Aligning Actions and Walking to LLM-Generated Textual Descriptions

0
Sign in to get full access
Overview
- This paper introduces a method for aligning actions and walking in a virtual environment with textual descriptions generated by large language models (LLMs).
- The key idea is to use the language-derived descriptions to guide the movement and actions of a virtual agent, creating a more natural and coherent experience.
- The approach involves training a model to translate the LLM-generated text into specific motor commands for the agent, allowing it to act out the described scenarios.
Plain English Explanation
The researchers have developed a way to connect text descriptions generated by powerful language models with the movement and actions of a virtual character. This can be useful for creating more immersive and realistic digital experiences, such as in video games or virtual reality.
The core idea is to take the text generated by the language model and use it to directly control how the virtual character moves and behaves. For example, if the language model describes a character walking across a room, picking up an object, and then placing it on a table, the system would translate that into the specific motor commands needed for the virtual character to carry out those actions.
This helps bridge the gap between the high-level, human-like language descriptions and the low-level control of a virtual agent. By aligning the textual descriptions with the agent's movements and actions, the researchers aim to create a more natural and coherent experience where the character's behavior matches the language.
This work builds on advancements in multimodal large language models that can understand and generate content across different modalities, like text, images, and video. The ability to connect language to physical actions is an important step towards more intelligent and interactive virtual agents.
Technical Explanation
The paper proposes a method for "Aligning Actions and Walking to LLM-Generated Textual Descriptions". The key components are:
-
LLM-Generated Descriptions: The system takes as input textual descriptions generated by a large language model (LLM), which provide high-level, human-like descriptions of actions and behaviors.
-
Action Alignment: The researchers train a model to translate the LLM-generated text into a sequence of low-level motor commands that can be executed by a virtual agent. This alignment allows the agent to "act out" the described behaviors.
-
Walking Alignment: Similarly, the system aligns the LLM-generated text with the parameters needed to control the virtual agent's walking motion, enabling the agent to navigate the environment in a way that matches the textual descriptions.
The paper presents experiments evaluating the system's ability to accurately execute actions and walking behaviors based on the LLM-generated descriptions. The results demonstrate the effectiveness of the approach in creating coherent and natural-looking interactions between the language and the virtual agent's movements.
[This work builds on and complements other research on integrating language and visual cues, as well as using large language models to generate and control interactive content](https://aimodels.fyi/papers/arxiv/integrating-language-derived-appearance-elements-visual-cues, https://aimodels.fyi/papers/arxiv/transforming-llms-into-cross-modal-cross-lingual). By aligning language and actions, the researchers aim to create more immersive and engaging virtual experiences.
Critical Analysis
The paper presents a promising approach for bridging the gap between high-level language descriptions and low-level control of virtual agents. However, there are a few potential limitations and areas for further research:
-
Scope and Complexity: The experiments in the paper focus on relatively simple actions and walking behaviors. Scaling this approach to handle more complex, multi-step scenarios or dynamic environments may require additional advancements.
-
Evaluation Metrics: The paper relies primarily on qualitative evaluations and user studies to assess the effectiveness of the system. Developing more quantitative metrics to measure the coherence and realism of the language-action alignment could provide additional insights.
-
Generalization: The current system is trained on specific LLM-generated descriptions and may not generalize well to novel or unseen language inputs. Exploring techniques to improve the model's ability to handle a broader range of textual descriptions would be valuable.
-
Real-World Applications: While the paper demonstrates the potential of this approach in virtual environments, applying it to real-world robotic or embodied AI systems would introduce additional challenges, such as dealing with sensor noise, physical constraints, and safety considerations.
Overall, the paper presents an interesting and promising approach for bridging the gap between language and physical actions in virtual environments. As large language models continue to advance and become more integrated with other modalities, this type of research will be crucial for developing more natural and intelligent interactive systems.
Conclusion
This paper introduces a method for aligning actions and walking in a virtual environment with textual descriptions generated by large language models (LLMs). The key idea is to use the language-derived descriptions to guide the movement and actions of a virtual agent, creating a more natural and coherent experience.
