Like Humans to Few-Shot Learning through Knowledge Permeation of Vision and Text

0
👀
Sign in to get full access
Overview
- Few-shot learning aims to generalize a recognizer from seen categories to entirely novel scenarios.
- Advanced methods often introduce class names as prior knowledge to identify novel classes with only a few support samples.
- However, challenges remain in harnessing the mutual advantages of visual and textual knowledge.
- This paper proposes a coherent Bidirectional Knowledge Permeation strategy called BiKop to address these challenges.
Plain English Explanation
The goal of few-shot learning is to create recognizers that can identify objects from new categories, even when only a few example images are available. Some advanced methods have tried to use the names of the new categories as extra information to help with this task. However, it's still unclear how to best combine visual and textual knowledge to achieve comprehensive understanding.
This paper introduces a new approach called BiKop that is inspired by human intuition. The key idea is that a class name description provides a general representation, while individual images capture the specific details. BiKop establishes a hierarchical representation that links the general and specific information in both directions. Additionally, to address the tendency of the model to focus too much on the original categories, BiKop disentangles the base class semantics during training, allowing it to better learn about potential new categories.
The paper demonstrates that this BiKop approach outperforms other methods on several challenging benchmarks. By bridging the gap between general textual knowledge and specific visual information, BiKop represents an important step forward in few-shot learning.
Technical Explanation
The authors propose a Bidirectional Knowledge Permeation (BiKop) strategy to tackle the few-shot learning problem. BiKop is inspired by the human intuition that class name descriptions offer a general representation, while images capture the specificity of individuals.
The key technical components of BiKop are:
-
Hierarchical Joint Representation: BiKop establishes a hierarchical joint general-specific representation through bidirectional knowledge permeation. This allows the model to leverage both the high-level semantic information from class names and the detailed visual features from images.
-
Base-class Semantics Disentanglement: Recognizing that the joint representation can be biased towards the base (seen) classes, BiKop disentangles the base-class-relevant semantics during training. This mitigates the suppression of potential novel-class-relevant information.
The authors evaluate BiKop on four challenging few-shot learning benchmarks, including RSPG, Caltech-UCSD Birds-200-2011 (CUB), and VisualOnly. The results demonstrate the remarkable superiority of BiKop over other state-of-the-art few-shot learning methods.
Critical Analysis
The paper presents a well-designed and thoughtful approach to few-shot learning, addressing the challenges of effectively combining visual and textual knowledge. The hierarchical joint representation and the disentanglement of base-class semantics are novel and promising directions.
However, the paper does not discuss potential limitations or caveats of the BiKop approach. For example, it would be valuable to understand how the method performs on datasets with more diverse or complex class structures, or how it scales to larger numbers of novel classes.
Additionally, while the results are impressive, the paper could benefit from a deeper analysis of the specific strengths and weaknesses of BiKop compared to other few-shot learning methods. This would help readers better understand the unique contributions and potential areas for further improvement.
Conclusion
This paper introduces a coherent Bidirectional Knowledge Permeation (BiKop) strategy for few-shot learning. BiKop leverages the complementary strengths of textual and visual knowledge, establishing a hierarchical joint representation that bridges the gap between general class-level semantics and specific visual details.
By disentangling the base-class-relevant semantics during training, BiKop is able to better capture the information relevant to novel classes, leading to state-of-the-art performance on several challenging few-shot learning benchmarks.
The BiKop approach represents an important advancement in few-shot learning, demonstrating the value of carefully integrating different modalities of knowledge. As the field continues to evolve, this work provides a solid foundation for further explorations in harnessing the synergies between language and vision.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
👀
0
Like Humans to Few-Shot Learning through Knowledge Permeation of Vision and Text
Yuyu Jia, Qing Zhou, Wei Huang, Junyu Gao, Qi Wang
Few-shot learning aims to generalize the recognizer from seen categories to an entirely novel scenario. With only a few support samples, several advanced methods initially introduce class names as prior knowledge for identifying novel classes. However, obstacles still impede achieving a comprehensive understanding of how to harness the mutual advantages of visual and textual knowledge. In this paper, we propose a coherent Bidirectional Knowledge Permeation strategy called BiKop, which is grounded in a human intuition: A class name description offers a general representation, whereas an image captures the specificity of individuals. BiKop primarily establishes a hierarchical joint general-specific representation through bidirectional knowledge permeation. On the other hand, considering the bias of joint representation towards the base set, we disentangle base-class-relevant semantics during training, thereby alleviating the suppression of potential novel-class-relevant information. Experiments on four challenging benchmarks demonstrate the remarkable superiority of BiKop. Our code will be publicly available.
