Learning to Localize Actions in Instructional Videos with LLM-Based Multi-Pathway Text-Video Alignment

0
Sign in to get full access
Overview
- The paper describes a new method for localizing actions in instructional videos using large language models (LLMs) and multi-pathway text-video alignment.
- The approach combines textual and visual information to identify and localize the actions being performed in the video.
- The method is evaluated on several instructional video datasets and shows improved performance compared to existing techniques.
Plain English Explanation
The paper presents a new way to automatically identify and locate the specific actions being performed in instructional videos. The key idea is to combine the power of large language models (which can understand and reason about text) with visual information from the video.
The method works by aligning the text descriptions of the steps in the instructional video with the corresponding visual content. This allows the system to learn the connections between the textual descriptions and the visual elements depicting the actions.
Once this alignment is learned, the system can then localize the actions in new instructional videos by matching the text descriptions to the visual content. This allows it to pinpoint where in the video each step or action is taking place.
The key benefit of this approach is that it can work with a wide vocabulary of actions without requiring explicit labeling or training data for each possible action. The language model provides the necessary understanding of the textual descriptions, which is then combined with the visual information from the video.
Technical Explanation
The paper proposes a multi-pathway text-video alignment model for localizing actions in instructional videos. The model has two main components:
-
Text Pathway: This part uses a large language model (e.g. GPT-3) to encode the textual descriptions of the steps in the instructional video. This allows the model to understand the semantics and meaning of the step-by-step instructions.
-
Video Pathway: This component processes the visual information in the video using convolutional neural networks and other video processing techniques. This extracts relevant visual features that can be aligned with the textual descriptions.
The key innovation is that the model learns to align the textual and visual representations in a joint embedding space. This allows the model to associate the language model's understanding of the instructions with the corresponding visual elements in the video.
During inference, the model can then take a new instructional video and its associated text descriptions, and use the alignment to identify and localize the specific actions being performed in each step of the video.
The paper evaluates this approach on several instructional video datasets and demonstrates improved performance compared to previous methods for action localization in these types of videos.
Critical Analysis
The proposed method represents an interesting and promising approach to the problem of action localization in instructional videos. By leveraging large language models and aligning textual and visual representations, the model can effectively generalize to a wide range of actions without requiring exhaustive labeling of training data.
However, the paper does not fully address some potential limitations and areas for further research. For example, the performance of the model may be sensitive to the quality and coherence of the textual descriptions accompanying the videos. Noisy or ambiguous language could potentially degrade the alignment and localization accuracy.
Additionally, the paper focuses on instructional videos, which have a relatively structured format. It's unclear how well the approach would generalize to more open-ended or unstructured video content where the connections between language and visual elements may be less direct.
Further research could also explore ways to mitigate potential biases or limitations in the language models used, as well as investigating the interpretability and explainability of the learned text-video alignments.
Conclusion
The paper presents a novel approach to action localization in instructional videos that leverages the power of large language models and multi-pathway text-video alignment. By combining textual and visual information, the method can effectively identify and locate the specific actions being performed in these types of instructional videos.