The researchers demonstrate a system that can translate LLM-generated text into specific motor commands for the agent, allowing it to act out the described scenarios. This helps bridge the gap between the high-level, human-like language descriptions and the low-level control of the virtual character.
The paper presents promising results and highlights the potential of this approach for creating more immersive and engaging virtual experiences. As large language models continue to advance and become more integrated with other modalities, this type of research will be crucial for developing more natural and intelligent interactive systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Aligning Actions and Walking to LLM-Generated Textual Descriptions
Radu Chivereanu, Adrian Cosma, Andy Catruna, Razvan Rughinis, Emilian Radoi
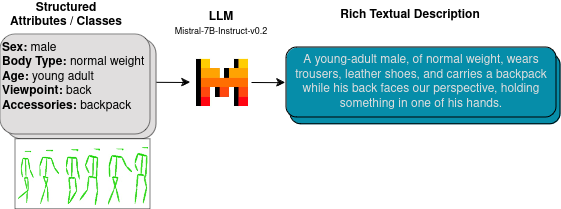
Large Language Models (LLMs) have demonstrated remarkable capabilities in various domains, including data augmentation and synthetic data generation. This work explores the use of LLMs to generate rich textual descriptions for motion sequences, encompassing both actions and walking patterns. We leverage the expressive power of LLMs to align motion representations with high-level linguistic cues, addressing two distinct tasks: action recognition and retrieval of walking sequences based on appearance attributes. For action recognition, we employ LLMs to generate textual descriptions of actions in the BABEL-60 dataset, facilitating the alignment of motion sequences with linguistic representations. In the domain of gait analysis, we investigate the impact of appearance attributes on walking patterns by generating textual descriptions of motion sequences from the DenseGait dataset using LLMs. These descriptions capture subtle variations in walking styles influenced by factors such as clothing choices and footwear. Our approach demonstrates the potential of LLMs in augmenting structured motion attributes and aligning multi-modal representations. The findings contribute to the advancement of comprehensive motion understanding and open up new avenues for leveraging LLMs in multi-modal alignment and data augmentation for motion analysis. We make the code publicly available at https://github.com/Radu1999/WalkAndText
Read more4/19/2024
0
MotionLLM: Multimodal Motion-Language Learning with Large Language Models
Qi Wu, Yubo Zhao, Yifan Wang, Yu-Wing Tai, Chi-Keung Tang
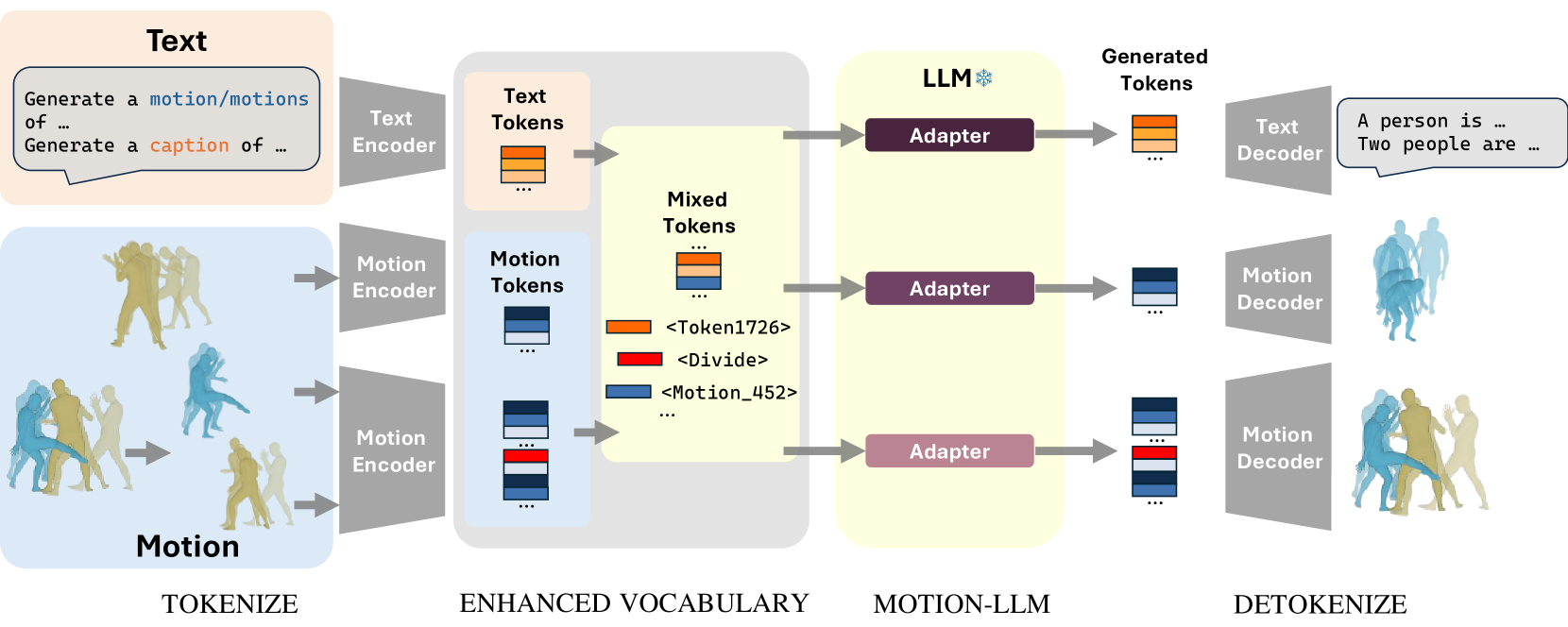