Read more5/24/2024
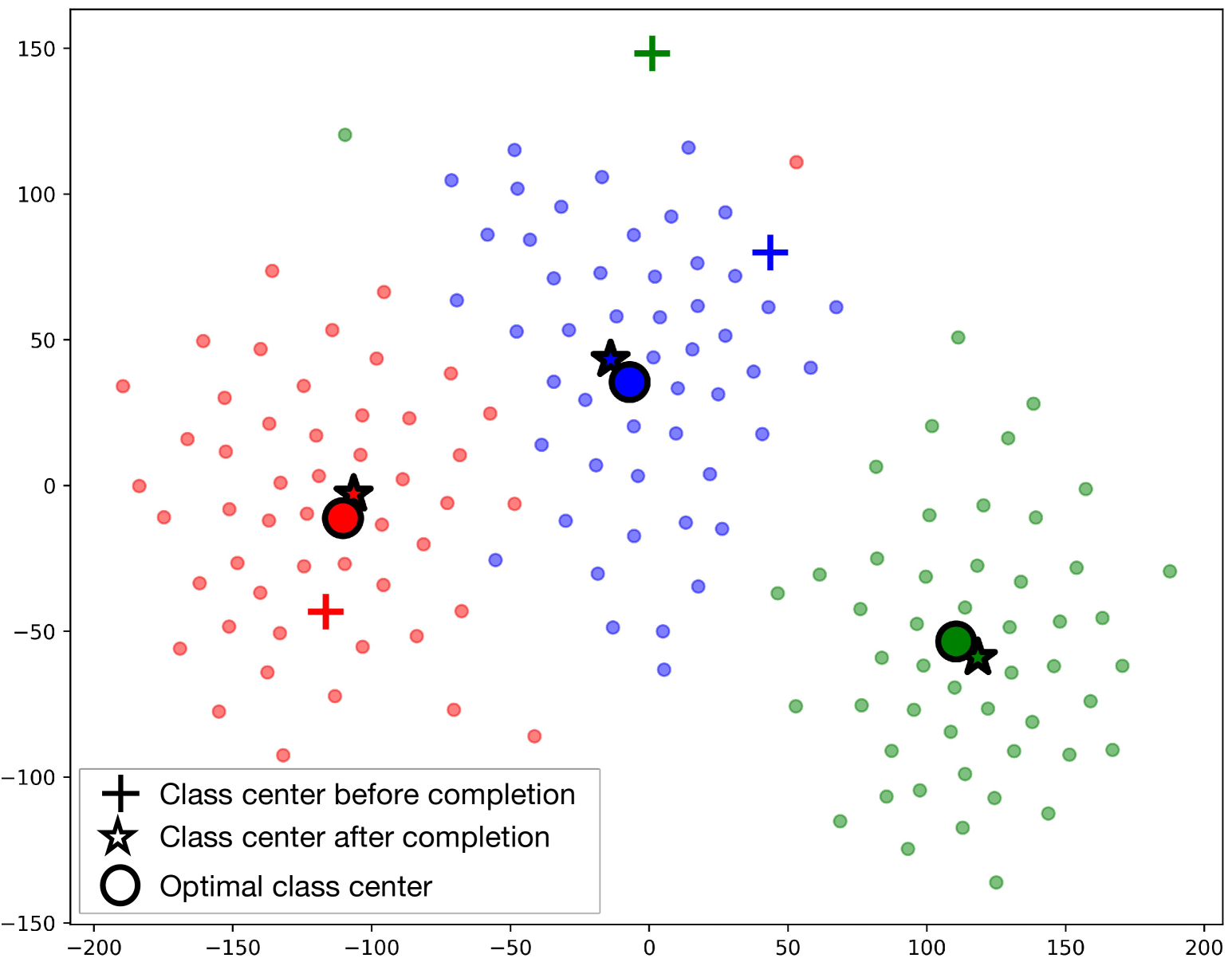
0
The Devil is in the Few Shots: Iterative Visual Knowledge Completion for Few-shot Learning
Yaohui Li, Qifeng Zhou, Haoxing Chen, Jianbing Zhang, Xinyu Dai, Hao Zhou
Contrastive Language-Image Pre-training (CLIP) has shown powerful zero-shot learning performance. Few-shot learning aims to further enhance the transfer capability of CLIP by giving few images in each class, aka 'few shots'. Most existing methods either implicitly learn from the few shots by incorporating learnable prompts or adapters, or explicitly embed them in a cache model for inference. However, the narrow distribution of few shots often contains incomplete class information, leading to biased visual knowledge with high risk of misclassification. To tackle this problem, recent methods propose to supplement visual knowledge by generative models or extra databases, which can be costly and time-consuming. In this paper, we propose an Iterative Visual Knowledge CompLetion (KCL) method to complement visual knowledge by properly taking advantages of unlabeled samples without access to any auxiliary or synthetic data. Specifically, KCL first measures the similarities between unlabeled samples and each category. Then, the samples with top confidence to each category is selected and collected by a designed confidence criterion. Finally, the collected samples are treated as labeled ones and added to few shots to jointly re-estimate the remaining unlabeled ones. The above procedures will be repeated for a certain number of iterations with more and more samples being collected until convergence, ensuring a progressive and robust knowledge completion process. Extensive experiments on 11 benchmark datasets demonstrate the effectiveness and efficiency of KCL as a plug-and-play module under both few-shot and zero-shot learning settings. Code is available at https://github.com/Mark-Sky/KCL.
Read more4/22/2024
🏷️
0
Learning from One and Only One Shot
Haizi Yu, Igor Mineyev, Lav R. Varshney, James A. Evans