The approach shows promising results and represents an interesting step forward in the field of video understanding. While the paper highlights some potential limitations, the key ideas and techniques could have broader applicability in areas such as procedural video understanding and open-vocabulary action localization.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Learning to Localize Actions in Instructional Videos with LLM-Based Multi-Pathway Text-Video Alignment
Yuxiao Chen, Kai Li, Wentao Bao, Deep Patel, Yu Kong, Martin Renqiang Min, Dimitris N. Metaxas
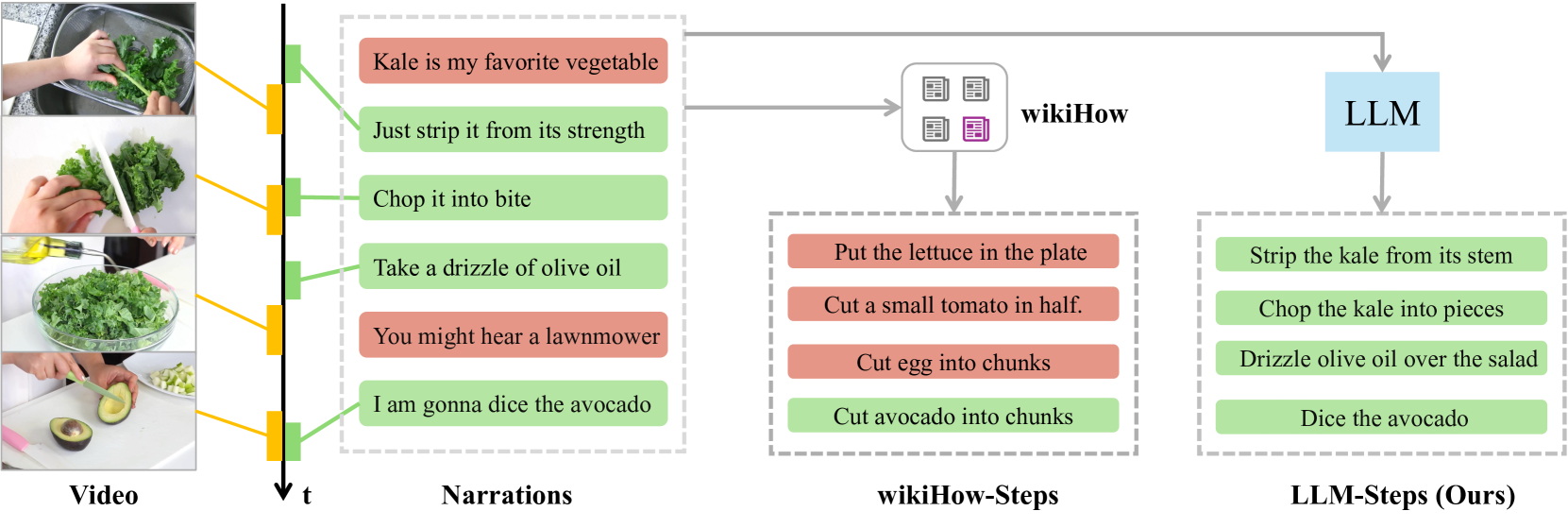
Learning to localize temporal boundaries of procedure steps in instructional videos is challenging due to the limited availability of annotated large-scale training videos. Recent works focus on learning the cross-modal alignment between video segments and ASR-transcripted narration texts through contrastive learning. However, these methods fail to account for the alignment noise, i.e., irrelevant narrations to the instructional task in videos and unreliable timestamps in narrations. To address these challenges, this work proposes a novel training framework. Motivated by the strong capabilities of Large Language Models (LLMs) in procedure understanding and text summarization, we first apply an LLM to filter out task-irrelevant information and summarize task-related procedure steps (LLM-steps) from narrations. To further generate reliable pseudo-matching between the LLM-steps and the video for training, we propose the Multi-Pathway Text-Video Alignment (MPTVA) strategy. The key idea is to measure alignment between LLM-steps and videos via multiple pathways, including: (1) step-narration-video alignment using narration timestamps, (2) direct step-to-video alignment based on their long-term semantic similarity, and (3) direct step-to-video alignment focusing on short-term fine-grained semantic similarity learned from general video domains. The results from different pathways are fused to generate reliable pseudo step-video matching. We conducted extensive experiments across various tasks and problem settings to evaluate our proposed method. Our approach surpasses state-of-the-art methods in three downstream tasks: procedure step grounding, step localization, and narration grounding by 5.9%, 3.1%, and 2.8%.
