Leveraging Large Language Models to Enhance Domain Expert Inclusion in Data Science Workflows

0
Sign in to get full access
Overview
- Leverages large language models to enhance domain expert inclusion in data science workflows
- Focuses on improving collaboration between domain experts and data scientists
- Explores how language models can facilitate knowledge transfer and task delegation
Plain English Explanation
This research paper explores how large language models can be used to enhance the inclusion of domain experts in data science workflows. The key idea is to leverage the capabilities of these powerful language models to facilitate better collaboration between domain experts, who have deep knowledge of the problem domain, and data scientists, who have strong technical skills in data analysis and model building.
One of the main challenges in data science projects is the knowledge gap between these two groups. Domain experts often struggle to communicate their domain-specific insights to data scientists, while data scientists may have difficulty translating their technical findings into actionable insights for the domain experts. This paper introduces techniques to bridge this gap, such as using language models to capture and convey domain knowledge more effectively.
The researchers also demonstrate how language models can be used to delegate specific tasks to domain experts, allowing them to contribute their expertise more directly to the data science workflow. This could involve, for example, having domain experts annotate data subsets or provide feedback on model outputs in natural language.
Overall, this research aims to make data science more inclusive and collaborative, empowering domain experts to play a more active role in the process and ensuring that their valuable knowledge is better integrated into the final outcomes.
Technical Explanation
The paper presents a framework for leveraging large language models to enhance the involvement of domain experts in data science workflows. The authors argue that while data science has become increasingly important in many domains, the collaboration between domain experts and data scientists remains a significant challenge.
To address this, the researchers propose several language model-based techniques. First, they explore how language models can be used to capture and transfer domain knowledge more effectively, facilitating better communication between the two groups. This could involve using language models to extract and summarize domain-specific insights from expert-generated text, or to generate natural language explanations of technical findings.
The paper also investigates how language models can be used to delegate specific tasks to domain experts, such as annotating data subsets or providing feedback on model outputs. By making it easier for domain experts to contribute their expertise directly to the data science workflow, the researchers aim to increase their engagement and ensure that their knowledge is better integrated into the final outcomes.
The authors evaluate their approach through a series of experiments, demonstrating the effectiveness of language model-based techniques in enhancing collaboration and knowledge transfer between domain experts and data scientists. They also discuss the limitations of their approach and potential areas for future research.
Critical Analysis
The research presented in this paper offers a promising approach to addressing the longstanding challenge of integrating domain expertise into data science workflows. By leveraging the capabilities of large language models, the proposed techniques have the potential to significantly improve collaboration and knowledge transfer between domain experts and data scientists.
One of the key strengths of this work is its focus on practical, real-world applications. The researchers have identified a crucial pain point in data science projects and have developed concrete, language model-based solutions to address it. The experimental evaluations provide evidence of the effectiveness of these techniques, which is encouraging for their potential adoption in industry and academic settings.
However, the paper also acknowledges several limitations and areas for further research. For example, the authors note that the performance of language model-based techniques may be heavily dependent on the quality and quantity of the training data, and that more work is needed to understand the generalizability of their approach across different domains and problem contexts.
Additionally, the paper does not deeply explore the potential ethical and social implications of this technology. As language models become more powerful and widely adopted, there are valid concerns about their potential misuse, data biases, and the risk of further entrenching existing power structures. Future research in this area would benefit from a more robust consideration of these issues.
Overall, this paper represents an important step forward in enhancing the integration of domain expertise into data science workflows. By continuing to build on these ideas and addressing the remaining challenges, the research community can work towards creating more inclusive, collaborative, and impactful data science practices.
Conclusion
This research paper proposes a novel approach to leveraging large language models to enhance the inclusion of domain experts in data science workflows. By facilitating better knowledge transfer and task delegation between domain experts and data scientists, the techniques outlined in this work have the potential to significantly improve the collaboration and integration of domain-specific insights into data-driven decision-making.
The experimental results presented in the paper provide encouraging evidence of the effectiveness of these language model-based techniques. However, the researchers also acknowledge the need for further research to address the limitations and potential ethical concerns associated with this technology.
