Learning Interpretable Fair Representations

0

Sign in to get full access
Overview
- This paper introduces a new method for learning interpretable and fair representations from data.
- The proposed approach aims to produce representations that are both informative for downstream tasks and fair with respect to sensitive attributes like race or gender.
- The method leverages an information-theoretic objective to learn representations that are maximally informative about the target task while minimizing information about sensitive attributes.
- Experiments on several real-world datasets demonstrate the effectiveness of the proposed method in achieving accurate and fair predictions.
Plain English Explanation
The paper focuses on the important challenge of learning interpretable fair representations. When building machine learning models, we often want the representations (or features) used by the model to be both informative for the task at hand and fair with respect to sensitive attributes like race or gender. This is crucial for ensuring the model's decisions are transparent and don't unfairly discriminate against certain groups.
The researchers introduce a new method that tackles this problem. Their key insight is to frame it as an information-theoretic optimization - they want to learn representations that capture a lot of information about the target task, but minimal information about the sensitive attributes. This allows them to balance the trade-off between fairness and accuracy.
Imagine you're training a model to predict someone's income based on their education, work experience, and other factors. You want the model to be as accurate as possible, but you also don't want it to unfairly discriminate based on race or gender. The proposed method would learn representations that are highly predictive of income, but stripped of information about race and gender.
The researchers demonstrate the effectiveness of their approach on several real-world datasets, showing it can achieve accurate and fair predictions. This work contributes to the broader goal of developing fair and interpretable AI systems that are transparent and equitable.
Technical Explanation
The key technical contribution of this paper is a novel information-theoretic framework for learning interpretable and fair representations. The core idea is to optimize an objective function that captures the trade-off between two competing goals:
- Maximizing the mutual information between the learned representations and the target task, to ensure the representations are informative.
- Minimizing the mutual information between the representations and the sensitive attributes, to ensure the representations are fair.
Mathematically, the objective can be written as:
max I(Y; Z) - λ * I(S; Z)
where Y is the target task, S are the sensitive attributes, Z are the learned representations, and λ is a hyperparameter controlling the fairness-accuracy trade-off.
The researchers derive an efficient algorithm to optimize this objective, and demonstrate its effectiveness on several real-world datasets, including income prediction, student performance, and recidivism risk assessment. Their experiments show that the proposed method can achieve accurate and fair predictions, outperforming baseline approaches.
One key technical insight is the use of a variational information bottleneck approach to tractably estimate the relevant mutual information terms. This allows the method to scale to high-dimensional data and complex models.
Critical Analysis
The paper presents a well-designed and technically sound approach for learning interpretable fair representations. The information-theoretic framing is elegant and the experimental results are compelling.
However, the paper does acknowledge some limitations and areas for future work. For example, the method assumes the sensitive attributes are known a priori, which may not always be the case in practice. Extensions to discover sensitive attributes from data could be an interesting direction.
Additionally, the paper focuses on achieving group-level fairness, but individual-level fairness is also an important consideration that is not addressed. Incorporating notions of individual fairness into the framework could be a valuable extension.
More broadly, the field of fair representation learning is an active area of research, with ongoing debates around the different definitions and desiderata of fairness. The authors' choice of fairness metric, while reasonable, is just one of many possible approaches.
Overall, this paper makes a significant contribution to the growing body of work on interpretable and fair machine learning. The proposed method provides a compelling solution to an important and challenging problem, and the information-theoretic perspective offers a principled foundation for future research in this direction.
Conclusion
This paper introduces a novel information-theoretic framework for learning interpretable and fair representations from data. The key idea is to optimize a trade-off between maximizing the informativeness of the representations for the target task and minimizing their dependence on sensitive attributes.
The proposed method demonstrates strong empirical performance on several real-world datasets, achieving accurate and fair predictions. This work represents an important step towards the development of transparent and equitable AI systems that can be deployed responsibly in high-stakes domains.
As the field of fair machine learning continues to evolve, this paper provides a principled and effective approach for learning representations that balance the competing objectives of accuracy and fairness. The information-theoretic perspective offers a rich foundation for further research in this direction.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Learning Interpretable Fair Representations
Tianhao Wang, Zana Buc{c}inca, Zilin Ma
Numerous approaches have been recently proposed for learning fair representations that mitigate unfair outcomes in prediction tasks. A key motivation for these methods is that the representations can be used by third parties with unknown objectives. However, because current fair representations are generally not interpretable, the third party cannot use these fair representations for exploration, or to obtain any additional insights, besides the pre-contracted prediction tasks. Thus, to increase data utility beyond prediction tasks, we argue that the representations need to be fair, yet interpretable. We propose a general framework for learning interpretable fair representations by introducing an interpretable prior knowledge during the representation learning process. We implement this idea and conduct experiments with ColorMNIST and Dsprite datasets. The results indicate that in addition to being interpretable, our representations attain slightly higher accuracy and fairer outcomes in a downstream classification task compared to state-of-the-art fair representations.
