Learning Goal-Conditioned Representations for Language Reward Models

0

Sign in to get full access
Overview
- This paper presents a method for learning goal-conditioned representations for language reward models.
- The goal is to enable more interpretable and controllable reinforcement learning agents by conditioning the reward model on the desired goal or task.
- The approach involves training a neural network to predict a reward signal based on the current state and a target goal, using self-supervised learning on a large corpus of language data.
Plain English Explanation
The researchers developed a technique to help train AI systems that can learn to accomplish specific goals or tasks, rather than just optimizing for a single generic reward signal. This is important because in the real world, we often want AI assistants to be able to understand and work towards particular objectives, rather than just maximizing some abstract score.
The key idea is to train the AI system on a large amount of natural language data, and have it learn to predict a reward signal that depends on both the current state of the environment and the desired goal or task. This allows the system to learn representations that capture the relevant features for accomplishing different types of goals, rather than just learning a single monolithic reward function.
For example, an AI assistant could be trained to understand that when the goal is to "write a persuasive essay," it should focus on features like using logical arguments, appealing to the reader's emotions, and maintaining a coherent structure. Whereas if the goal is to "solve a math problem," it should focus more on identifying the relevant equations, step-by-step reasoning, and obtaining the correct numerical answer.
By conditioning the reward model on the desired goal, the researchers aim to make the AI's behavior more interpretable and controllable, so that it can be reliably deployed to accomplish specific objectives in the real world.
Technical Explanation
The core technical contribution of this paper is a novel architecture and training procedure for learning goal-conditioned representations for language reward models. The key elements are:
-
Goal Encoder: A neural network module that encodes the desired goal or task into a compact vector representation. This could be a natural language description of the goal, or a more structured specification.
-
State Encoder: Another neural network module that encodes the current state of the environment (e.g. the current text, dialogue, or world state) into a vector representation.
-
Reward Predictor: A neural network that takes the encoded goal and state as input, and outputs a predicted reward signal indicating how well the current state matches the desired goal.
-
Self-Supervised Training: The model is trained in a self-supervised manner on a large corpus of natural language data, by having it predict the reward signal for randomly sampled state-goal pairs. This allows the model to learn useful representations without requiring any manually annotated reward labels.
The researchers show that this goal-conditioned reward model architecture outperforms simpler baselines on a range of language-based reinforcement learning tasks, and provides more interpretable and controllable behavior.
Critical Analysis
One potential limitation of this approach is that it relies on the availability of a large corpus of natural language data to train the goal-conditioned reward model in a self-supervised manner. In some domains, such high-quality training data may not be readily available.
Additionally, while the goal-conditioned representations are designed to be more interpretable, the overall system complexity may still make it challenging to fully understand and audit the AI's decision-making process. Further research is needed to develop techniques for improving the transparency and explainability of these types of language-based reinforcement learning models.
Another area for further investigation is the robustness of the goal-conditioned reward model to distributional shift or adversarial attacks. If the model is deployed in the real world, it will likely encounter inputs and situations that differ from the training distribution, and it will be important to ensure that the model behaves reliably and safely in these cases.
