Leveraging the Interplay Between Syntactic and Acoustic Cues for Optimizing Korean TTS Pause Formation
2404.02592
0
0
🎲
Abstract
Contemporary neural speech synthesis models have indeed demonstrated remarkable proficiency in synthetic speech generation as they have attained a level of quality comparable to that of human-produced speech. Nevertheless, it is important to note that these achievements have predominantly been verified within the context of high-resource languages such as English. Furthermore, the Tacotron and FastSpeech variants show substantial pausing errors when applied to the Korean language, which affects speech perception and naturalness. In order to address the aforementioned issues, we propose a novel framework that incorporates comprehensive modeling of both syntactic and acoustic cues that are associated with pausing patterns. Remarkably, our framework possesses the capability to consistently generate natural speech even for considerably more extended and intricate out-of-domain (OOD) sentences, despite its training on short audio clips. Architectural design choices are validated through comparisons with baseline models and ablation studies using subjective and objective metrics, thus confirming model performance.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- Contemporary neural speech synthesis models have achieved high-quality synthetic speech, comparable to human speech
- However, these models have mainly been tested on high-resource languages like English
- When applied to Korean, the models show substantial pausing errors, affecting speech perception and naturalness
Plain English Explanation
Imagine you're trying to create a machine that can speak like a human. The latest speech synthesis models have become incredibly good at this task, to the point where the computer-generated speech is hard to distinguish from the real thing. This is a remarkable achievement in the field of artificial intelligence and language technology.
However, the researchers found that these models work best with languages that have a lot of available data, like English. When they tried using these models to generate speech in Korean, the results weren't as good. The computer-generated Korean speech had issues with pausing - it would pause in the wrong places, which made the speech sound unnatural and hard to understand.
To address this problem, the researchers developed a new framework that takes into account both the grammatical structure of the language and the acoustic cues that indicate where pauses should be. This allows the model to generate more natural-sounding speech, even for longer and more complex sentences that are outside the scope of the training data.
Technical Explanation
The paper proposes a novel framework for neural speech synthesis that aims to address the pausing errors observed in previous models when applied to the Korean language. The key innovation is the incorporation of comprehensive modeling of both syntactic and acoustic cues associated with pausing patterns.
The researchers validated their architectural design choices through comparisons with baseline models and ablation studies, using both subjective and objective evaluation metrics. Notably, their framework demonstrated the capability to consistently generate natural speech for considerably more extended and intricate out-of-domain (OOD) sentences, despite only being trained on short audio clips.
Critical Analysis
The paper acknowledges the limitations of existing neural speech synthesis models, which have primarily been tested and optimized for high-resource languages like English. The researchers' decision to focus on the Korean language, which poses additional challenges due to its unique linguistic properties, is a commendable effort to broaden the applicability of these models.
While the proposed framework shows promising results in addressing pausing errors, it would be valuable to see how it performs on a wider range of languages, particularly those with diverse prosodic and grammatical structures. Additionally, the paper does not provide detailed analysis of the specific acoustic and syntactic features that were most influential in improving the naturalness of the generated speech.
Further research could explore the generalizability of the proposed approach, as well as investigate the potential trade-offs between the increased model complexity and the benefits in terms of speech quality and naturalness.
Conclusion
This research paper presents a significant advancement in the field of neural speech synthesis by addressing the limitations of existing models when applied to languages beyond English. The proposed framework, which integrates comprehensive modeling of both syntactic and acoustic cues, demonstrates the ability to generate more natural-sounding speech, even for complex and out-of-domain sentences.
The findings of this study have important implications for the development of speech technology that can effectively serve a diverse range of linguistic communities. As the field of artificial intelligence continues to evolve, research like this will play a crucial role in ensuring that the benefits of these advancements are accessible and inclusive.