As data science continues to play an increasingly crucial role in shaping our world, it is essential that we find ways to make these workflows more inclusive and representative of diverse domain expertise. The ideas explored in this paper represent an important step in that direction, and the researchers' ongoing work in this area will be valuable for the broader data science community.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Leveraging Large Language Models to Enhance Domain Expert Inclusion in Data Science Workflows
Jasmine Y. Shih, Vishal Mohanty, Yannis Katsis, Hariharan Subramonyam
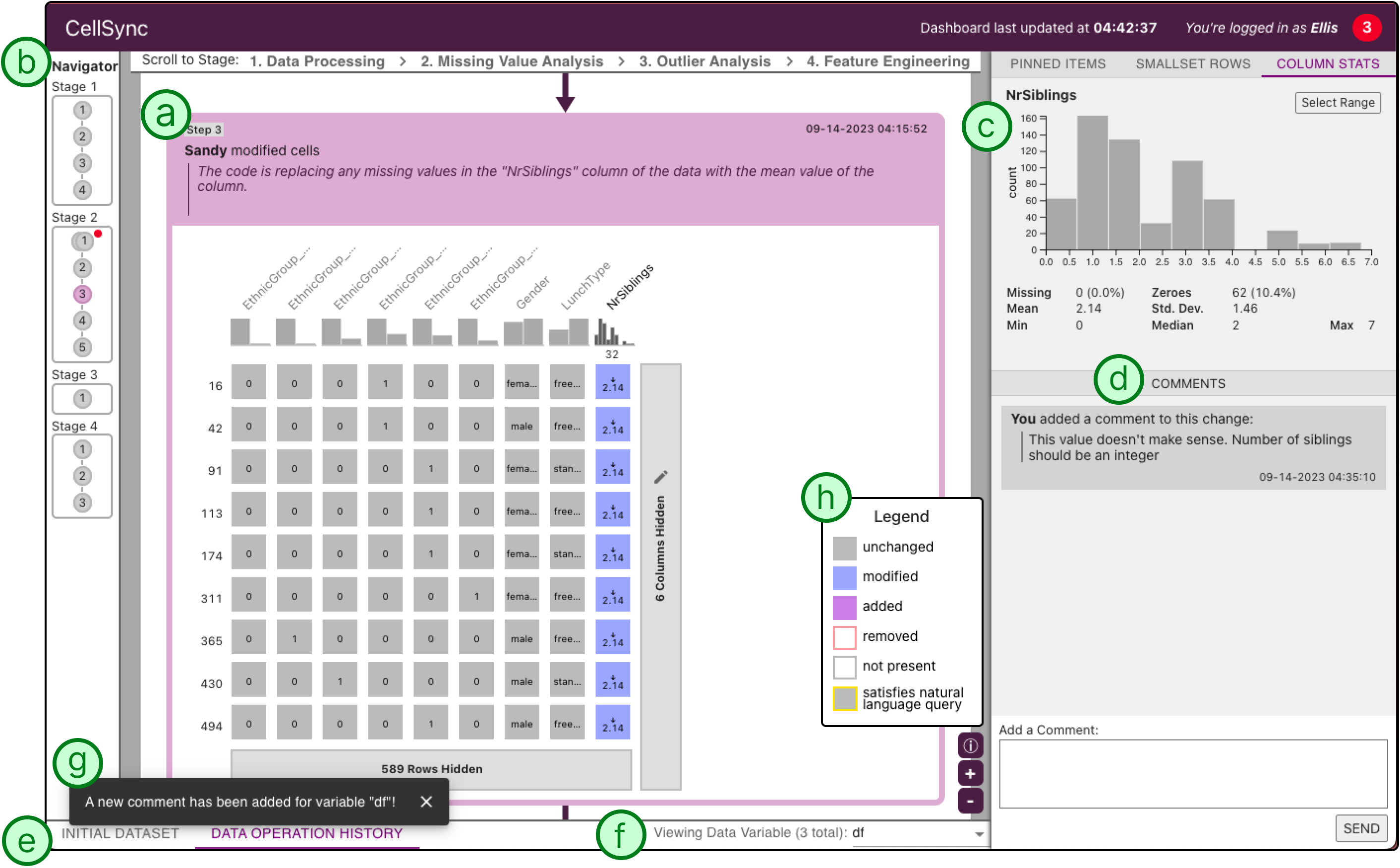
Domain experts can play a crucial role in guiding data scientists to optimize machine learning models while ensuring contextual relevance for downstream use. However, in current workflows, such collaboration is challenging due to differing expertise, abstract documentation practices, and lack of access and visibility into low-level implementation artifacts. To address these challenges and enable domain expert participation, we introduce CellSync, a collaboration framework comprising (1) a Jupyter Notebook extension that continuously tracks changes to dataframes and model metrics and (2) a Large Language Model powered visualization dashboard that makes those changes interpretable to domain experts. Through CellSync's cell-level dataset visualization with code summaries, domain experts can interactively examine how individual data and modeling operations impact different data segments. The chat features enable data-centric conversations and targeted feedback to data scientists. Our preliminary evaluation shows that CellSync provides transparency and promotes critical discussions about the intents and implications of data operations.