Read more9/25/2024

0
Multimodal Language Models for Domain-Specific Procedural Video Summarization
Nafisa Hussain
Videos serve as a powerful medium to convey ideas, tell stories, and provide detailed instructions, especially through long-format tutorials. Such tutorials are valuable for learning new skills at one's own pace, yet they can be overwhelming due to their length and dense content. Viewers often seek specific information, like precise measurements or step-by-step execution details, making it essential to extract and summarize key segments efficiently. An intelligent, time-sensitive video assistant capable of summarizing and detecting highlights in long videos is highly sought after. Recent advancements in Multimodal Large Language Models offer promising solutions to develop such an assistant. Our research explores the use of multimodal models to enhance video summarization and step-by-step instruction generation within specific domains. These models need to understand temporal events and relationships among actions across video frames. Our approach focuses on fine-tuning TimeChat to improve its performance in specific domains: cooking and medical procedures. By training the model on domain-specific datasets like Tasty for cooking and MedVidQA for medical procedures, we aim to enhance its ability to generate concise, accurate summaries of instructional videos. We curate and restructure these datasets to create high-quality video-centric instruction data. Our findings indicate that when finetuned on domain-specific procedural data, TimeChat can significantly improve the extraction and summarization of key instructional steps in long-format videos. This research demonstrates the potential of specialized multimodal models to assist with practical tasks by providing personalized, step-by-step guidance tailored to the unique aspects of each domain.
Read more7/9/2024

0
Open-vocabulary Temporal Action Localization using VLMs
Naoki Wake, Atsushi Kanehira, Kazuhiro Sasabuchi, Jun Takamatsu, Katsushi Ikeuchi
Video action localization aims to find timings of a specific action from a long video. Although existing learning-based approaches have been successful, those require annotating videos that come with a considerable labor cost. This paper proposes a learning-free, open-vocabulary approach based on emerging off-the-shelf vision-language models (VLM). The challenge stems from the fact that VLMs are neither designed to process long videos nor tailored for finding actions. We overcome these problems by extending an iterative visual prompting technique. Specifically, we sample video frames into a concatenated image with frame index labels, making a VLM guess a frame that is considered to be closest to the start/end of the action. Iterating this process by narrowing a sampling time window results in finding a specific frame of start and end of an action. We demonstrate that this sampling technique yields reasonable results, illustrating a practical extension of VLMs for understanding videos. A sample code is available at https://microsoft.github.io/VLM-Video-Action-Localization/.
Read more9/10/2024
0
Aligning Actions and Walking to LLM-Generated Textual Descriptions
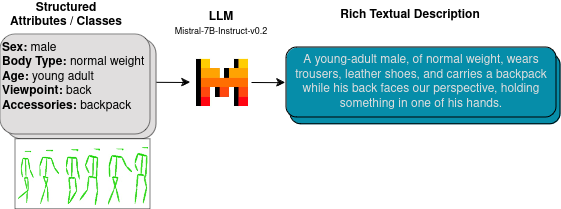
Radu Chivereanu, Adrian Cosma, Andy Catruna, Razvan Rughinis, Emilian Radoi
Large Language Models (LLMs) have demonstrated remarkable capabilities in various domains, including data augmentation and synthetic data generation. This work explores the use of LLMs to generate rich textual descriptions for motion sequences, encompassing both actions and walking patterns. We leverage the expressive power of LLMs to align motion representations with high-level linguistic cues, addressing two distinct tasks: action recognition and retrieval of walking sequences based on appearance attributes. For action recognition, we employ LLMs to generate textual descriptions of actions in the BABEL-60 dataset, facilitating the alignment of motion sequences with linguistic representations. In the domain of gait analysis, we investigate the impact of appearance attributes on walking patterns by generating textual descriptions of motion sequences from the DenseGait dataset using LLMs. These descriptions capture subtle variations in walking styles influenced by factors such as clothing choices and footwear. Our approach demonstrates the potential of LLMs in augmenting structured motion attributes and aligning multi-modal representations. The findings contribute to the advancement of comprehensive motion understanding and open up new avenues for leveraging LLMs in multi-modal alignment and data augmentation for motion analysis. We make the code publicly available at https://github.com/Radu1999/WalkAndText
Read more4/19/2024