Related Papers
Think before you speak: Training Language Models With Pause Tokens
Sachin Goyal, Ziwei Ji, Ankit Singh Rawat, Aditya Krishna Menon, Sanjiv Kumar, Vaishnavh Nagarajan
0
0
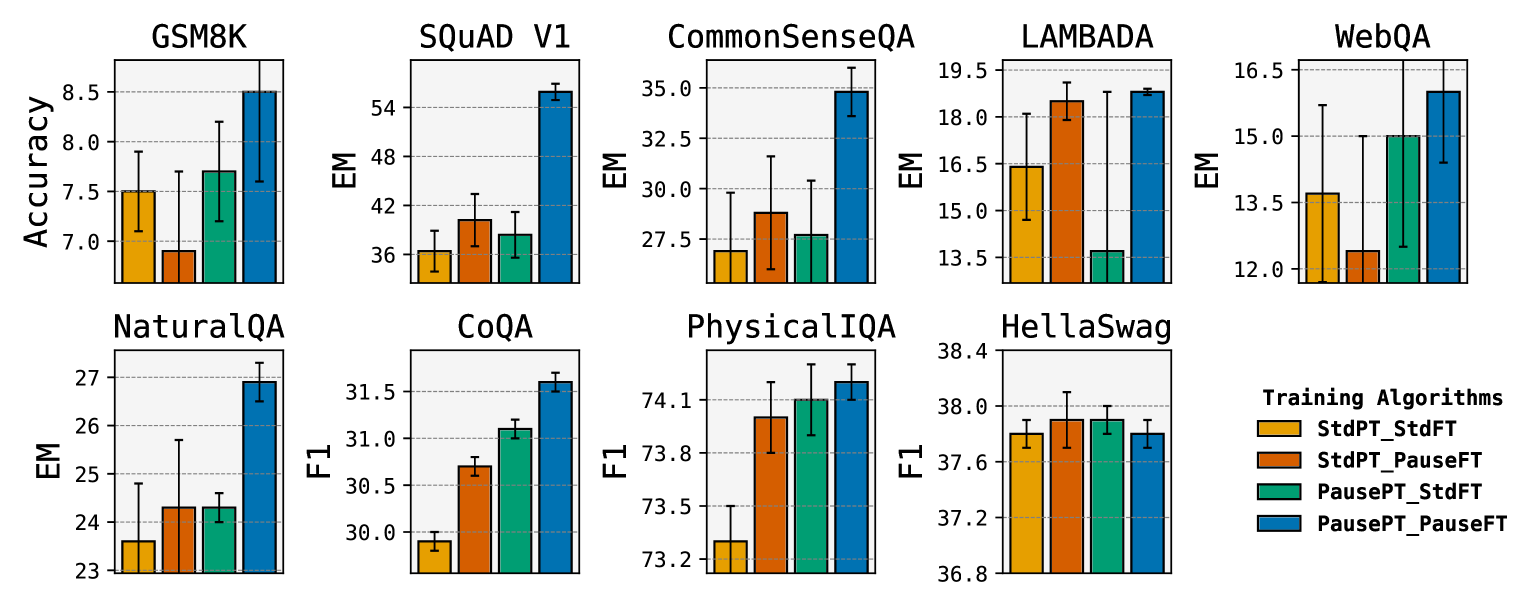
Language models generate responses by producing a series of tokens in immediate succession: the $(K+1)^{th}$ token is an outcome of manipulating $K$ hidden vectors per layer, one vector per preceding token. What if instead we were to let the model manipulate say, $K+10$ hidden vectors, before it outputs the $(K+1)^{th}$ token? We operationalize this idea by performing training and inference on language models with a (learnable) $textit{pause}$ token, a sequence of which is appended to the input prefix. We then delay extracting the model's outputs until the last pause token is seen, thereby allowing the model to process extra computation before committing to an answer. We empirically evaluate $textit{pause-training}$ on decoder-only models of 1B and 130M parameters with causal pretraining on C4, and on downstream tasks covering reasoning, question-answering, general understanding and fact recall. Our main finding is that inference-time delays show gains when the model is both pre-trained and finetuned with delays. For the 1B model, we witness gains on 8 of 9 tasks, most prominently, a gain of $18%$ EM score on the QA task of SQuAD, $8%$ on CommonSenseQA and $1%$ accuracy on the reasoning task of GSM8k. Our work raises a range of conceptual and practical future research questions on making delayed next-token prediction a widely applicable new paradigm.
4/23/2024

Improving Language Model-Based Zero-Shot Text-to-Speech Synthesis with Multi-Scale Acoustic Prompts
Shun Lei, Yixuan Zhou, Liyang Chen, Dan Luo, Zhiyong Wu, Xixin Wu, Shiyin Kang, Tao Jiang, Yahui Zhou, Yuxing Han, Helen Meng
0
0
Zero-shot text-to-speech (TTS) synthesis aims to clone any unseen speaker's voice without adaptation parameters. By quantizing speech waveform into discrete acoustic tokens and modeling these tokens with the language model, recent language model-based TTS models show zero-shot speaker adaptation capabilities with only a 3-second acoustic prompt of an unseen speaker. However, they are limited by the length of the acoustic prompt, which makes it difficult to clone personal speaking style. In this paper, we propose a novel zero-shot TTS model with the multi-scale acoustic prompts based on a neural codec language model VALL-E. A speaker-aware text encoder is proposed to learn the personal speaking style at the phoneme-level from the style prompt consisting of multiple sentences. Following that, a VALL-E based acoustic decoder is utilized to model the timbre from the timbre prompt at the frame-level and generate speech. The experimental results show that our proposed method outperforms baselines in terms of naturalness and speaker similarity, and can achieve better performance by scaling out to a longer style prompt.