Recent advancements in Multimodal Large Language Models (MM-LLMs) have demonstrated promising potential in terms of generalization and robustness when applied to different modalities. While previous works have already achieved 3D human motion generation using various approaches including language modeling, they mostly % are mostly carefully designed use specialized architecture and are restricted to single-human motion generation. Inspired by the success of MM-LLMs, we propose MotionLLM, a simple and general framework that can achieve single-human, multi-human motion generation, and motion captioning by fine-tuning pre-trained LLMs. Specifically, we encode and quantize motions into discrete LLM-understandable tokens, which results in a unified vocabulary consisting of both motion and text tokens. With only 1--3% parameters of the LLMs trained by using adapters, our single-human motion generation achieves comparable results to those diffusion models and other trained-from-scratch transformer-based models. Additionally, we show that our approach is scalable and flexible, allowing easy extension to multi-human motion generation through autoregressive generation of single-human motions. Project page: https://knoxzhao.github.io/MotionLLM
Read more5/29/2024

0
MotionLLM: Understanding Human Behaviors from Human Motions and Videos
Ling-Hao Chen, Shunlin Lu, Ailing Zeng, Hao Zhang, Benyou Wang, Ruimao Zhang, Lei Zhang
This study delves into the realm of multi-modality (i.e., video and motion modalities) human behavior understanding by leveraging the powerful capabilities of Large Language Models (LLMs). Diverging from recent LLMs designed for video-only or motion-only understanding, we argue that understanding human behavior necessitates joint modeling from both videos and motion sequences (e.g., SMPL sequences) to capture nuanced body part dynamics and semantics effectively. In light of this, we present MotionLLM, a straightforward yet effective framework for human motion understanding, captioning, and reasoning. Specifically, MotionLLM adopts a unified video-motion training strategy that leverages the complementary advantages of existing coarse video-text data and fine-grained motion-text data to glean rich spatial-temporal insights. Furthermore, we collect a substantial dataset, MoVid, comprising diverse videos, motions, captions, and instructions. Additionally, we propose the MoVid-Bench, with carefully manual annotations, for better evaluation of human behavior understanding on video and motion. Extensive experiments show the superiority of MotionLLM in the caption, spatial-temporal comprehension, and reasoning ability.
