Learning Zero-Shot Material States Segmentation, by Implanting Natural Image Patterns in Synthetic Data

0
🌿
Sign in to get full access
Overview
- Visual understanding and segmentation of materials and their states is a fundamental task for understanding the physical world
- Collecting and annotating real-world data for this task is costly and labor-intensive
- Synthetic data is highly accurate but fails to capture the diversity of the real world
- This paper presents a method to bridge this gap by implanting patterns from real-world images into synthetic data
Plain English Explanation
Understanding the different materials and their states, such as wet, dry, stained, cooked, burned, etc., is essential for comprehending the physical world around us. However, the wide variety of textures, shapes, and often blurry boundaries formed by these materials make it challenging to develop
Manually collecting and annotating real-world images for this task is costly and time-consuming. On the other hand, synthetic computer-generated imagery (CGI) data is highly accurate and readily available, but it lacks the diversity and complexity of the real world. To address this issue, the researchers present a method to
The paper also introduces the first general benchmark for
The researchers show that neural networks trained on this dataset significantly outperform existing state-of-the-art methods on this task, demonstrating the value of their approach.
Technical Explanation
The paper presents a method to
To evaluate this approach, the authors introduce the first general benchmark for
The researchers show that neural networks trained on this dataset significantly outperform existing state-of-the-art methods on the material state segmentation task, demonstrating the effectiveness of their data generation approach.
Critical Analysis
The paper presents a compelling solution to the challenge of collecting and annotating real-world data for material state segmentation. By
However, the paper does not address the potential limitations of this approach. For example, the fidelity of the implanted patterns and their ability to capture the full complexity of real-world materials is not thoroughly evaluated. Additionally, the
Further research is needed to understand the broader applicability and potential biases of the generated data, as well as to explore other techniques for
Conclusion
This paper presents a novel approach to bridging the gap between real-world and synthetic data for material state segmentation, a fundamental task in understanding the physical world. By
The introduction of the
Overall, this work represents an important step towards developing robust and generalizable material understanding algorithms, with potential applications in fields ranging from computer vision to robotics and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🌿
0
Learning Zero-Shot Material States Segmentation, by Implanting Natural Image Patterns in Synthetic Data
Sagi Eppel, Jolina Li, Manuel Drehwald, Alan Aspuru-Guzik
Visual recognition of materials and their states is essential for understanding the physical world, from identifying wet regions on surfaces or stains on fabrics to detecting infected areas on plants or minerals in rocks. Collecting data that captures this vast variability is complex due to the scattered and gradual nature of material states. Manually annotating real-world images is constrained by cost and precision, while synthetic data, although accurate and inexpensive, lacks real-world diversity. This work aims to bridge this gap by infusing patterns automatically extracted from real-world images into synthetic data. Hence, patterns collected from natural images are used to generate and map materials into synthetic scenes. This unsupervised approach captures the complexity of the real world while maintaining the precision and scalability of synthetic data. We also present the first comprehensive benchmark for zero-shot material state segmentation, utilizing real-world images across a diverse range of domains, including food, soils, construction, plants, liquids, and more, each appears in various states such as wet, dry, infected, cooked, burned, and many others. The annotation includes partial similarity between regions with similar but not identical materials and hard segmentation of only identical material states. This benchmark eluded top foundation models, exposing the limitations of existing data collection methods. Meanwhile, nets trained on the infused data performed significantly better on this and related tasks. The dataset, code, and trained model are available. We also share 300,000 extracted textures and SVBRDF/PBR materials to facilitate future datasets generation.
Read more6/11/2024
🖼️
0
Synthetic dual image generation for reduction of labeling efforts in semantic segmentation of micrographs with a customized metric function
Matias Oscar Volman Stern, Dominic Hohs, Andreas Jansche, Timo Bernthaler, Gerhard Schneider
Training of semantic segmentation models for material analysis requires micrographs and their corresponding masks. It is quite unlikely that perfect masks will be drawn, especially at the edges of objects, and sometimes the amount of data that can be obtained is small, since only a few samples are available. These aspects make it very problematic to train a robust model. We demonstrate a workflow for the improvement of semantic segmentation models of micrographs through the generation of synthetic microstructural images in conjunction with masks. The workflow only requires joining a few micrographs with their respective masks to create the input for a Vector Quantised-Variational AutoEncoder model that includes an embedding space, which is trained such that a generative model (PixelCNN) learns the distribution of each input, transformed into discrete codes, and can be used to sample new codes. The latter will eventually be decoded by VQ-VAE to generate images alongside corresponding masks for semantic segmentation. To evaluate the synthetic data, we have trained U-Net models with different amounts of these synthetic data in conjunction with real data. These models were then evaluated using non-synthetic images only. Additionally, we introduce a customized metric derived from the mean Intersection over Union (mIoU). The proposed metric prevents a few falsely predicted pixels from greatly reducing the value of the mIoU. We have achieved a reduction in sample preparation and acquisition times, as well as the efforts, needed for image processing and labeling tasks, are less when it comes to training semantic segmentation model. The approach could be generalized to various types of image data such that it serves as a user-friendly solution for training models with a small number of real images.