Humans can generalize from only a few examples and from little pretraining on similar tasks. Yet, machine learning (ML) typically requires large data to learn or pre-learn to transfer. Motivated by nativism and artificial general intelligence, we directly model human-innate priors in abstract visual tasks such as character and doodle recognition. This yields a white-box model that learns general-appearance similarity by mimicking how humans naturally ``distort'' an object at first sight. Using just nearest-neighbor classification on this cognitively-inspired similarity space, we achieve human-level recognition with only $1$--$10$ examples per class and no pretraining. This differs from few-shot learning that uses massive pretraining. In the tiny-data regime of MNIST, EMNIST, Omniglot, and QuickDraw benchmarks, we outperform both modern neural networks and classical ML. For unsupervised learning, by learning the non-Euclidean, general-appearance similarity space in a $k$-means style, we achieve multifarious visual realizations of abstract concepts by generating human-intuitive archetypes as cluster centroids.
Read more5/22/2024
🛸
0
Rethinking Prior Information Generation with CLIP for Few-Shot Segmentation
Jin Wang, Bingfeng Zhang, Jian Pang, Honglong Chen, Weifeng Liu
Few-shot segmentation remains challenging due to the limitations of its labeling information for unseen classes. Most previous approaches rely on extracting high-level feature maps from the frozen visual encoder to compute the pixel-wise similarity as a key prior guidance for the decoder. However, such a prior representation suffers from coarse granularity and poor generalization to new classes since these high-level feature maps have obvious category bias. In this work, we propose to replace the visual prior representation with the visual-text alignment capacity to capture more reliable guidance and enhance the model generalization. Specifically, we design two kinds of training-free prior information generation strategy that attempts to utilize the semantic alignment capability of the Contrastive Language-Image Pre-training model (CLIP) to locate the target class. Besides, to acquire more accurate prior guidance, we build a high-order relationship of attention maps and utilize it to refine the initial prior information. Experiments on both the PASCAL-5{i} and COCO-20{i} datasets show that our method obtains a clearly substantial improvement and reaches the new state-of-the-art performance.
Read more5/15/2024