Infini-gram: Scaling Unbounded n-gram Language Models to a Trillion Tokens

2

Sign in to get full access
Overview
- This paper introduces "Infini-gram," a method for scaling n-gram language models to handle an unbounded n and train on a trillion tokens.
- The key idea is to use a novel data structure and caching scheme to efficiently store and retrieve n-gram counts, enabling the model to capture long-range dependencies without running into memory constraints.
- The authors demonstrate the effectiveness of Infini-gram on several benchmarks, showing it can outperform transformer-based models on tasks that require modeling long-context.
Plain English Explanation
The paper presents a new language modeling technique called "Infini-gram" that can handle n-grams (sequences of n words) of unlimited length. Traditional n-gram models are limited by the amount of memory required to store all possible n-gram combinations, especially as n gets larger.
Infini-gram: Scaling Unbounded 𝑛-gram Language Models to a Trillion Tokens solves this problem by using a clever data structure and caching scheme to efficiently store and retrieve n-gram counts, no matter how long the n-gram. This allows the model to capture long-range dependencies in language that are important for tasks like story generation or document summarization, without running into memory constraints.
The authors show that Infini-gram can outperform large transformer-based language models on benchmarks that require modeling long-context. This is an important advance, as recent research has shown that large language models can struggle with long-context learning.
Technical Explanation
The core innovation of Infini-gram is a new data structure called the "Infini-gram trie" that can compactly store n-gram counts for arbitrary n. Traditional n-gram models maintain separate dictionaries for each n, which becomes intractable as n grows.
The Infini-gram trie uses a hierarchical structure to efficiently encode longer n-grams by reusing information from shorter ones. This allows the model to scale to extremely large n without running out of memory. The authors also introduce a caching scheme to further optimize retrieval of n-gram counts.
Experimentally, the authors show that Infini-gram can be trained on over a trillion tokens, outperforming transformer-based models like GPT-3 on long-range language modeling tasks. This aligns with recent research demonstrating the benefits of scaling language models to massive sizes.
Critical Analysis
The Infini-gram approach represents a clever solution to the memory limitations of traditional n-gram models. By developing a more efficient data structure and caching scheme, the authors have significantly expanded the practical reach of n-gram techniques.
However, one potential limitation is that the Infini-gram trie may become unwieldy for extremely large vocabularies, as each n-gram must be stored as a path through the trie. The authors do not discuss the scaling behavior of their approach as the vocabulary size increases.
Additionally, while Infini-gram outperforms transformer models on long-range tasks, it is unclear how it would perform on more general language modeling benchmarks. Recent research has shown that scaled-up generative language models can develop novel emergent abilities, which may not be captured by the n-gram approach.
Overall, the Infini-gram technique represents an important advance in language modeling, particularly for applications that require long-range context. But further research is needed to fully understand its strengths and weaknesses compared to other modeling paradigms, especially as language models continue to grow in scale and capability.
Conclusion
The Infini-gram paper introduces a novel n-gram language modeling approach that can handle unbounded context lengths by using a clever data structure and caching scheme. This allows the model to outperform large transformer-based models on tasks that require long-range dependencies, addressing a key limitation of current state-of-the-art language models.
While Infini-gram represents an important advance, there are still open questions about its scalability and generalization capabilities compared to other modeling techniques. As the field of language modeling continues to rapidly evolve, with models reaching unprecedented scales and demonstrating new emergent abilities, further research will be needed to fully understand the role and potential of Infini-gram within the broader landscape of language modeling.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
2
Infini-gram: Scaling Unbounded n-gram Language Models to a Trillion Tokens
