Learning to Edit Visual Programs with Self-Supervision
2406.02383
0
0

Abstract
We design a system that learns how to edit visual programs. Our edit network consumes a complete input program and a visual target. From this input, we task our network with predicting a local edit operation that could be applied to the input program to improve its similarity to the target. In order to apply this scheme for domains that lack program annotations, we develop a self-supervised learning approach that integrates this edit network into a bootstrapped finetuning loop along with a network that predicts entire programs in one-shot. Our joint finetuning scheme, when coupled with an inference procedure that initializes a population from the one-shot model and evolves members of this population with the edit network, helps to infer more accurate visual programs. Over multiple domains, we experimentally compare our method against the alternative of using only the one-shot model, and find that even under equal search-time budgets, our editing-based paradigm provides significant advantages.
Create account to get full access
Overview
• This research paper explores a novel approach to learning to edit visual programs through self-supervision.
• The key idea is to leverage large datasets of visual programs and their edits to train a model that can generalize to new programs and edits, without requiring explicit annotations.
• The proposed method outperforms existing approaches on several benchmarks, demonstrating the potential of self-supervised learning for visual program editing.
Plain English Explanation
Visual programs are a way of representing and manipulating digital content, such as images, videos, or 3D scenes, using a programming-like interface. For example, you might use a visual programming tool to create an animation or edit a photograph. However, learning to edit these visual programs can be challenging, as it requires a deep understanding of the underlying structure and semantics.
The researchers in this paper propose a new approach to learning to edit visual programs through self-supervision. The idea is to leverage large datasets of existing visual programs and their edits, without requiring any explicit annotation or labeling. By learning from these existing examples, the model can develop a general understanding of how to edit visual programs, and then apply this knowledge to new, unseen programs.
This self-supervised approach has several advantages over traditional, supervised methods. First, it is much more scalable, as it can take advantage of the vast amounts of visual program data available on the internet and in various digital repositories. Second, it is more flexible, as the model can learn to perform a wide range of editing tasks, rather than being limited to a specific set of pre-defined operations.
The researchers demonstrate the effectiveness of their approach on several benchmark tasks, such as editing vector graphics and modifying 3D scenes. Their model outperforms existing methods, showing the potential of self-supervised learning for visual program editing.
Technical Explanation
The core of the proposed method is a self-supervised learning framework that allows the model to learn how to edit visual programs from a large dataset of existing programs and their edits. The key components of this framework are:
-
Visual Program Encoder: A neural network that takes a visual program as input and encodes it into a compact, latent representation. This representation captures the essential structure and semantics of the program.
-
Edit Predictor: Another neural network that takes the latent representation of a visual program, along with some edit instructions, and predicts the corresponding edits to the program.
-
Self-Supervision Task: During training, the model is presented with pairs of visual programs and their edits. The goal is to learn to predict the edits given the original program, without any explicit supervision or annotation.
By training the Visual Program Encoder and Edit Predictor jointly on this self-supervised task, the model can learn to generalize to new visual programs and edit tasks, without requiring additional labeled data.
The researchers evaluate their method on several benchmarks, including editing vector graphics, modifying 3D scenes, and instruction-based knowledge editing. The results demonstrate that their self-supervised approach outperforms existing, supervised methods, highlighting the potential of this technique for a wide range of visual program editing tasks.
Critical Analysis
The proposed self-supervised approach for learning to edit visual programs is a promising direction, but it is not without its limitations. One potential concern is the reliance on the availability of large, high-quality datasets of visual programs and their edits. While the researchers demonstrate the effectiveness of their method on several benchmark tasks, it remains to be seen how well it would scale to more diverse and complex visual programs encountered in real-world applications.
Additionally, the self-supervised training process may lead to biases or inconsistencies in the model's behavior, as it learns from the existing edits in the dataset, which may not always be optimal or consistent. Further research is needed to understand the potential issues and develop techniques to ensure the model's outputs are reliable and coherent.
Another area for further exploration is the interpretability of the model's editing decisions. While the self-supervised approach can potentially learn complex, non-linear mappings between programs and edits, it may be challenging to understand the reasoning behind the model's outputs. Developing techniques to explain the model's behavior could be valuable for users who need to understand and trust the model's editing decisions.
