Learning from Imperfect Human Feedback: a Tale from Corruption-Robust Dueling

0

Sign in to get full access
Overview
• This paper explores the challenge of learning from imperfect human feedback, with a focus on a corruption-robust "dueling" approach. • The researchers propose a novel algorithm that can effectively learn from noisy or biased human feedback, which is a common issue in real-world applications. • The paper builds on related work in areas like contextual dueling bandits, iterative preference learning, and contrastive preference learning.
Plain English Explanation
The paper looks at a problem that often comes up when training AI systems using feedback from humans - the feedback can be imperfect or biased. Humans don't always make consistent or reliable judgments, and their preferences can be influenced by factors beyond the AI's control.
The researchers developed a new algorithm that can learn effectively even when the human feedback is noisy or corrupted in some way. The key idea is to use a "dueling" approach, where the AI system compares different options and tries to determine which one is better, rather than relying on absolute ratings from the human.
This dueling approach makes the system more robust to issues like inconsistent or biased human feedback. The paper shows how this corruption-robust dueling algorithm can outperform other methods in a variety of test scenarios.
Technical Explanation
The paper presents a novel algorithm for learning from human feedback in a corruption-robust manner. The core idea is to use a "dueling bandit" framework, where the AI system compares different options (e.g. AI agents or actions) and tries to determine which one is preferable, rather than relying on absolute ratings or rankings from the human.
This dueling approach makes the system more resilient to issues like inconsistency, bias, or other forms of corruption in the human feedback. The researchers build on prior work in contextual dueling bandits and contrastive preference learning to develop a novel algorithm called "Corruption-Robust Dueling" (CRD).
Through extensive experiments, the authors demonstrate that CRD can outperform alternative methods in terms of learning performance, especially when the human feedback is noisy or biased. They also provide theoretical guarantees on the algorithm's convergence and sample complexity.
Critical Analysis
The paper addresses an important and practical challenge in building AI systems that learn from human feedback. The authors' corruption-robust dueling approach is a clever innovation that helps mitigate the issues of imperfect or biased feedback.
One limitation mentioned in the paper is that the CRD algorithm assumes the human feedback is "oblivious" to the AI's actions, meaning the feedback is not strategically influenced by the AI's behavior. In real-world settings, this assumption may not always hold, and the human feedback could become adversarial or manipulative.
Additionally, the paper focuses on a specific feedback model and does not explore more complex, multi-faceted human preferences. It would be interesting to see how the CRD approach could be extended to handle richer forms of feedback, such as personalized preferences or natural language explanations.
Overall, this is a well-designed and insightful study that makes a valuable contribution to the field of learning from human feedback. The corruption-robust dueling concept is a promising direction for developing more reliable and practical AI systems.
Conclusion
This paper presents a novel algorithm for learning from imperfect human feedback, a common challenge in real-world AI applications. The key innovation is a corruption-robust "dueling" approach that allows the AI system to learn effectively even when the human feedback is noisy, biased, or inconsistent.
The authors demonstrate the effectiveness of their Corruption-Robust Dueling (CRD) algorithm through extensive experiments, showing it can outperform alternative methods. While the paper has some limitations, such as the assumption of oblivious human feedback, it represents an important step forward in building AI systems that can reliably learn from flawed human input.
As AI continues to become more integrated into our lives, developing techniques to handle imperfect human feedback will be crucial. The insights and methods presented in this paper contribute to this critical area of research and could have significant implications for the future of human-AI interaction and collaboration.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Learning from Imperfect Human Feedback: a Tale from Corruption-Robust Dueling
Yuwei Cheng, Fan Yao, Xuefeng Liu, Haifeng Xu
This paper studies Learning from Imperfect Human Feedback (LIHF), motivated by humans' potential irrationality or imperfect perception of true preference. We revisit the classic dueling bandit problem as a model of learning from comparative human feedback, and enrich it by casting the imperfection in human feedback as agnostic corruption to user utilities. We start by identifying the fundamental limits of LIHF and prove a regret lower bound of $Omega(max{T^{1/2},C})$, even when the total corruption $C$ is known and when the corruption decays gracefully over time (i.e., user feedback becomes increasingly more accurate). We then turn to design robust algorithms applicable in real-world scenarios with arbitrary corruption and unknown $C$. Our key finding is that gradient-based algorithms enjoy a smooth efficiency-robustness tradeoff under corruption by varying their learning rates. Specifically, under general concave user utility, Dueling Bandit Gradient Descent (DBGD) of Yue and Joachims (2009) can be tuned to achieve regret $O(T^{1-alpha} + T^{ alpha} C)$ for any given parameter $alpha in (0, frac{1}{4}]$. Additionally, this result enables us to pin down the regret lower bound of the standard DBGD (the $alpha=1/4$ case) as $Omega(T^{3/4})$ for the first time, to the best of our knowledge. For strongly concave user utility we show a better tradeoff: there is an algorithm that achieves $O(T^{alpha} + T^{frac{1}{2}(1-alpha)}C)$ for any given $alpha in [frac{1}{2},1)$. Our theoretical insights are corroborated by extensive experiments on real-world recommendation data.
