Learning Gaze-aware Compositional GAN

0

Sign in to get full access
Overview
- This paper introduces a Gaze-aware Compositional GAN (GaC-GAN) that can generate realistic face images with user-controlled gaze directions from limited annotations.
- The model is trained on a combination of real and synthetic data, leveraging domain-transferred synthetic data generation to improve performance with limited real-world training samples.
- The paper demonstrates the model's ability to generate high-quality face images with diverse gaze directions, outperforming previous state-of-the-art methods.
Plain English Explanation
The researchers developed an AI system that can create realistic-looking face images with the person's eyes looking in different directions, using only a small amount of real training data.
Typically, training AI models to generate images with specific gaze directions requires a large dataset of labeled face images. However, collecting and annotating such a dataset can be time-consuming and expensive.
To address this challenge, the researchers combined real face images with synthetically generated face data to train their model. This allowed the model to learn how to generate diverse gaze directions without needing a huge amount of real-world training data.
The resulting Gaze-aware Compositional GAN model can generate high-quality face images where the person's eyes are looking in the desired direction, outperforming previous approaches. This technology could be useful for applications like gaze-controllable face generation or subject-enhanced attention guidance in computer vision and graphics.
Technical Explanation
The researchers propose a Gaze-aware Compositional GAN (GaC-GAN) architecture that can generate realistic face images with user-controlled gaze directions from limited annotations. The key innovation is the use of domain-transferred synthetic data generation to augment the training data, allowing the model to learn robust gaze estimation and face generation capabilities.
The GaC-GAN model consists of a generator and a discriminator network. The generator takes as input a face image, a target gaze direction, and a noise vector, and outputs a new face image with the desired gaze. The discriminator evaluates the realism of the generated face images and provides feedback to the generator to improve its output.
To train the model, the researchers combined real face images from a dataset with synthetically generated face data that covers a wide range of gaze directions. This allowed the model to learn to generate diverse gaze directions without relying solely on the limited real-world training data.
The researchers demonstrate that the GaC-GAN outperforms previous state-of-the-art methods in generating high-quality face images with user-controlled gaze directions, as evaluated on both qualitative and quantitative metrics.
Critical Analysis
The paper presents a compelling approach to generating gaze-aware face images from limited annotations, leveraging synthetic data generation to overcome the challenge of data scarcity. However, the researchers acknowledge several limitations and areas for further research:
- The model's performance may degrade on faces with more extreme gaze directions or occlusions, which are not well-represented in the training data.
- The synthetic data generation process relies on several assumptions and simplifications that may not fully capture the complexity of real-world face images.
- The model is trained and evaluated on a relatively narrow domain of frontal-facing face images, and its performance on more diverse face poses and expressions remains to be explored.
Additionally, the paper does not discuss potential societal implications or ethical considerations of this technology, such as its use in deepfake generation or other applications that could raise privacy and security concerns.
Conclusion
The Gaze-aware Compositional GAN (GaC-GAN) introduced in this paper demonstrates a promising approach to generating realistic face images with user-controlled gaze directions from limited annotations. By leveraging domain-transferred synthetic data, the model can learn robust gaze estimation and face generation capabilities without requiring a large, manually annotated dataset.
This work contributes to the ongoing advancement of generative adversarial networks (GANs) and their applications in computer vision and graphics. The ability to generate high-quality, gaze-aware face images could have implications for various fields, from virtual reality and gaming to human-computer interaction and beyond.