Read more6/26/2024
👁️
0
Interpretable Representations in Explainable AI: From Theory to Practice
Kacper Sokol, Peter Flach
Interpretable representations are the backbone of many explainers that target black-box predictive systems based on artificial intelligence and machine learning algorithms. They translate the low-level data representation necessary for good predictive performance into high-level human-intelligible concepts used to convey the explanatory insights. Notably, the explanation type and its cognitive complexity are directly controlled by the interpretable representation, tweaking which allows to target a particular audience and use case. However, many explainers built upon interpretable representations overlook their merit and fall back on default solutions that often carry implicit assumptions, thereby degrading the explanatory power and reliability of such techniques. To address this problem, we study properties of interpretable representations that encode presence and absence of human-comprehensible concepts. We demonstrate how they are operationalised for tabular, image and text data; discuss their assumptions, strengths and weaknesses; identify their core building blocks; and scrutinise their configuration and parameterisation. In particular, this in-depth analysis allows us to pinpoint their explanatory properties, desiderata and scope for (malicious) manipulation in the context of tabular data where a linear model is used to quantify the influence of interpretable concepts on a black-box prediction. Our findings lead to a range of recommendations for designing trustworthy interpretable representations; specifically, the benefits of class-aware (supervised) discretisation of tabular data, e.g., with decision trees, and sensitivity of image interpretable representations to segmentation granularity and occlusion colour.
Read more4/29/2024
🤷
0
Back to the Drawing Board for Fair Representation Learning
Ang'eline Pouget, Nikola Jovanovi'c, Mark Vero, Robin Staab, Martin Vechev
The goal of Fair Representation Learning (FRL) is to mitigate biases in machine learning models by learning data representations that enable high accuracy on downstream tasks while minimizing discrimination based on sensitive attributes. The evaluation of FRL methods in many recent works primarily focuses on the tradeoff between downstream fairness and accuracy with respect to a single task that was used to approximate the utility of representations during training (proxy task). This incentivizes retaining only features relevant to the proxy task while discarding all other information. In extreme cases, this can cause the learned representations to collapse to a trivial, binary value, rendering them unusable in transfer settings. In this work, we argue that this approach is fundamentally mismatched with the original motivation of FRL, which arises from settings with many downstream tasks unknown at training time (transfer tasks). To remedy this, we propose to refocus the evaluation protocol of FRL methods primarily around the performance on transfer tasks. A key challenge when conducting such an evaluation is the lack of adequate benchmarks. We address this by formulating four criteria that a suitable evaluation procedure should fulfill. Based on these, we propose TransFair, a benchmark that satisfies these criteria, consisting of novel variations of popular FRL datasets with carefully calibrated transfer tasks. In this setting, we reevaluate state-of-the-art FRL methods, observing that they often overfit to the proxy task, which causes them to underperform on certain transfer tasks. We further highlight the importance of task-agnostic learning signals for FRL methods, as they can lead to more transferrable representations.
Read more5/29/2024
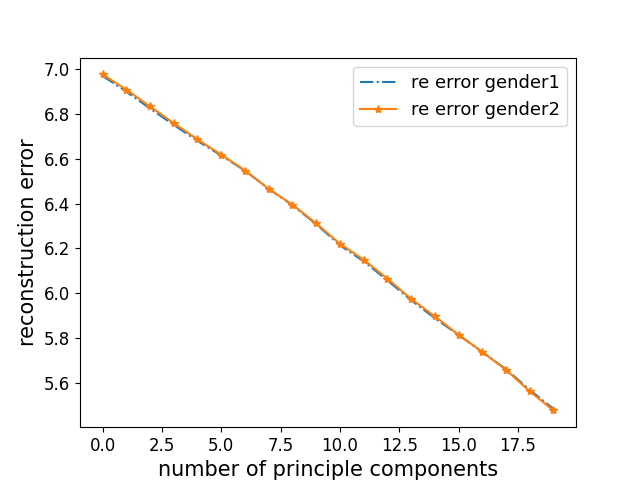
0
Closing the Gap in the Trade-off between Fair Representations and Accuracy
Biswajit Rout, Ananya B. Sai, Arun Rajkumar
The rapid developments of various machine learning models and their deployments in several applications has led to discussions around the importance of looking beyond the accuracies of these models. Fairness of such models is one such aspect that is deservedly gaining more attention. In this work, we analyse the natural language representations of documents and sentences (i.e., encodings) for any embedding-level bias that could potentially also affect the fairness of the downstream tasks that rely on them. We identify bias in these encodings either towards or against different sub-groups based on the difference in their reconstruction errors along various subsets of principal components. We explore and recommend ways to mitigate such bias in the encodings while also maintaining a decent accuracy in classification models that use them.
Read more4/16/2024