Conclusion
This research paper presents a novel approach to learning to edit visual programs through self-supervision, leveraging large datasets of existing programs and their edits. The proposed method outperforms existing, supervised techniques on several benchmarks, demonstrating the potential of this approach for a wide range of visual program editing tasks.
While the self-supervised framework has its limitations, the results suggest that this is a promising direction for further research and development. By continuing to explore self-supervised learning for visual program editing, researchers may be able to unlock new capabilities and applications in areas such as creative coding, digital content creation, and interactive user interfaces.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Self-Training Large Language Models for Improved Visual Program Synthesis With Visual Reinforcement
Zaid Khan, Vijay Kumar BG, Samuel Schulter, Yun Fu, Manmohan Chandraker
0
0
Visual program synthesis is a promising approach to exploit the reasoning abilities of large language models for compositional computer vision tasks. Previous work has used few-shot prompting with frozen LLMs to synthesize visual programs. Training an LLM to write better visual programs is an attractive prospect, but it is unclear how to accomplish this. No dataset of visual programs for training exists, and acquisition of a visual program dataset cannot be easily crowdsourced due to the need for expert annotators. To get around the lack of direct supervision, we explore improving the program synthesis abilities of an LLM using feedback from interactive experience. We propose a method where we exploit existing annotations for a vision-language task to improvise a coarse reward signal for that task, treat the LLM as a policy, and apply reinforced self-training to improve the visual program synthesis ability of the LLM for that task. We describe a series of experiments on object detection, compositional visual question answering, and image-text retrieval, and show that in each case, the self-trained LLM outperforms or performs on par with few-shot frozen LLMs that are an order of magnitude larger. Website: https://zaidkhan.me/ViReP
4/9/2024
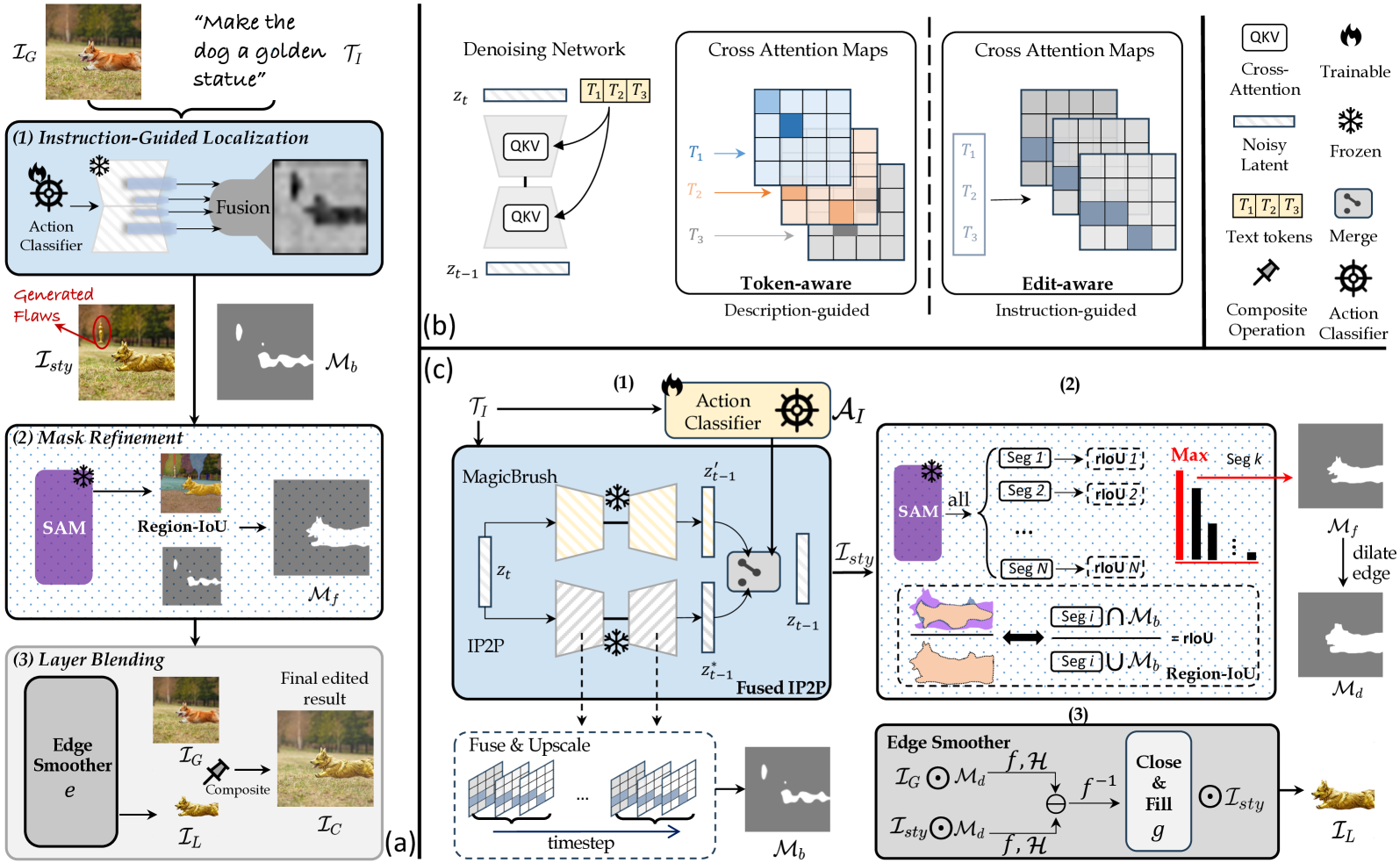
ZONE: Zero-Shot Instruction-Guided Local Editing
Shanglin Li, Bohan Zeng, Yutang Feng, Sicheng Gao, Xuhui Liu, Jiaming Liu, Li Lin, Xu Tang, Yao Hu, Jianzhuang Liu, Baochang Zhang
0
0