Read more5/6/2024

0
Knowledge AI: Fine-tuning NLP Models for Facilitating Scientific Knowledge Extraction and Understanding
Balaji Muralidharan, Hayden Beadles, Reza Marzban, Kalyan Sashank Mupparaju
This project investigates the efficacy of Large Language Models (LLMs) in understanding and extracting scientific knowledge across specific domains and to create a deep learning framework: Knowledge AI. As a part of this framework, we employ pre-trained models and fine-tune them on datasets in the scientific domain. The models are adapted for four key Natural Language Processing (NLP) tasks: summarization, text generation, question answering, and named entity recognition. Our results indicate that domain-specific fine-tuning significantly enhances model performance in each of these tasks, thereby improving their applicability for scientific contexts. This adaptation enables non-experts to efficiently query and extract information within targeted scientific fields, demonstrating the potential of fine-tuned LLMs as a tool for knowledge discovery in the sciences.
Read more8/12/2024
⚙️
0
Translating Expert Intuition into Quantifiable Features: Encode Investigator Domain Knowledge via LLM for Enhanced Predictive Analytics
Phoebe Jing, Yijing Gao, Yuanhang Zhang, Xianlong Zeng
In the realm of predictive analytics, the nuanced domain knowledge of investigators often remains underutilized, confined largely to subjective interpretations and ad hoc decision-making. This paper explores the potential of Large Language Models (LLMs) to bridge this gap by systematically converting investigator-derived insights into quantifiable, actionable features that enhance model performance. We present a framework that leverages LLMs' natural language understanding capabilities to encode these red flags into a structured feature set that can be readily integrated into existing predictive models. Through a series of case studies, we demonstrate how this approach not only preserves the critical human expertise within the investigative process but also scales the impact of this knowledge across various prediction tasks. The results indicate significant improvements in risk assessment and decision-making accuracy, highlighting the value of blending human experiential knowledge with advanced machine learning techniques. This study paves the way for more sophisticated, knowledge-driven analytics in fields where expert insight is paramount.
Read more5/15/2024

0
Curated LLM: Synergy of LLMs and Data Curation for tabular augmentation in low-data regimes
Nabeel Seedat, Nicolas Huynh, Boris van Breugel, Mihaela van der Schaar
Machine Learning (ML) in low-data settings remains an underappreciated yet crucial problem. Hence, data augmentation methods to increase the sample size of datasets needed for ML are key to unlocking the transformative potential of ML in data-deprived regions and domains. Unfortunately, the limited training set constrains traditional tabular synthetic data generators in their ability to generate a large and diverse augmented dataset needed for ML tasks. To address this challenge, we introduce CLLM, which leverages the prior knowledge of Large Language Models (LLMs) for data augmentation in the low-data regime. However, not all the data generated by LLMs will improve downstream utility, as for any generative model. Consequently, we introduce a principled curation mechanism, leveraging learning dynamics, coupled with confidence and uncertainty metrics, to obtain a high-quality dataset. Empirically, on multiple real-world datasets, we demonstrate the superior performance of CLLM in the low-data regime compared to conventional generators. Additionally, we provide insights into the LLM generation and curation mechanism, shedding light on the features that enable them to output high-quality augmented datasets.
Read more7/2/2024