Scalability in Building Component Data Annotation: Enhancing Facade Material Classification with Synthetic Data

0
Sign in to get full access
Overview
- The paper discusses how to efficiently annotate building façade data for material classification tasks using synthetic data.
- The authors propose a scalable approach to enhance façade material classification by leveraging synthetic data generation.
- The research aims to address the challenge of collecting and annotating large-scale real-world dataset for building façade analysis.
Plain English Explanation
The paper is about finding a more efficient way to label and categorize the materials used in the outer walls (façades) of buildings for machine learning models. Collecting and manually labeling lots of real-world photos of building façades is a time-consuming and expensive process. To address this, the researchers developed a method to generate synthetic, or computer-created, images of building façades that can be automatically labeled. This allows them to create a much larger dataset to train machine learning models for classifying the materials used in building façades. The goal is to make the process of building these AI models more scalable and efficient.
Technical Explanation
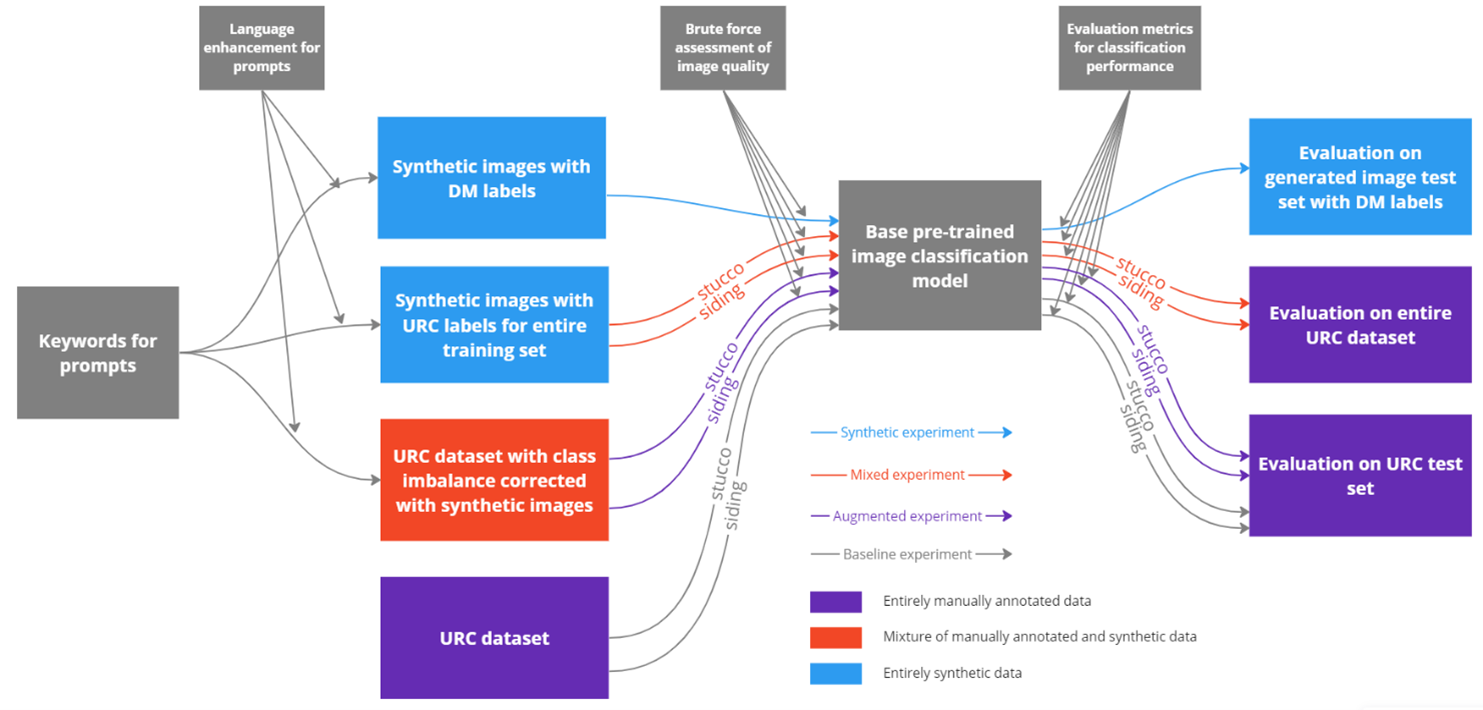
The paper presents a scalable approach to enhance façade material classification by leveraging synthetic data generation. The authors address the challenge of collecting and annotating large-scale real-world datasets for building façade analysis, which is time-consuming and expensive.
The key technical contributions include:
-
Synthetic Data Generation: The researchers developed a pipeline to generate high-quality synthetic façade images with annotated material labels. This allows them to create a much larger and more diverse training dataset compared to real-world photos.
-
Neural Network Architecture: The authors propose a novel neural network architecture that combines real and synthetic data for effective façade material classification. The architecture is designed to leverage the complementary strengths of both real and synthetic data.
-
Evaluation: The paper provides a thorough evaluation of the proposed approach on public datasets, demonstrating significant improvements in façade material classification performance compared to models trained on real data alone.
Critical Analysis
The paper addresses an important practical challenge in building AI systems for real-world applications like façade analysis. The authors' approach of leveraging synthetic data generation to supplement and scale up real-world datasets is a promising direction.
