Diffusion Policies creating a Trust Region for Offline Reinforcement Learning
2405.19690
0
0

Abstract
Offline reinforcement learning (RL) leverages pre-collected datasets to train optimal policies. Diffusion Q-Learning (DQL), introducing diffusion models as a powerful and expressive policy class, significantly boosts the performance of offline RL. However, its reliance on iterative denoising sampling to generate actions slows down both training and inference. While several recent attempts have tried to accelerate diffusion-QL, the improvement in training and/or inference speed often results in degraded performance. In this paper, we introduce a dual policy approach, Diffusion Trusted Q-Learning (DTQL), which comprises a diffusion policy for pure behavior cloning and a practical one-step policy. We bridge the two polices by a newly introduced diffusion trust region loss. The diffusion policy maintains expressiveness, while the trust region loss directs the one-step policy to explore freely and seek modes within the region defined by the diffusion policy. DTQL eliminates the need for iterative denoising sampling during both training and inference, making it remarkably computationally efficient. We evaluate its effectiveness and algorithmic characteristics against popular Kullback-Leibler (KL) based distillation methods in 2D bandit scenarios and gym tasks. We then show that DTQL could not only outperform other methods on the majority of the D4RL benchmark tasks but also demonstrate efficiency in training and inference speeds. The PyTorch implementation is available at https://github.com/TianyuCodings/Diffusion_Trusted_Q_Learning.
Create account to get full access
Overview
• This paper introduces a new approach called "Diffusion Trusted Q-Learning" for offline reinforcement learning, which aims to create a trust region to safely update the policy.
• The key idea is to use a diffusion policy, which is a stochastic policy that explores the action space, to guide the agent's behavior and keep it within a trust region around the current policy.
• This approach is designed to address the challenges of offline reinforcement learning, where the agent must learn from a fixed dataset without interacting with the environment.
Plain English Explanation
The paper presents a new method called "Diffusion Trusted Q-Learning" for learning from random demonstrations, which is a type of offline reinforcement learning. In offline reinforcement learning, the agent has to learn a good policy (i.e., how to behave) without being able to interact with the environment directly. Instead, the agent has to learn from a fixed dataset of past experiences.
The key idea in this paper is to use a "diffusion policy" to guide the agent's behavior. A diffusion policy is a stochastic policy, meaning it doesn't always choose the same action, but explores the action space in a controlled way. This exploration helps the agent stay within a "trust region" around the current policy, which is important for safely updating the policy without causing it to diverge too much from the original.
The authors show that this Diffusion Trusted Q-Learning approach can outperform other offline reinforcement learning methods, particularly on tasks where the agent needs to explore the environment carefully to learn a good policy. This makes it a promising technique for robotics applications and other domains where direct interaction with the environment is limited or expensive.
Technical Explanation
The paper introduces a new algorithm called "Diffusion Trusted Q-Learning" for offline reinforcement learning. The key idea is to use a "diffusion policy" to guide the agent's behavior and keep it within a trust region around the current policy.
The diffusion policy is a stochastic policy that explores the action space in a controlled way, unlike a deterministic policy that always chooses the same action. By using the diffusion policy to generate actions, the agent can explore the environment while staying close to the current policy, which is important for safely updating the policy in an offline setting.
The authors formulate the problem as a constrained optimization, where the goal is to find the optimal Q-function and policy parameters that maximize the expected return, subject to a constraint that the new policy should stay within a trust region around the current policy. They solve this optimization problem using a trust region method and show that it outperforms other offline reinforcement learning methods, particularly on tasks that require careful exploration of the environment.
Critical Analysis
The paper presents a novel and promising approach to offline reinforcement learning, but there are a few potential limitations and areas for further research:
-
The authors assume access to a good initial policy, which may not always be available in practical scenarios. Extending the method to handle cases with poor initial policies or no prior knowledge would be valuable.
