Detecting Misinformation in Multimedia Content through Cross-Modal Entity Consistency: A Dual Learning Approach

0
👀
Sign in to get full access
Overview
- The rise of social media has led to the spread of misinformation in multimodal formats, beyond just text.
- Previous research has focused on single modalities or text-image combinations, leaving a gap in detecting misinformation across multiple modalities.
- Simplifying entity consistency to a scalar value overlooks the complexities of high-dimensional representations across modalities.
- To address these limitations, the paper proposes a Multimedia Misinformation Detection (MultiMD) framework to detect misinformation in video content by leveraging cross-modal entity consistency.
Plain English Explanation
The way people share information on social media has changed a lot, going beyond just text to include things like images, videos, and audio. This makes it harder to detect when information is false or misleading. Previous research has mainly looked at misinformation in single formats or just text and images, but hasn't really addressed the complexities of detecting misinformation across multiple formats.
The key idea in this paper is to use "entity consistency" to help detect misinformation in videos. Entity consistency refers to how well the different parts of a piece of content, like the visuals and the text, match up and make sense together. The researchers found that simply reducing this to a single number doesn't capture the full complexity, so they developed a new framework called MultiMD that looks at entity consistency in a more nuanced way across different formats.
Their results show that this MultiMD approach is better at catching misinformation in videos compared to other methods. This work provides important new insights into how to tackle the growing challenge of detecting misinformation, especially as it becomes more sophisticated and spans multiple formats.
Technical Explanation
The proposed Multimedia Misinformation Detection (MultiMD) framework leverages cross-modal entity consistency to detect misinformation in video content.
Unlike prior work that has focused on single modalities or text-image combinations, MultiMD addresses the challenge of detecting misinformation across multiple modalities. The researchers found that simplifying entity consistency to a scalar value overlooks the inherent complexities of high-dimensional representations across different modalities.
MultiMD's dual learning approach allows for enhancing misinformation detection performance while also improving representation learning of entity consistency across modalities. The results demonstrate that MultiMD outperforms state-of-the-art baseline models, underscoring the importance of each modality in effective misinformation detection.
Critical Analysis
The paper acknowledges that the proposed MultiMD framework has limitations in its ability to fully capture the nuances of cross-modal entity consistency. While the dual learning approach shows promise, the researchers note that further research is needed to explore more sophisticated representations and techniques for modeling the complex relationships between different modalities.
Additionally, the evaluation is conducted on a specific dataset, and the generalizability of the approach to other types of misinformation or social media platforms may require further investigation. The paper also does not discuss potential biases or ethical considerations that may arise from deploying such a system in the real world.
Overall, the research provides valuable methodological and technical insights into multimodal misinformation detection, but there are opportunities for further refinement and exploration of the challenges inherent in this domain.
Conclusion
This paper introduces a novel Multimedia Misinformation Detection (MultiMD) framework that leverages cross-modal entity consistency to improve the detection of misinformation in video content. By addressing the limitations of previous approaches that focused on single modalities or text-image combinations, the researchers have made an important contribution to the field of multimodal misinformation detection.
The results demonstrate the effectiveness of the MultiMD approach, underscoring the significance of incorporating diverse modalities for more robust and accurate misinformation detection. This work provides a foundation for further research and development in this critical area, as the spread of misinformation across social media continues to pose significant challenges for individuals, organizations, and society as a whole.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
👀
0
Detecting Misinformation in Multimedia Content through Cross-Modal Entity Consistency: A Dual Learning Approach
Zhe Fu, Kanlun Wang, Wangjiaxuan Xin, Lina Zhou, Shi Chen, Yaorong Ge, Daniel Janies, Dongsong Zhang
The landscape of social media content has evolved significantly, extending from text to multimodal formats. This evolution presents a significant challenge in combating misinformation. Previous research has primarily focused on single modalities or text-image combinations, leaving a gap in detecting multimodal misinformation. While the concept of entity consistency holds promise in detecting multimodal misinformation, simplifying the representation to a scalar value overlooks the inherent complexities of high-dimensional representations across different modalities. To address these limitations, we propose a Multimedia Misinformation Detection (MultiMD) framework for detecting misinformation from video content by leveraging cross-modal entity consistency. The proposed dual learning approach allows for not only enhancing misinformation detection performance but also improving representation learning of entity consistency across different modalities. Our results demonstrate that MultiMD outperforms state-of-the-art baseline models and underscore the importance of each modality in misinformation detection. Our research provides novel methodological and technical insights into multimodal misinformation detection.
