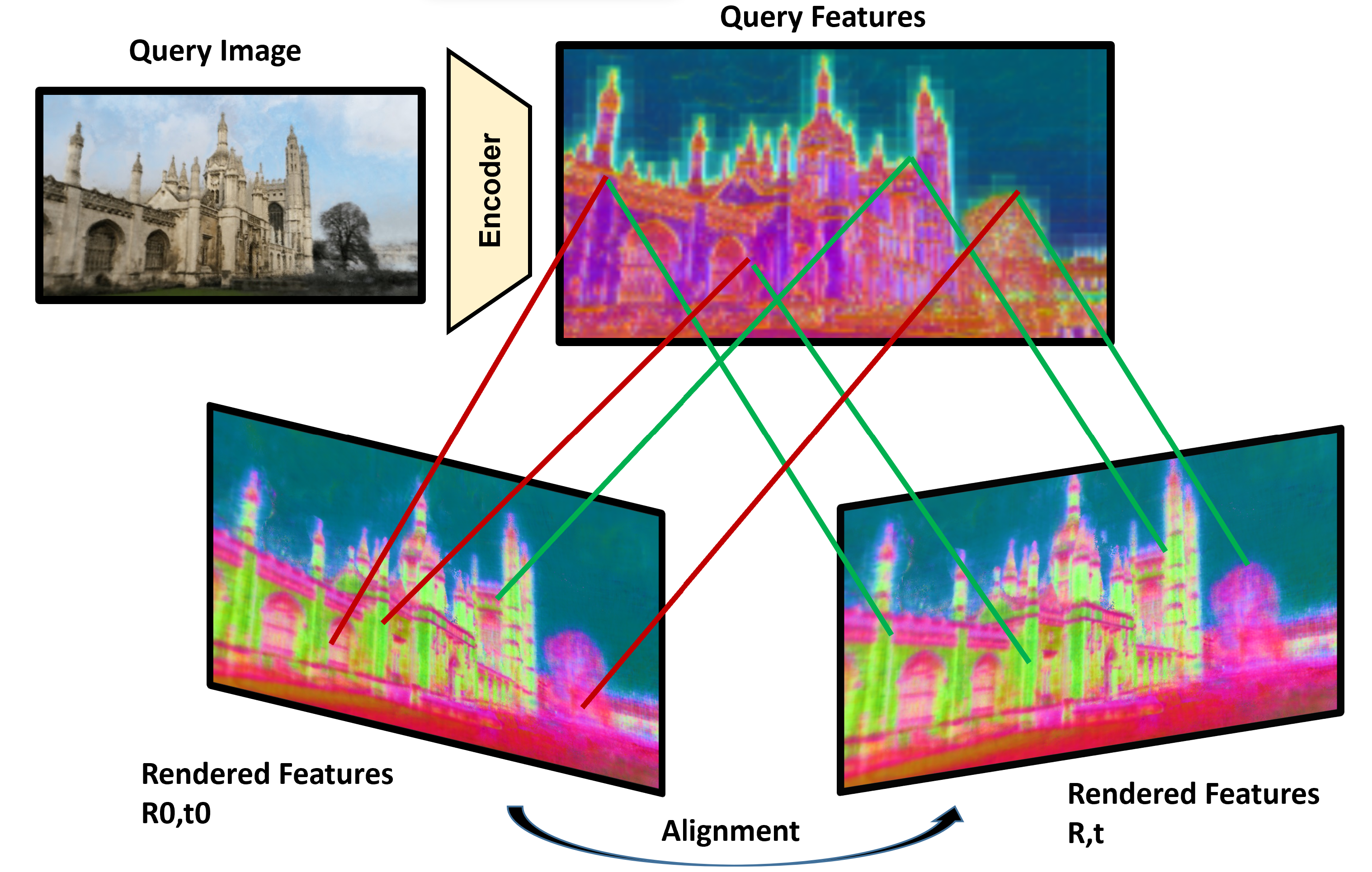
Self-supervised Learning of Neural Implicit Feature Fields for Camera Pose Refinement
Maxime Pietrantoni, Gabriela Csurka, Martin Humenberger, Torsten Sattler
Visual localization techniques rely upon some underlying scene representation to localize against. These representations can be explicit such as 3D SFM map or implicit, such as a neural network that learns to encode the scene. The former requires sparse feature extractors and matchers to build the scene representation. The latter might lack geometric grounding not capturing the 3D structure of the scene well enough. This paper proposes to jointly learn the scene representation along with a 3D dense feature field and a 2D feature extractor whose outputs are embedded in the same metric space. Through a contrastive framework we align this volumetric field with the image-based extractor and regularize the latter with a ranking loss from learned surface information. We learn the underlying geometry of the scene with an implicit field through volumetric rendering and design our feature field to leverage intermediate geometric information encoded in the implicit field. The resulting features are discriminative and robust to viewpoint change while maintaining rich encoded information. Visual localization is then achieved by aligning the image-based features and the rendered volumetric features. We show the effectiveness of our approach on real-world scenes, demonstrating that our approach outperforms prior and concurrent work on leveraging implicit scene representations for localization.