Conclusion
This paper presents an innovative approach for learning goal-conditioned representations for language reward models, with the aim of enabling more interpretable and controllable reinforcement learning agents. By conditioning the reward signal on the desired goal or task, the researchers hope to develop AI systems that can be reliably deployed to accomplish specific objectives in the real world. While the approach shows promise, further research is needed to address potential limitations and ensure the robustness and transparency of these language-based reinforcement learning models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Learning Goal-Conditioned Representations for Language Reward Models
Vaskar Nath, Dylan Slack, Jeff Da, Yuntao Ma, Hugh Zhang, Spencer Whitehead, Sean Hendryx
Techniques that learn improved representations via offline data or self-supervised objectives have shown impressive results in traditional reinforcement learning (RL). Nevertheless, it is unclear how improved representation learning can benefit reinforcement learning from human feedback (RLHF) on language models (LMs). In this work, we propose training reward models (RMs) in a contrastive, $textit{goal-conditioned}$ fashion by increasing the representation similarity of future states along sampled preferred trajectories and decreasing the similarity along randomly sampled dispreferred trajectories. This objective significantly improves RM performance by up to 0.09 AUROC across challenging benchmarks, such as MATH and GSM8k. These findings extend to general alignment as well -- on the Helpful-Harmless dataset, we observe $2.3%$ increase in accuracy. Beyond improving reward model performance, we show this way of training RM representations enables improved $textit{steerability}$ because it allows us to evaluate the likelihood of an action achieving a particular goal-state (e.g., whether a solution is correct or helpful). Leveraging this insight, we find that we can filter up to $55%$ of generated tokens during majority voting by discarding trajectories likely to end up in an incorrect state, which leads to significant cost savings. We additionally find that these representations can perform fine-grained control by conditioning on desired future goal-states. For example, we show that steering a Llama 3 model towards helpful generations with our approach improves helpfulness by $9.6%$ over a supervised-fine-tuning trained baseline. Similarly, steering the model towards complex generations improves complexity by $21.6%$ over the baseline. Overall, we find that training RMs in this contrastive, goal-conditioned fashion significantly improves performance and enables model steerability.
Read more7/22/2024

0
Regularizing Hidden States Enables Learning Generalizable Reward Model for LLMs
Rui Yang, Ruomeng Ding, Yong Lin, Huan Zhang, Tong Zhang
Reward models trained on human preference data have been proven to be effective for aligning Large Language Models (LLMs) with human intent within the reinforcement learning from human feedback (RLHF) framework. However, the generalization capabilities of current reward models to unseen prompts and responses are limited. This limitation can lead to an unexpected phenomenon known as reward over-optimization, where excessive optimization of rewards results in a decline in actual performance. While previous research has advocated for constraining policy optimization, our study proposes a novel approach to enhance the reward model's generalization ability against distribution shifts by regularizing the hidden states. Specifically, we retain the base model's language model head and incorporate a suite of text-generation losses to preserve the hidden states' text generation capabilities, while concurrently learning a reward head behind the same hidden states. Our experimental results demonstrate that the introduced regularization technique markedly improves the accuracy of learned reward models across a variety of out-of-distribution (OOD) tasks and effectively alleviate the over-optimization issue in RLHF, offering a more reliable and robust preference learning paradigm.
Read more6/17/2024

0
TLDR: Unsupervised Goal-Conditioned RL via Temporal Distance-Aware Representations
Junik Bae, Kwanyoung Park, Youngwoon Lee
Unsupervised goal-conditioned reinforcement learning (GCRL) is a promising paradigm for developing diverse robotic skills without external supervision. However, existing unsupervised GCRL methods often struggle to cover a wide range of states in complex environments due to their limited exploration and sparse or noisy rewards for GCRL. To overcome these challenges, we propose a novel unsupervised GCRL method that leverages TemporaL Distance-aware Representations (TLDR). TLDR selects faraway goals to initiate exploration and computes intrinsic exploration rewards and goal-reaching rewards, based on temporal distance. Specifically, our exploration policy seeks states with large temporal distances (i.e. covering a large state space), while the goal-conditioned policy learns to minimize the temporal distance to the goal (i.e. reaching the goal). Our experimental results in six simulated robotic locomotion environments demonstrate that our method significantly outperforms previous unsupervised GCRL methods in achieving a wide variety of states.