Read more9/4/2024
🔎
0
New!Interpretable Multimodal Misinformation Detection with Logic Reasoning
Hui Liu, Wenya Wang, Haoliang Li
Multimodal misinformation on online social platforms is becoming a critical concern due to increasing credibility and easier dissemination brought by multimedia content, compared to traditional text-only information. While existing multimodal detection approaches have achieved high performance, the lack of interpretability hinders these systems' reliability and practical deployment. Inspired by NeuralSymbolic AI which combines the learning ability of neural networks with the explainability of symbolic learning, we propose a novel logic-based neural model for multimodal misinformation detection which integrates interpretable logic clauses to express the reasoning process of the target task. To make learning effective, we parameterize symbolic logical elements using neural representations, which facilitate the automatic generation and evaluation of meaningful logic clauses. Additionally, to make our framework generalizable across diverse misinformation sources, we introduce five meta-predicates that can be instantiated with different correlations. Results on three public datasets (Twitter, Weibo, and Sarcasm) demonstrate the feasibility and versatility of our model.
Read more9/17/2024
🔎
0
Interpretable Detection of Out-of-Context Misinformation with Neural-Symbolic-Enhanced Large Multimodal Model
Yizhou Zhang, Loc Trinh, Defu Cao, Zijun Cui, Yan Liu
Recent years have witnessed the sustained evolution of misinformation that aims at manipulating public opinions. Unlike traditional rumors or fake news editors who mainly rely on generated and/or counterfeited images, text and videos, current misinformation creators now more tend to use out-of-context multimedia contents (e.g. mismatched images and captions) to deceive the public and fake news detection systems. This new type of misinformation increases the difficulty of not only detection but also clarification, because every individual modality is close enough to true information. To address this challenge, in this paper we explore how to achieve interpretable cross-modal de-contextualization detection that simultaneously identifies the mismatched pairs and the cross-modal contradictions, which is helpful for fact-check websites to document clarifications. The proposed model first symbolically disassembles the text-modality information to a set of fact queries based on the Abstract Meaning Representation of the caption and then forwards the query-image pairs into a pre-trained large vision-language model select the ``evidences that are helpful for us to detect misinformation. Extensive experiments indicate that the proposed methodology can provide us with much more interpretable predictions while maintaining the accuracy same as the state-of-the-art model on this task.