4/10/2024
Prior-agnostic Multi-scale Contrastive Text-Audio Pre-training for Parallelized TTS Frontend Modeling
Quanxiu Wang, Hui Huang, Mingjie Wang, Yong Dai, Jinzuomu Zhong, Benlai Tang
0
0
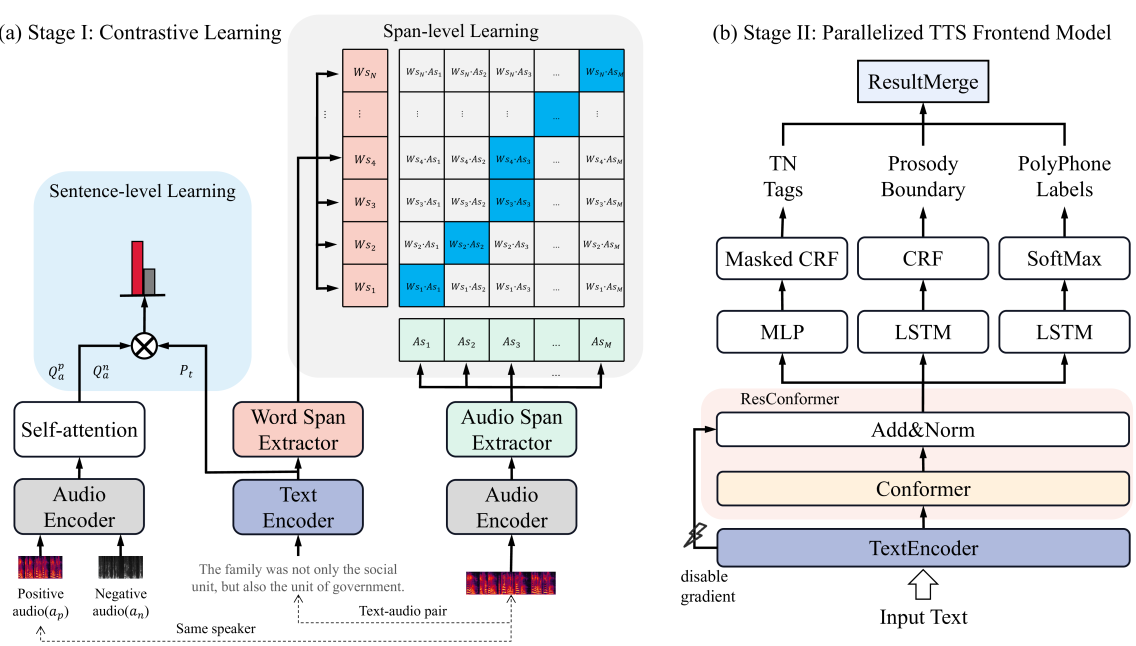
Over the past decade, a series of unflagging efforts have been dedicated to developing highly expressive and controllable text-to-speech (TTS) systems. In general, the holistic TTS comprises two interconnected components: the frontend module and the backend module. The frontend excels in capturing linguistic representations from the raw text input, while the backend module converts linguistic cues to speech. The research community has shown growing interest in the study of the frontend component, recognizing its pivotal role in text-to-speech systems, including Text Normalization (TN), Prosody Boundary Prediction (PBP), and Polyphone Disambiguation (PD). Nonetheless, the limitations posed by insufficient annotated textual data and the reliance on homogeneous text signals significantly undermine the effectiveness of its supervised learning. To evade this obstacle, a novel two-stage TTS frontend prediction pipeline, named TAP-FM, is proposed in this paper. Specifically, during the first learning phase, we present a Multi-scale Contrastive Text-audio Pre-training protocol (MC-TAP), which hammers at acquiring richer insights via multi-granularity contrastive pre-training in an unsupervised manner. Instead of mining homogeneous features in prior pre-training approaches, our framework demonstrates the ability to delve deep into both global and local text-audio semantic and acoustic representations. Furthermore, a parallelized TTS frontend model is delicately devised to execute TN, PD, and PBP prediction tasks, respectively in the second stage. Finally, extensive experiments illustrate the superiority of our proposed method, achieving state-of-the-art performance.
4/16/2024
💬
EE-TTS: Emphatic Expressive TTS with Linguistic Information
Yi Zhong, Chen Zhang, Xule Liu, Chenxi Sun, Weishan Deng, Haifeng Hu, Zhongqian Sun
0
0
While Current TTS systems perform well in synthesizing high-quality speech, producing highly expressive speech remains a challenge. Emphasis, as a critical factor in determining the expressiveness of speech, has attracted more attention nowadays. Previous works usually enhance the emphasis by adding intermediate features, but they can not guarantee the overall expressiveness of the speech. To resolve this matter, we propose Emphatic Expressive TTS (EE-TTS), which leverages multi-level linguistic information from syntax and semantics. EE-TTS contains an emphasis predictor that can identify appropriate emphasis positions from text and a conditioned acoustic model to synthesize expressive speech with emphasis and linguistic information. Experimental results indicate that EE-TTS outperforms baseline with MOS improvements of 0.49 and 0.67 in expressiveness and naturalness. EE-TTS also shows strong generalization across different datasets according to AB test results.
4/16/2024