Jiacheng Liu, Sewon Min, Luke Zettlemoyer, Yejin Choi, Hannaneh Hajishirzi
Are $n$-gram language models still relevant in this era of neural large language models (LLMs)? Our answer is yes, and we showcase their values in both text analysis and improving neural LLMs. This was done by modernizing $n$-gram LMs in two aspects. First, we train them at the same data scale as neural LLMs -- 5 trillion tokens. This is the largest $n$-gram LM ever built. Second, existing $n$-gram LMs use small $n$ which hinders their performance; we instead allow $n$ to be arbitrarily large, by introducing a new $infty$-gram LM with backoff. Instead of pre-computing $n$-gram count tables (which would be very expensive), we develop an engine named infini-gram -- powered by suffix arrays -- that can compute $infty$-gram (as well as $n$-gram with arbitrary $n$) probabilities with millisecond-level latency. The $infty$-gram framework and infini-gram engine enable us to conduct many novel and interesting analyses of human-written and machine-generated text: we find that the $infty$-gram LM has fairly high accuracy for next-token prediction (47%), and can complement neural LLMs to greatly reduce their perplexity. When analyzing machine-generated text, we also observe irregularities in the machine--$infty$-gram agreement level with respect to the suffix length, which indicates deficiencies in neural LLM pretraining and the positional embeddings of Transformers.
Read more4/5/2024
💬
0
Transformers Can Represent $n$-gram Language Models
Anej Svete, Ryan Cotterell
Existing work has analyzed the representational capacity of the transformer architecture by means of formal models of computation. However, the focus so far has been on analyzing the architecture in terms of language emph{acceptance}. We contend that this is an ill-suited problem in the study of emph{language models} (LMs), which are definitionally emph{probability distributions} over strings. In this paper, we focus on the relationship between transformer LMs and $n$-gram LMs, a simple and historically relevant class of language models. We show that transformer LMs using the hard or sparse attention mechanisms can exactly represent any $n$-gram LM, giving us a concrete lower bound on their probabilistic representational capacity. This provides a first step towards understanding the mechanisms that transformer LMs can use to represent probability distributions over strings.
Read more6/21/2024
27
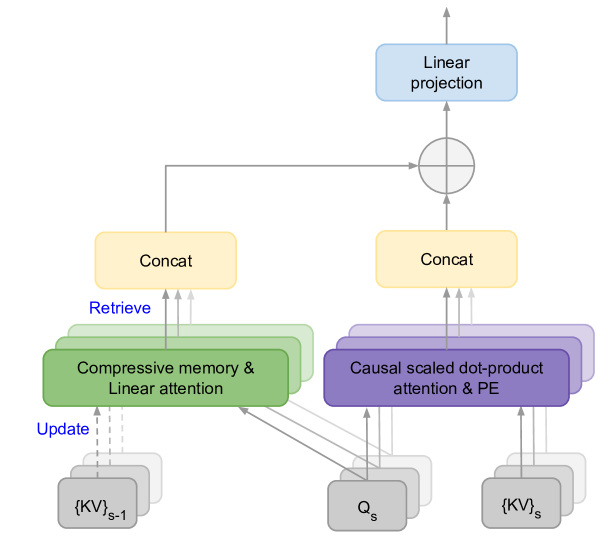
Leave No Context Behind: Efficient Infinite Context Transformers with Infini-attention
Tsendsuren Munkhdalai, Manaal Faruqui, Siddharth Gopal
This work introduces an efficient method to scale Transformer-based Large Language Models (LLMs) to infinitely long inputs with bounded memory and computation. A key component in our proposed approach is a new attention technique dubbed Infini-attention. The Infini-attention incorporates a compressive memory into the vanilla attention mechanism and builds in both masked local attention and long-term linear attention mechanisms in a single Transformer block. We demonstrate the effectiveness of our approach on long-context language modeling benchmarks, 1M sequence length passkey context block retrieval and 500K length book summarization tasks with 1B and 8B LLMs. Our approach introduces minimal bounded memory parameters and enables fast streaming inference for LLMs.
Read more8/13/2024

0
Understanding Transformers via N-gram Statistics
Timothy Nguyen
Transformer based large-language models (LLMs) display extreme proficiency with language yet a precise understanding of how they work remains elusive. One way of demystifying transformer predictions would be to describe how they depend on their context in terms of simple template functions. This paper takes a first step in this direction by considering families of functions (i.e. rules) formed out of simple N-gram based statistics of the training data. By studying how well these rulesets approximate transformer predictions, we obtain a variety of novel discoveries: a simple method to detect overfitting during training without using a holdout set, a quantitative measure of how transformers progress from learning simple to more complex statistical rules over the course of training, a model-variance criterion governing when transformer predictions tend to be described by N-gram rules, and insights into how well transformers can be approximated by N-gram rulesets in the limit where these rulesets become increasingly complex. In this latter direction, we find that for 78% of LLM next-token distributions on TinyStories, their top-1 predictions agree with those provided by our N-gram rulesets.
Read more7/18/2024