Read more4/9/2024
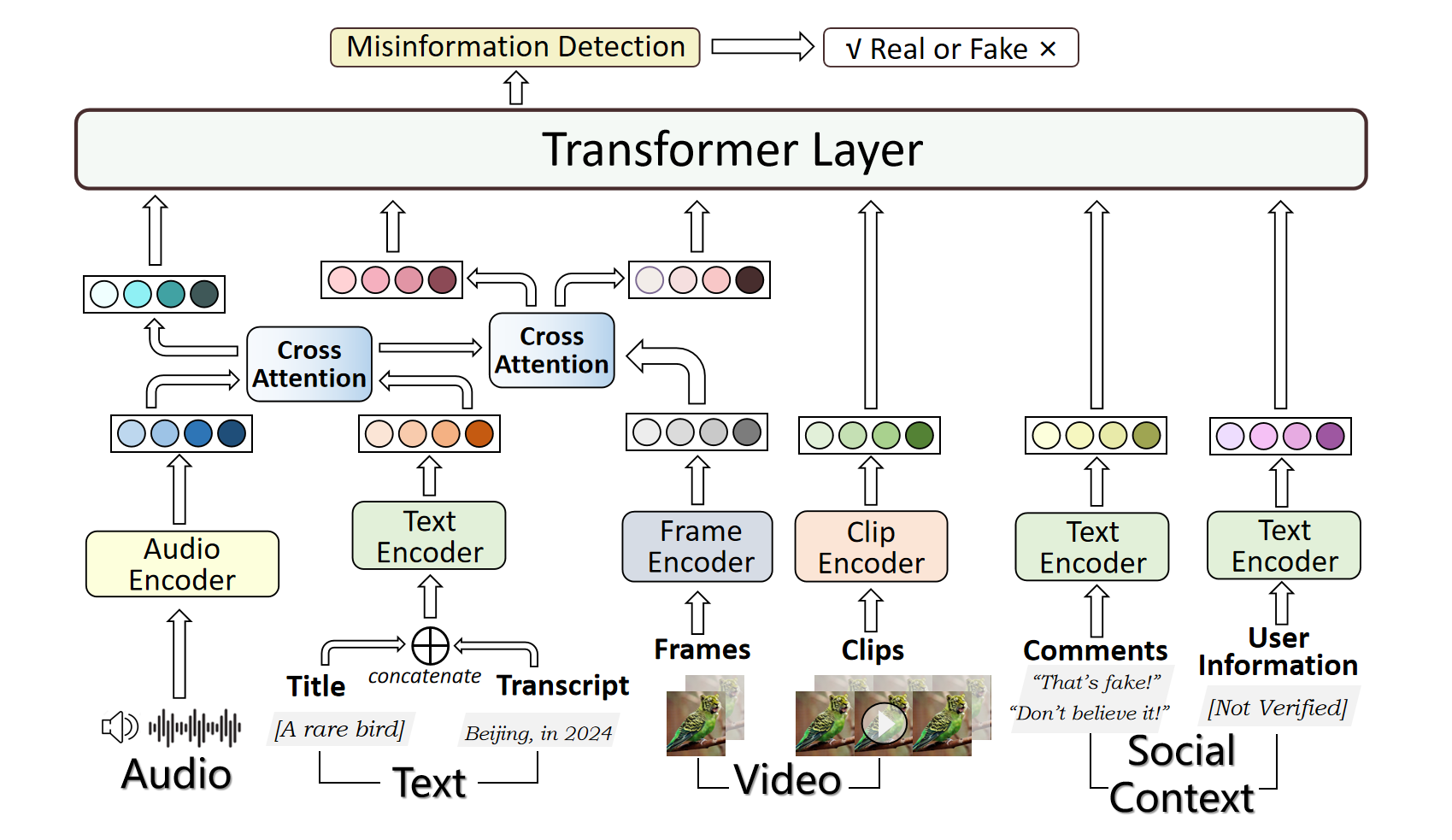
0
Exploring the Role of Audio in Multimodal Misinformation Detection
Moyang Liu, Yukun Liu, Ruibo Fu, Zhengqi Wen, Jianhua Tao, Xuefei Liu, Guanjun Li
With the rapid development of deepfake technology, especially the deep audio fake technology, misinformation detection on the social media scene meets a great challenge. Social media data often contains multimodal information which includes audio, video, text, and images. However, existing multimodal misinformation detection methods tend to focus only on some of these modalities, failing to comprehensively address information from all modalities. To comprehensively address the various modal information that may appear on social media, this paper constructs a comprehensive multimodal misinformation detection framework. By employing corresponding neural network encoders for each modality, the framework can fuse different modality information and support the multimodal misinformation detection task. Based on the constructed framework, this paper explores the importance of the audio modality in multimodal misinformation detection tasks on social media. By adjusting the architecture of the acoustic encoder, the effectiveness of different acoustic feature encoders in the multimodal misinformation detection tasks is investigated. Furthermore, this paper discovers that audio and video information must be carefully aligned, otherwise the misalignment across different audio and video modalities can severely impair the model performance.
Read more8/23/2024