Read more7/12/2024
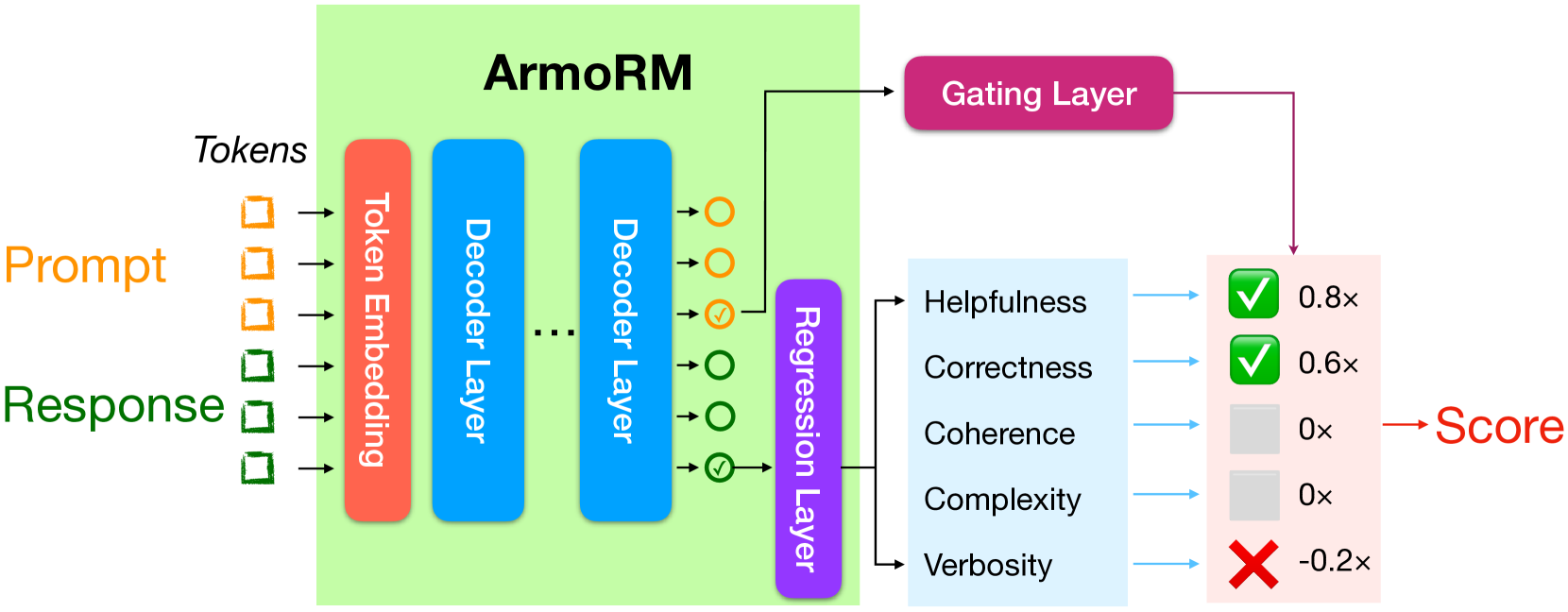
0
Interpretable Preferences via Multi-Objective Reward Modeling and Mixture-of-Experts
Haoxiang Wang, Wei Xiong, Tengyang Xie, Han Zhao, Tong Zhang
Reinforcement learning from human feedback (RLHF) has emerged as the primary method for aligning large language models (LLMs) with human preferences. The RLHF process typically starts by training a reward model (RM) using human preference data. Conventional RMs are trained on pairwise responses to the same user request, with relative ratings indicating which response humans prefer. The trained RM serves as a proxy for human preferences. However, due to the black-box nature of RMs, their outputs lack interpretability, as humans cannot intuitively understand why an RM thinks a response is good or not. As RMs act as human preference proxies, we believe they should be human-interpretable to ensure that their internal decision processes are consistent with human preferences and to prevent reward hacking in LLM alignment. To build RMs with interpretable preferences, we propose a two-stage approach: i) train an Absolute-Rating Multi-Objective Reward Model (ArmoRM) with multi-dimensional absolute-rating data, each dimension corresponding to a human-interpretable objective (e.g., honesty, verbosity, safety); ii) employ a Mixture-of-Experts (MoE) strategy with a gating network that automatically selects the most suitable reward objectives based on the context. We efficiently trained an ArmoRM with Llama-3 8B and a gating network consisting of a shallow MLP on top of the ArmoRM. Our trained model, ArmoRM-Llama3-8B, obtains state-of-the-art performance on RewardBench, a benchmark evaluating RMs for language modeling. Notably, the performance of our model surpasses the LLM-as-a-judge method with GPT-4 judges by a margin, and approaches the performance of the much larger Nemotron-4 340B reward model.
Read more6/19/2024