However, as with any advanced AI technology, it is crucial to carefully consider the potential risks and ethical implications of such systems, especially regarding their use in the creation of synthetic media. Further research and responsible development will be necessary to ensure that this technology is applied in ways that benefit society while mitigating potential harms.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Learning Gaze-aware Compositional GAN
Nerea Aranjuelo, Siyu Huang, Ignacio Arganda-Carreras, Luis Unzueta, Oihana Otaegui, Hanspeter Pfister, Donglai Wei
Gaze-annotated facial data is crucial for training deep neural networks (DNNs) for gaze estimation. However, obtaining these data is labor-intensive and requires specialized equipment due to the challenge of accurately annotating the gaze direction of a subject. In this work, we present a generative framework to create annotated gaze data by leveraging the benefits of labeled and unlabeled data sources. We propose a Gaze-aware Compositional GAN that learns to generate annotated facial images from a limited labeled dataset. Then we transfer this model to an unlabeled data domain to take advantage of the diversity it provides. Experiments demonstrate our approach's effectiveness in generating within-domain image augmentations in the ETH-XGaze dataset and cross-domain augmentations in the CelebAMask-HQ dataset domain for gaze estimation DNN training. We also show additional applications of our work, which include facial image editing and gaze redirection.
Read more6/3/2024
✨
0
Domain-Adaptive Full-Face Gaze Estimation via Novel-View-Synthesis and Feature Disentanglement
Jiawei Qin, Takuru Shimoyama, Xucong Zhang, Yusuke Sugano
Along with the recent development of deep neural networks, appearance-based gaze estimation has succeeded considerably when training and testing within the same domain. Compared to the within-domain task, the variance of different domains makes the cross-domain performance drop severely, preventing gaze estimation deployment in real-world applications. Among all the factors, ranges of head pose and gaze are believed to play significant roles in the final performance of gaze estimation, while collecting large ranges of data is expensive. This work proposes an effective model training pipeline consisting of a training data synthesis and a gaze estimation model for unsupervised domain adaptation. The proposed data synthesis leverages the single-image 3D reconstruction to expand the range of the head poses from the source domain without requiring a 3D facial shape dataset. To bridge the inevitable gap between synthetic and real images, we further propose an unsupervised domain adaptation method suitable for synthetic full-face data. We propose a disentangling autoencoder network to separate gaze-related features and introduce background augmentation consistency loss to utilize the characteristics of the synthetic source domain. Through comprehensive experiments, it shows that the model using only our synthetic training data can perform comparably to real data extended with a large label range. Our proposed domain adaptation approach further improves the performance on multiple target domains. The code and data will be available at https://github.com/ut-vision/AdaptiveGaze.