Read more5/21/2024
0
Nearly Optimal Algorithms for Contextual Dueling Bandits from Adversarial Feedback
Qiwei Di, Jiafan He, Quanquan Gu
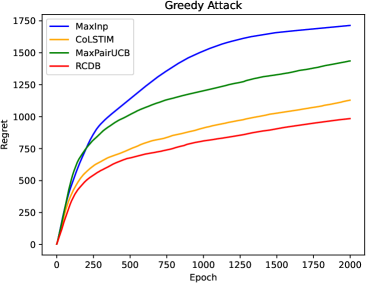
Learning from human feedback plays an important role in aligning generative models, such as large language models (LLM). However, the effectiveness of this approach can be influenced by adversaries, who may intentionally provide misleading preferences to manipulate the output in an undesirable or harmful direction. To tackle this challenge, we study a specific model within this problem domain--contextual dueling bandits with adversarial feedback, where the true preference label can be flipped by an adversary. We propose an algorithm namely robust contextual dueling bandit (algo), which is based on uncertainty-weighted maximum likelihood estimation. Our algorithm achieves an $tilde O(dsqrt{T}+dC)$ regret bound, where $T$ is the number of rounds, $d$ is the dimension of the context, and $ 0 le C le T$ is the total number of adversarial feedback. We also prove a lower bound to show that our regret bound is nearly optimal, both in scenarios with and without ($C=0$) adversarial feedback. Additionally, we conduct experiments to evaluate our proposed algorithm against various types of adversarial feedback. Experimental results demonstrate its superiority over the state-of-the-art dueling bandit algorithms in the presence of adversarial feedback.
Read more4/17/2024
0
Robust Reinforcement Learning from Corrupted Human Feedback
Alexander Bukharin, Ilgee Hong, Haoming Jiang, Zichong Li, Qingru Zhang, Zixuan Zhang, Tuo Zhao
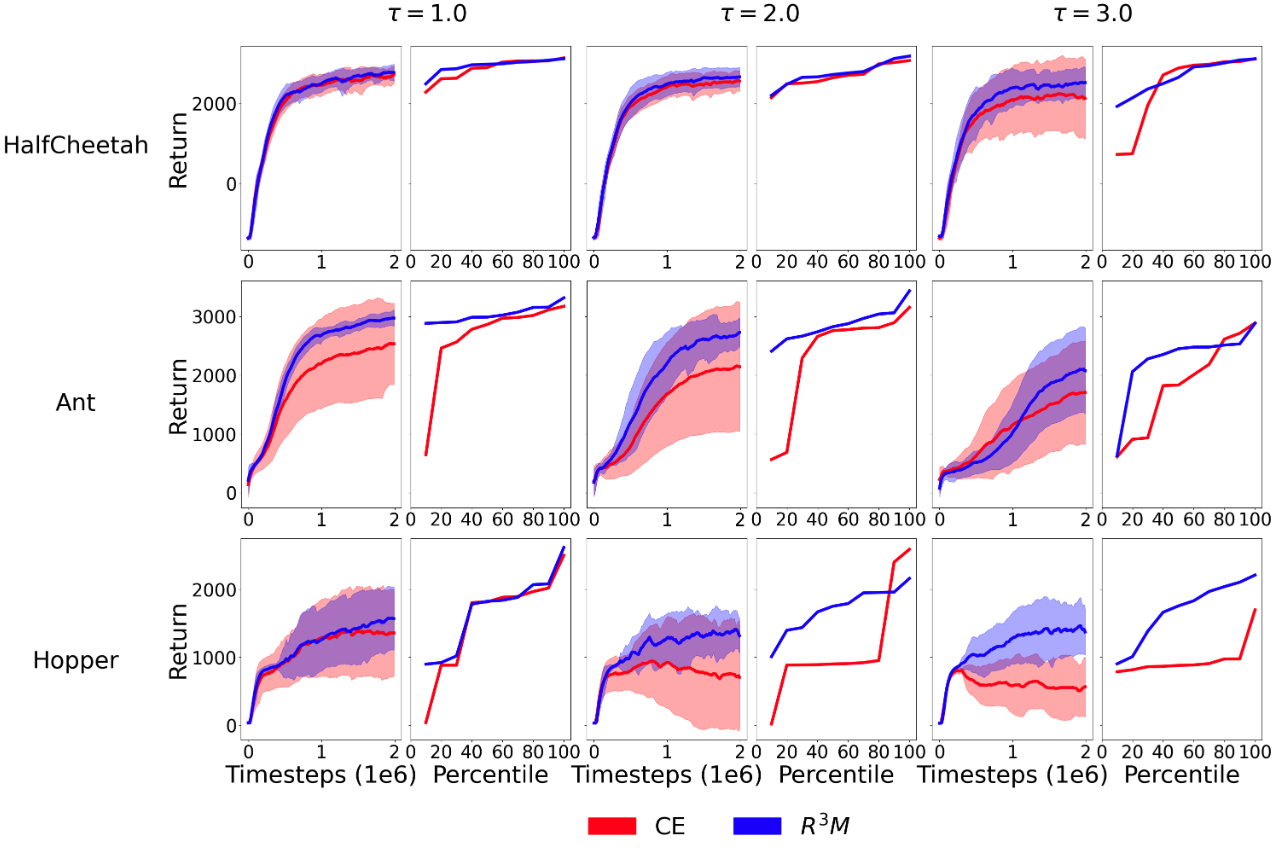
Reinforcement learning from human feedback (RLHF) provides a principled framework for aligning AI systems with human preference data. For various reasons, e.g., personal bias, context ambiguity, lack of training, etc, human annotators may give incorrect or inconsistent preference labels. To tackle this challenge, we propose a robust RLHF approach -- $R^3M$, which models the potentially corrupted preference label as sparse outliers. Accordingly, we formulate the robust reward learning as an $ell_1$-regularized maximum likelihood estimation problem. Computationally, we develop an efficient alternating optimization algorithm, which only incurs negligible computational