-
The paper focuses on discrete action spaces, and extending the approach to continuous action spaces may require additional research and modifications to the algorithm.
-
The theoretical analysis and convergence guarantees of the method are not fully explored, and further work could analyze the properties of the algorithm in more depth.
-
The paper does not provide extensive comparisons to other state-of-the-art offline reinforcement learning methods, such as Preferred Action Optimized Diffusion Policies or Diffusion-based Dynamics Models for Long-Horizon Rollout. Broader empirical evaluations could help better understand the strengths and limitations of the Diffusion Trusted Q-Learning approach.
Overall, the paper presents an interesting and potentially impactful contribution to the field of offline reinforcement learning, but further research is needed to fully explore the capabilities and limitations of the proposed method.
Conclusion
This paper introduces a novel approach called "Diffusion Trusted Q-Learning" for offline reinforcement learning, which uses a diffusion policy to guide the agent's behavior and keep it within a trust region around the current policy. This allows the agent to safely explore the environment and update the policy without causing it to diverge too much from the original.
The authors demonstrate that this approach can outperform other offline reinforcement learning methods, particularly on tasks that require careful exploration of the environment. This makes it a promising technique for applications in robotics and other domains where direct interaction with the environment is limited or expensive.
While the paper presents a valuable contribution, there are also some potential limitations and areas for further research, such as handling poor initial policies, extending to continuous action spaces, and conducting more extensive comparisons to other state-of-the-art methods. Overall, the Diffusion Trusted Q-Learning approach represents an important step forward in the field of offline reinforcement learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
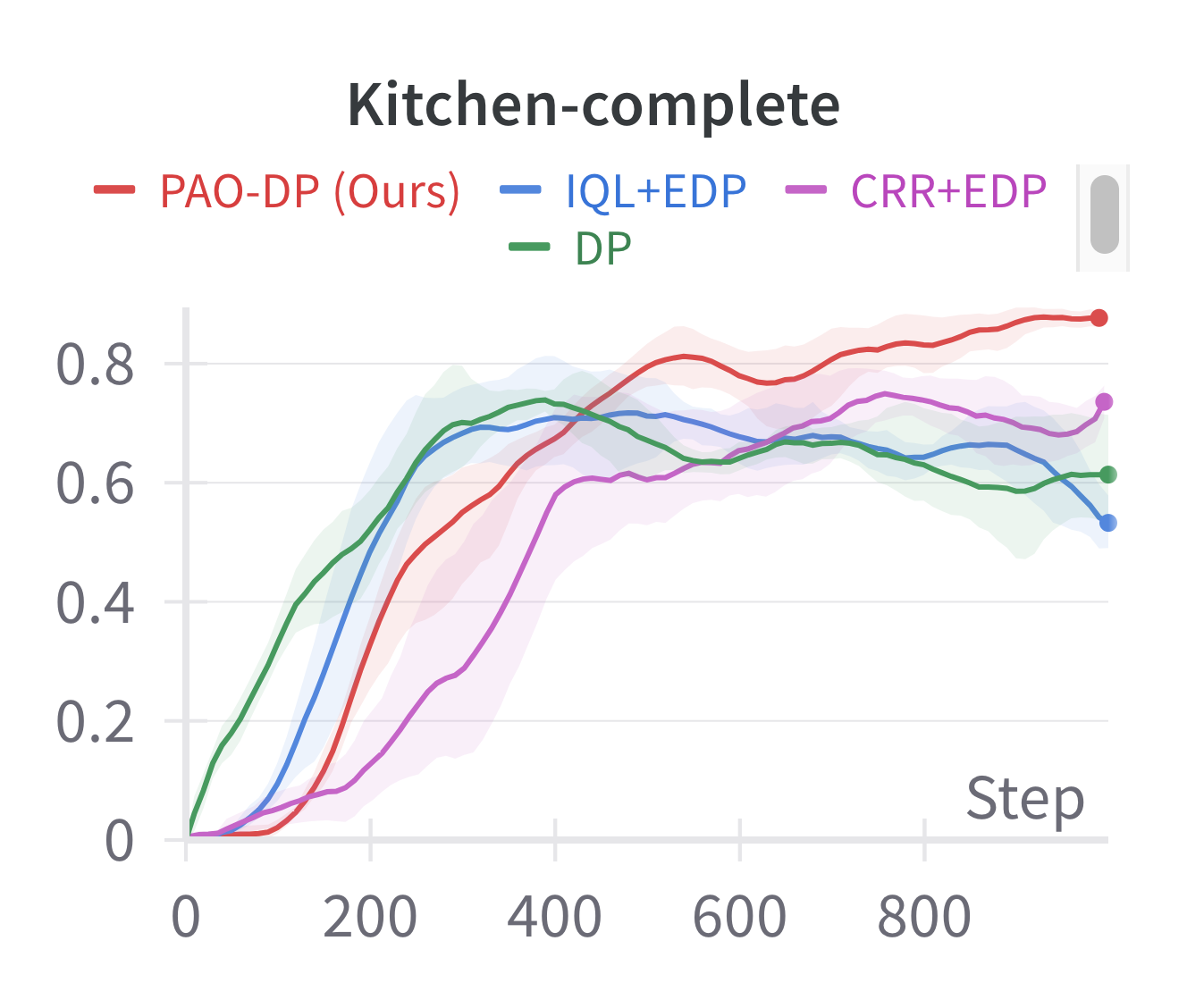
Preferred-Action-Optimized Diffusion Policies for Offline Reinforcement Learning
Tianle Zhang, Jiayi Guan, Lin Zhao, Yihang Li, Dongjiang Li, Zecui Zeng, Lei Sun, Yue Chen, Xuelong Wei, Lusong Li, Xiaodong He
0
0