Recent advances in vision-language models like Stable Diffusion have shown remarkable power in creative image synthesis and editing.However, most existing text-to-image editing methods encounter two obstacles: First, the text prompt needs to be carefully crafted to achieve good results, which is not intuitive or user-friendly. Second, they are insensitive to local edits and can irreversibly affect non-edited regions, leaving obvious editing traces. To tackle these problems, we propose a Zero-shot instructiON-guided local image Editing approach, termed ZONE. We first convert the editing intent from the user-provided instruction (e.g., make his tie blue) into specific image editing regions through InstructPix2Pix. We then propose a Region-IoU scheme for precise image layer extraction from an off-the-shelf segment model. We further develop an edge smoother based on FFT for seamless blending between the layer and the image.Our method allows for arbitrary manipulation of a specific region with a single instruction while preserving the rest. Extensive experiments demonstrate that our ZONE achieves remarkable local editing results and user-friendliness, outperforming state-of-the-art methods. Code is available at https://github.com/lsl001006/ZONE.
4/15/2024

Unified Editing of Panorama, 3D Scenes, and Videos Through Disentangled Self-Attention Injection
Gihyun Kwon, Jangho Park, Jong Chul Ye
0
0
While text-to-image models have achieved impressive capabilities in image generation and editing, their application across various modalities often necessitates training separate models. Inspired by existing method of single image editing with self attention injection and video editing with shared attention, we propose a novel unified editing framework that combines the strengths of both approaches by utilizing only a basic 2D image text-to-image (T2I) diffusion model. Specifically, we design a sampling method that facilitates editing consecutive images while maintaining semantic consistency utilizing shared self-attention features during both reference and consecutive image sampling processes. Experimental results confirm that our method enables editing across diverse modalities including 3D scenes, videos, and panorama images.
5/28/2024

Learning to Infer Generative Template Programs for Visual Concepts
R. Kenny Jones, Siddhartha Chaudhuri, Daniel Ritchie
0
0
People grasp flexible visual concepts from a few examples. We explore a neurosymbolic system that learns how to infer programs that capture visual concepts in a domain-general fashion. We introduce Template Programs: programmatic expressions from a domain-specific language that specify structural and parametric patterns common to an input concept. Our framework supports multiple concept-related tasks, including few-shot generation and co-segmentation through parsing. We develop a learning paradigm that allows us to train networks that infer Template Programs directly from visual datasets that contain concept groupings. We run experiments across multiple visual domains: 2D layouts, Omniglot characters, and 3D shapes. We find that our method outperforms task-specific alternatives, and performs competitively against domain-specific approaches for the limited domains where they exist.
6/11/2024