Read more5/31/2024
0
Learning to Localize Actions in Instructional Videos with LLM-Based Multi-Pathway Text-Video Alignment
Yuxiao Chen, Kai Li, Wentao Bao, Deep Patel, Yu Kong, Martin Renqiang Min, Dimitris N. Metaxas
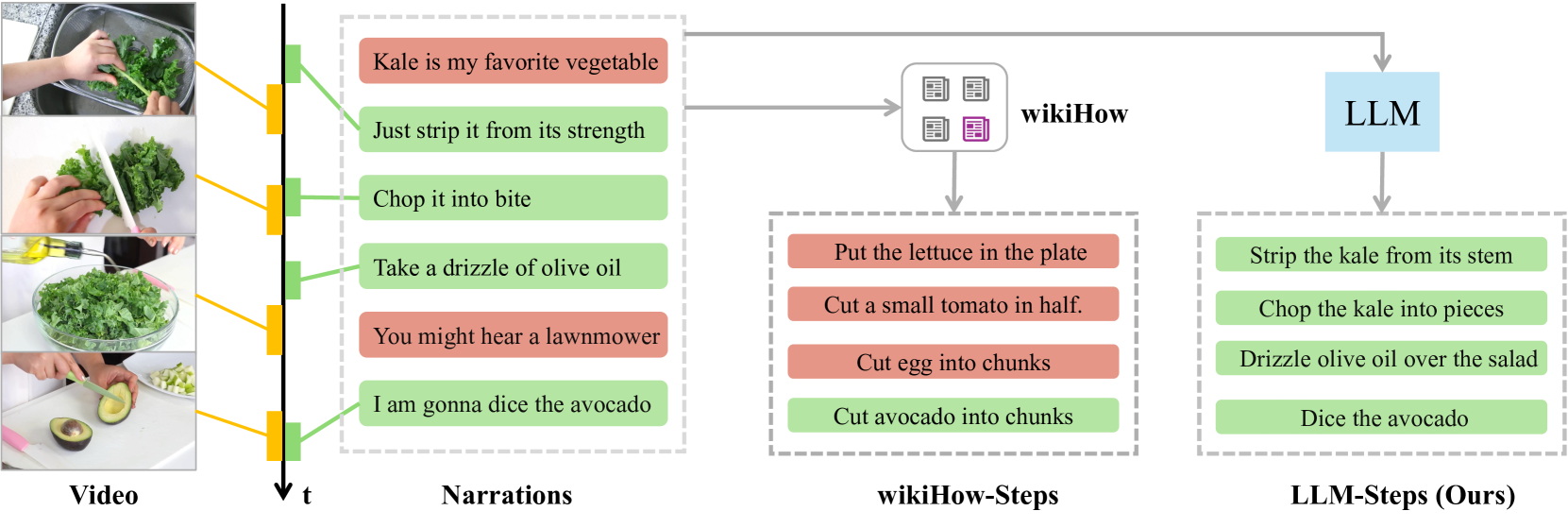
Learning to localize temporal boundaries of procedure steps in instructional videos is challenging due to the limited availability of annotated large-scale training videos. Recent works focus on learning the cross-modal alignment between video segments and ASR-transcripted narration texts through contrastive learning. However, these methods fail to account for the alignment noise, i.e., irrelevant narrations to the instructional task in videos and unreliable timestamps in narrations. To address these challenges, this work proposes a novel training framework. Motivated by the strong capabilities of Large Language Models (LLMs) in procedure understanding and text summarization, we first apply an LLM to filter out task-irrelevant information and summarize task-related procedure steps (LLM-steps) from narrations. To further generate reliable pseudo-matching between the LLM-steps and the video for training, we propose the Multi-Pathway Text-Video Alignment (MPTVA) strategy. The key idea is to measure alignment between LLM-steps and videos via multiple pathways, including: (1) step-narration-video alignment using narration timestamps, (2) direct step-to-video alignment based on their long-term semantic similarity, and (3) direct step-to-video alignment focusing on short-term fine-grained semantic similarity learned from general video domains. The results from different pathways are fused to generate reliable pseudo step-video matching. We conducted extensive experiments across various tasks and problem settings to evaluate our proposed method. Our approach surpasses state-of-the-art methods in three downstream tasks: procedure step grounding, step localization, and narration grounding by 5.9%, 3.1%, and 2.8%.
Read more9/25/2024