Offline reinforcement learning (RL) aims to learn optimal policies from previously collected datasets. Recently, due to their powerful representational capabilities, diffusion models have shown significant potential as policy models for offline RL issues. However, previous offline RL algorithms based on diffusion policies generally adopt weighted regression to improve the policy. This approach optimizes the policy only using the collected actions and is sensitive to Q-values, which limits the potential for further performance enhancement. To this end, we propose a novel preferred-action-optimized diffusion policy for offline RL. In particular, an expressive conditional diffusion model is utilized to represent the diverse distribution of a behavior policy. Meanwhile, based on the diffusion model, preferred actions within the same behavior distribution are automatically generated through the critic function. Moreover, an anti-noise preference optimization is designed to achieve policy improvement by using the preferred actions, which can adapt to noise-preferred actions for stable training. Extensive experiments demonstrate that the proposed method provides competitive or superior performance compared to previous state-of-the-art offline RL methods, particularly in sparse reward tasks such as Kitchen and AntMaze. Additionally, we empirically prove the effectiveness of anti-noise preference optimization.
5/30/2024

Learning Multimodal Behaviors from Scratch with Diffusion Policy Gradient
Zechu Li, Rickmer Krohn, Tao Chen, Anurag Ajay, Pulkit Agrawal, Georgia Chalvatzaki
0
0
Deep reinforcement learning (RL) algorithms typically parameterize the policy as a deep network that outputs either a deterministic action or a stochastic one modeled as a Gaussian distribution, hence restricting learning to a single behavioral mode. Meanwhile, diffusion models emerged as a powerful framework for multimodal learning. However, the use of diffusion policies in online RL is hindered by the intractability of policy likelihood approximation, as well as the greedy objective of RL methods that can easily skew the policy to a single mode. This paper presents Deep Diffusion Policy Gradient (DDiffPG), a novel actor-critic algorithm that learns from scratch multimodal policies parameterized as diffusion models while discovering and maintaining versatile behaviors. DDiffPG explores and discovers multiple modes through off-the-shelf unsupervised clustering combined with novelty-based intrinsic motivation. DDiffPG forms a multimodal training batch and utilizes mode-specific Q-learning to mitigate the inherent greediness of the RL objective, ensuring the improvement of the diffusion policy across all modes. Our approach further allows the policy to be conditioned on mode-specific embeddings to explicitly control the learned modes. Empirical studies validate DDiffPG's capability to master multimodal behaviors in complex, high-dimensional continuous control tasks with sparse rewards, also showcasing proof-of-concept dynamic online replanning when navigating mazes with unseen obstacles.