However, the paper does not discuss potential limitations or biases that may arise from the synthetic data generation process. It would be valuable to understand how the synthetic data compares to real-world data in terms of capturing the full diversity and nuance of real building façades. Additionally, the authors could have explored techniques for holistic inverse rendering of complex façades to improve the realism of the synthetic data.
Overall, the research presents a valuable contribution to the field of building façade analysis, but further investigation into the limitations and potential biases of the synthetic data approach would strengthen the work.
Conclusion
This paper proposes a scalable approach to enhance façade material classification by leveraging synthetic data generation. The authors address the challenge of collecting and annotating large-scale real-world datasets for building façade analysis, which is a common bottleneck in developing practical AI systems for this domain.
The key innovation is the use of a synthetic data generation pipeline to create a diverse and annotated training dataset, which is then combined with real-world data to train a novel neural network architecture. The results demonstrate significant improvements in façade material classification performance, highlighting the potential of this approach to make building analysis systems more scalable and efficient.
While the paper presents a promising solution, further research is needed to fully understand the limitations and potential biases introduced by the synthetic data generation process. Nonetheless, this work contributes valuable insights to the field of building façade analysis and the broader challenge of leveraging synthetic data to enhance real-world AI applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Scalability in Building Component Data Annotation: Enhancing Facade Material Classification with Synthetic Data
Josie Harrison, Alexander Hollberg, Yinan Yu
Computer vision models trained on Google Street View images can create material cadastres. However, current approaches need manually annotated datasets that are difficult to obtain and often have class imbalance. To address these challenges, this paper fine-tuned a Swin Transformer model on a synthetic dataset generated with DALL-E and compared the performance to a similar manually annotated dataset. Although manual annotation remains the gold standard, the synthetic dataset performance demonstrates a reasonable alternative. The findings will ease annotation needed to develop material cadastres, offering architects insights into opportunities for material reuse, thus contributing to the reduction of demolition waste.
Read more4/15/2024
📊
0
Massively Annotated Datasets for Assessment of Synthetic and Real Data in Face Recognition
Pedro C. Neto, Rafael M. Mamede, Carolina Albuquerque, Tiago Gonc{c}alves, Ana F. Sequeira
Face recognition applications have grown in parallel with the size of datasets, complexity of deep learning models and computational power. However, while deep learning models evolve to become more capable and computational power keeps increasing, the datasets available are being retracted and removed from public access. Privacy and ethical concerns are relevant topics within these domains. Through generative artificial intelligence, researchers have put efforts into the development of completely synthetic datasets that can be used to train face recognition systems. Nonetheless, the recent advances have not been sufficient to achieve performance comparable to the state-of-the-art models trained on real data. To study the drift between the performance of models trained on real and synthetic datasets, we leverage a massive attribute classifier (MAC) to create annotations for four datasets: two real and two synthetic. From these annotations, we conduct studies on the distribution of each attribute within all four datasets. Additionally, we further inspect the differences between real and synthetic datasets on the attribute set. When comparing through the Kullback-Leibler divergence we have found differences between real and synthetic samples. Interestingly enough, we have verified that while real samples suffice to explain the synthetic distribution, the opposite could not be further from being true.
Read more4/24/2024
0
Towards Reducing Data Acquisition and Labeling for Defect Detection using Simulated Data
Lukas Malte Kemeter, Rasmus Hvingelby, Paulina Sierak, Tobias Schon, Bishwajit Gosswam
In many manufacturing settings, annotating data for machine learning and computer vision is costly, but synthetic data can be generated at significantly lower cost. Substituting the real-world data with synthetic data is therefore appealing for many machine learning applications that require large amounts of training data. However, relying solely on synthetic data is frequently inadequate for effectively training models that perform well on real-world data, primarily due to domain shifts between the synthetic and real-world data. We discuss approaches for dealing with such a domain shift when detecting defects in X-ray scans of aluminium wheels. Using both simulated and real-world X-ray images, we train an object detection model with different strategies to identify the training approach that generates the best detection results while minimising the demand for annotated real-world training samples. Our preliminary findings suggest that the sim-2-real domain adaptation approach is more cost-efficient than a fully supervised oracle - if the total number of available annotated samples is fixed. Given a certain number of labeled real-world samples, training on a mix of synthetic and unlabeled real-world data achieved comparable or even better detection results at significantly lower cost. We argue that future research into the cost-efficiency of different training strategies is important for a better understanding of how to allocate budget in applied machine learning projects.
Read more6/28/2024
📊
0
Automated Real-World Sustainability Data Generation from Images of Buildings
Peter J Bentley, Soo Ling Lim, Rajat Mathur, Sid Narang
When data on building features is unavailable, the task of determining how to improve that building in terms of carbon emissions becomes infeasible. We show that from only a set of images, a Large Language Model with appropriate prompt engineering and domain knowledge can successfully estimate a range of building features relevant for sustainability calculations. We compare our novel image-to-data method with a ground truth comprising real building data for 47 apartments and achieve accuracy better than a human performing the same task. We also demonstrate that the method can generate tailored recommendations to the owner on how best to improve their properties and discuss methods to scale the approach.
Read more8/29/2024