Read more7/9/2024
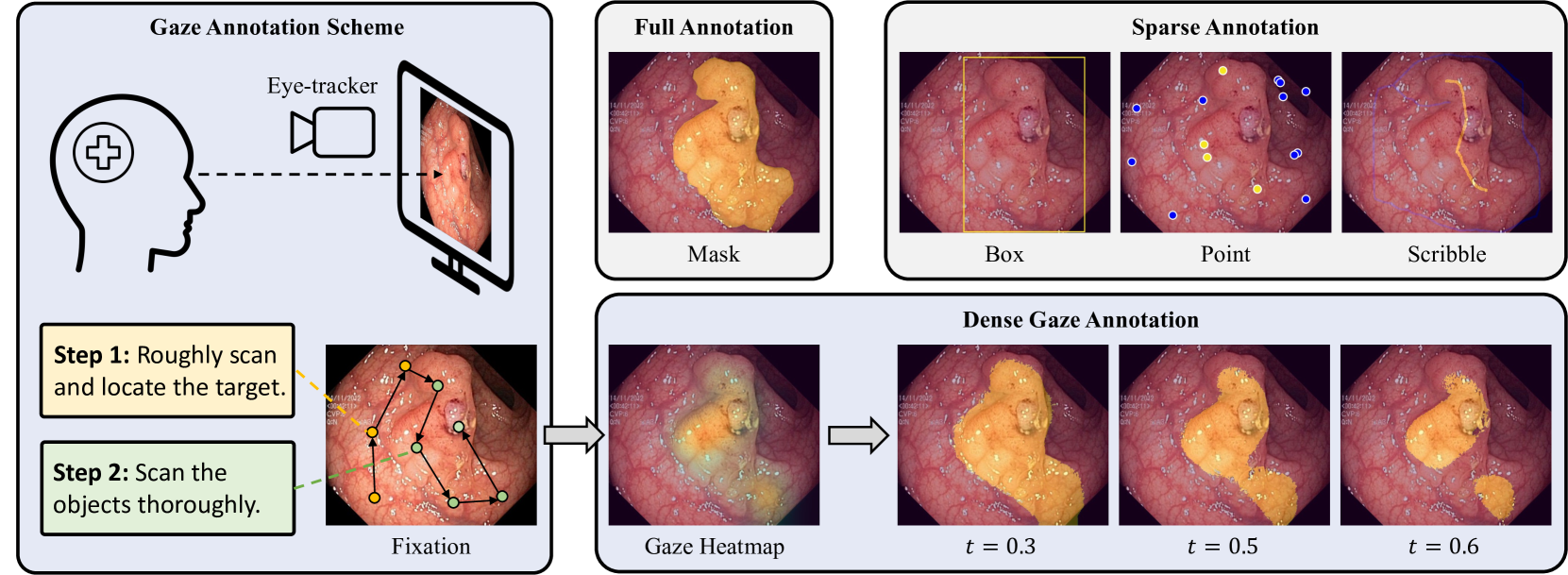
0
Weakly-supervised Medical Image Segmentation with Gaze Annotations
Yuan Zhong, Chenhui Tang, Yumeng Yang, Ruoxi Qi, Kang Zhou, Yuqi Gong, Pheng Ann Heng, Janet H. Hsiao, Qi Dou
Eye gaze that reveals human observational patterns has increasingly been incorporated into solutions for vision tasks. Despite recent explorations on leveraging gaze to aid deep networks, few studies exploit gaze as an efficient annotation approach for medical image segmentation which typically entails heavy annotating costs. In this paper, we propose to collect dense weak supervision for medical image segmentation with a gaze annotation scheme. To train with gaze, we propose a multi-level framework that trains multiple networks from discriminative human attention, simulated with a set of pseudo-masks derived by applying hierarchical thresholds on gaze heatmaps. Furthermore, to mitigate gaze noise, a cross-level consistency is exploited to regularize overfitting noisy labels, steering models toward clean patterns learned by peer networks. The proposed method is validated on two public medical datasets of polyp and prostate segmentation tasks. We contribute a high-quality gaze dataset entitled GazeMedSeg as an extension to the popular medical segmentation datasets. To the best of our knowledge, this is the first gaze dataset for medical image segmentation. Our experiments demonstrate that gaze annotation outperforms previous label-efficient annotation schemes in terms of both performance and annotation time. Our collected gaze data and code are available at: https://github.com/med-air/GazeMedSeg.
Read more7/11/2024
🛸
0
TextGaze: Gaze-Controllable Face Generation with Natural Language
Hengfei Wang, Zhongqun Zhang, Yihua Cheng, Hyung Jin Chang
Generating face image with specific gaze information has attracted considerable attention. Existing approaches typically input gaze values directly for face generation, which is unnatural and requires annotated gaze datasets for training, thereby limiting its application. In this paper, we present a novel gaze-controllable face generation task. Our approach inputs textual descriptions that describe human gaze and head behavior and generates corresponding face images. Our work first introduces a text-of-gaze dataset containing over 90k text descriptions spanning a dense distribution of gaze and head poses. We further propose a gaze-controllable text-to-face method. Our method contains a sketch-conditioned face diffusion module and a model-based sketch diffusion module. We define a face sketch based on facial landmarks and eye segmentation map. The face diffusion module generates face images from the face sketch, and the sketch diffusion module employs a 3D face model to generate face sketch from text description. Experiments on the FFHQ dataset show the effectiveness of our method. We will release our dataset and code for future research.
Read more9/10/2024