6/4/2024

Diffusion Actor-Critic: Formulating Constrained Policy Iteration as Diffusion Noise Regression for Offline Reinforcement Learning
Linjiajie Fang, Ruoxue Liu, Jing Zhang, Wenjia Wang, Bing-Yi Jing
0
0
In offline reinforcement learning (RL), it is necessary to manage out-of-distribution actions to prevent overestimation of value functions. Policy-regularized methods address this problem by constraining the target policy to stay close to the behavior policy. Although several approaches suggest representing the behavior policy as an expressive diffusion model to boost performance, it remains unclear how to regularize the target policy given a diffusion-modeled behavior sampler. In this paper, we propose Diffusion Actor-Critic (DAC) that formulates the Kullback-Leibler (KL) constraint policy iteration as a diffusion noise regression problem, enabling direct representation of target policies as diffusion models. Our approach follows the actor-critic learning paradigm that we alternatively train a diffusion-modeled target policy and a critic network. The actor training loss includes a soft Q-guidance term from the Q-gradient. The soft Q-guidance grounds on the theoretical solution of the KL constraint policy iteration, which prevents the learned policy from taking out-of-distribution actions. For critic training, we train a Q-ensemble to stabilize the estimation of Q-gradient. Additionally, DAC employs lower confidence bound (LCB) to address the overestimation and underestimation of value targets due to function approximation error. Our approach is evaluated on the D4RL benchmarks and outperforms the state-of-the-art in almost all environments. Code is available at href{https://github.com/Fang-Lin93/DAC}{texttt{github.com/Fang-Lin93/DAC}}.
6/3/2024

Diffusion-based Reinforcement Learning via Q-weighted Variational Policy Optimization
Shutong Ding, Ke Hu, Zhenhao Zhang, Kan Ren, Weinan Zhang, Jingyi Yu, Jingya Wang, Ye Shi
0
0
Diffusion models have garnered widespread attention in Reinforcement Learning (RL) for their powerful expressiveness and multimodality. It has been verified that utilizing diffusion policies can significantly improve the performance of RL algorithms in continuous control tasks by overcoming the limitations of unimodal policies, such as Gaussian policies, and providing the agent with enhanced exploration capabilities. However, existing works mainly focus on the application of diffusion policies in offline RL, while their incorporation into online RL is less investigated. The training objective of the diffusion model, known as the variational lower bound, cannot be optimized directly in online RL due to the unavailability of 'good' actions. This leads to difficulties in conducting diffusion policy improvement. To overcome this, we propose a novel model-free diffusion-based online RL algorithm, Q-weighted Variational Policy Optimization (QVPO). Specifically, we introduce the Q-weighted variational loss, which can be proved to be a tight lower bound of the policy objective in online RL under certain conditions. To fulfill these conditions, the Q-weight transformation functions are introduced for general scenarios. Additionally, to further enhance the exploration capability of the diffusion policy, we design a special entropy regularization term. We also develop an efficient behavior policy to enhance sample efficiency by reducing the variance of the diffusion policy during online interactions. Consequently, the QVPO algorithm leverages the exploration capabilities and multimodality of diffusion policies, preventing the RL agent from converging to a sub-optimal policy. To verify the effectiveness of QVPO, we conduct comprehensive experiments on MuJoCo benchmarks. The final results demonstrate that QVPO achieves state-of-the-art performance on both cumulative reward and sample efficiency.
5/28/2024