overhead compared with the standard RLHF approach. Theoretically, we prove that under proper regularity conditions, $R^3M$ can consistently learn the underlying reward and identify outliers, provided that the number of outlier labels scales sublinearly with the preference sample size. Furthermore, we remark that $R^3M$ is versatile and can be extended to various preference optimization methods, including direct preference optimization (DPO). Our experiments on robotic control and natural language generation with large language models (LLMs) show that $R^3M$ improves robustness of the reward against several types of perturbations to the preference data.
Read more7/10/2024
0
Iterative Preference Learning from Human Feedback: Bridging Theory and Practice for RLHF under KL-Constraint
Wei Xiong, Hanze Dong, Chenlu Ye, Ziqi Wang, Han Zhong, Heng Ji, Nan Jiang, Tong Zhang
This paper studies the alignment process of generative models with Reinforcement Learning from Human Feedback (RLHF). We first identify the primary challenges of existing popular methods like offline PPO and offline DPO as lacking in strategical exploration of the environment. Then, to understand the mathematical principle of RLHF, we consider a standard mathematical formulation, the reverse-KL regularized contextual bandit for RLHF. Despite its widespread practical application, a rigorous theoretical analysis of this formulation remains open. We investigate its behavior in three distinct settings -- offline, online, and hybrid -- and propose efficient algorithms with finite-sample theoretical guarantees. Moving towards practical applications, our framework, with a robust approximation of the information-theoretical policy improvement oracle, naturally gives rise to several novel RLHF algorithms. This includes an iterative version of the Direct Preference Optimization (DPO) algorithm for online settings, and a multi-step rejection sampling strategy for offline scenarios. Our empirical evaluations on real-world alignment experiment of large language model demonstrate that these proposed methods significantly surpass existing strong baselines, such as DPO and Rejection Sampling Optimization (RSO), showcasing the connections between solid theoretical foundations and their potent practical implementations.
Read more5/2/2024