Read more6/13/2024
0
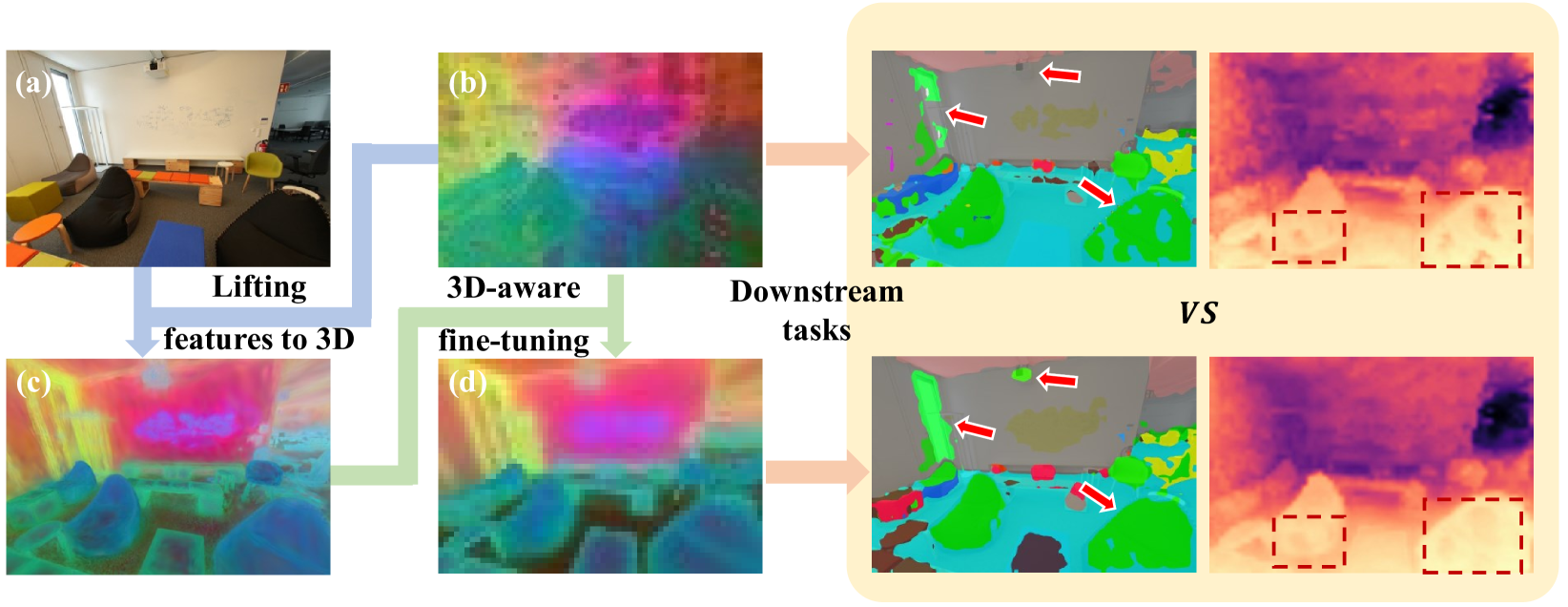
Improving 2D Feature Representations by 3D-Aware Fine-Tuning
Yuanwen Yue, Anurag Das, Francis Engelmann, Siyu Tang, Jan Eric Lenssen
Current visual foundation models are trained purely on unstructured 2D data, limiting their understanding of 3D structure of objects and scenes. In this work, we show that fine-tuning on 3D-aware data improves the quality of emerging semantic features. We design a method to lift semantic 2D features into an efficient 3D Gaussian representation, which allows us to re-render them for arbitrary views. Using the rendered 3D-aware features, we design a fine-tuning strategy to transfer such 3D awareness into a 2D foundation model. We demonstrate that models fine-tuned in that way produce features that readily improve downstream task performance in semantic segmentation and depth estimation through simple linear probing. Notably, though fined-tuned on a single indoor dataset, the improvement is transferable to a variety of indoor datasets and out-of-domain datasets. We hope our study encourages the community to consider injecting 3D awareness when training 2D foundation models. Project page: https://ywyue.github.io/FiT3D.
Read more7/30/2024