Read more8/2/2024

0
MaterialSeg3D: Segmenting Dense Materials from 2D Priors for 3D Assets
Zeyu Li, Ruitong Gan, Chuanchen Luo, Yuxi Wang, Jiaheng Liu, Ziwei Zhu Man Zhang, Qing Li, Xucheng Yin, Zhaoxiang Zhang, Junran Peng
Driven by powerful image diffusion models, recent research has achieved the automatic creation of 3D objects from textual or visual guidance. By performing score distillation sampling (SDS) iteratively across different views, these methods succeed in lifting 2D generative prior to the 3D space. However, such a 2D generative image prior bakes the effect of illumination and shadow into the texture. As a result, material maps optimized by SDS inevitably involve spurious correlated components. The absence of precise material definition makes it infeasible to relight the generated assets reasonably in novel scenes, which limits their application in downstream scenarios. In contrast, humans can effortlessly circumvent this ambiguity by deducing the material of the object from its appearance and semantics. Motivated by this insight, we propose MaterialSeg3D, a 3D asset material generation framework to infer underlying material from the 2D semantic prior. Based on such a prior model, we devise a mechanism to parse material in 3D space. We maintain a UV stack, each map of which is unprojected from a specific viewpoint. After traversing all viewpoints, we fuse the stack through a weighted voting scheme and then employ region unification to ensure the coherence of the object parts. To fuel the learning of semantics prior, we collect a material dataset, named Materialized Individual Objects (MIO), which features abundant images, diverse categories, and accurate annotations. Extensive quantitative and qualitative experiments demonstrate the effectiveness of our method.
Read more5/17/2024
0
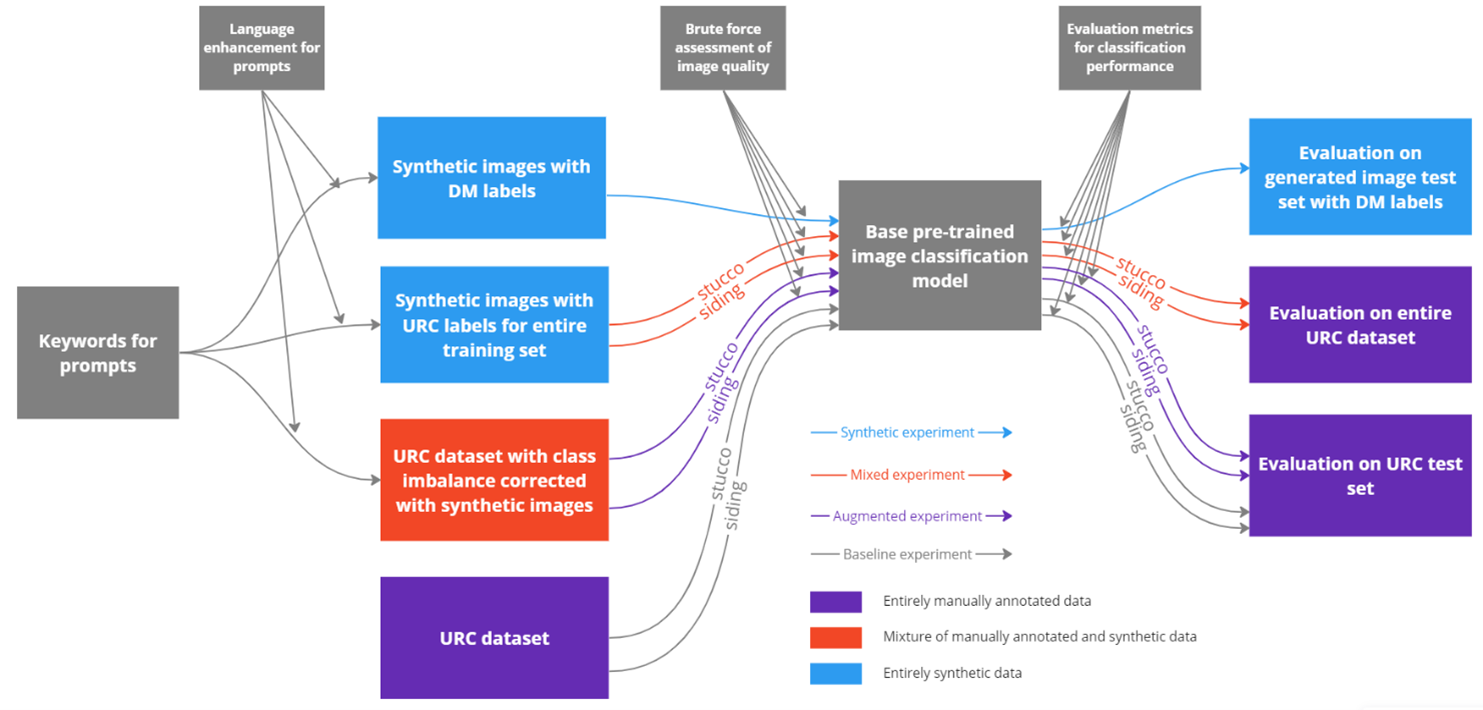
Scalability in Building Component Data Annotation: Enhancing Facade Material Classification with Synthetic Data
Josie Harrison, Alexander Hollberg, Yinan Yu
Computer vision models trained on Google Street View images can create material cadastres. However, current approaches need manually annotated datasets that are difficult to obtain and often have class imbalance. To address these challenges, this paper fine-tuned a Swin Transformer model on a synthetic dataset generated with DALL-E and compared the performance to a similar manually annotated dataset. Although manual annotation remains the gold standard, the synthetic dataset performance demonstrates a reasonable alternative. The findings will ease annotation needed to develop material cadastres, offering architects insights into opportunities for material reuse, thus contributing to the reduction of demolition waste.
Read more4/15/2024