OpenSU3D: Open World 3D Scene Understanding using Foundation Models

0
Sign in to get full access
Overview
- OpenSU3D is a new approach for open-world 3D scene understanding using foundation models.
- It aims to enable models to understand and reason about 3D scenes in an open-ended and zero-shot manner.
- The key idea is to leverage large-scale multimodal foundation models trained on diverse internet data.
Plain English Explanation
OpenSU3D is a new way of helping computers understand 3D scenes in a more flexible and open-ended manner. The key idea is to use large AI models that have been trained on a vast amount of diverse online data. These "foundation models" can then be applied to understand and reason about 3D scenes, even if the specific objects or scenarios have not been seen before.
The goal is to move beyond the limitations of traditional 3D scene understanding systems, which are often narrow in their capabilities and require extensive training on specific datasets. With OpenSU3D, the hope is that computers can more flexibly comprehend and interact with the 3D world around them, much like how humans can easily understand and reason about novel environments and objects.
By leveraging these powerful foundation models, OpenSU3D aims to enable more open-vocabulary and unified 3D scene understanding, breaking down barriers and opening up new possibilities for how AI systems can perceive and interact with the 3D world.
Technical Explanation
The key technical innovation of OpenSU3D is its use of large-scale multimodal foundation models as the core building blocks for 3D scene understanding. These models, trained on diverse internet data spanning text, images, and other modalities, have been shown to capture rich and generalizable representations of the world.
By probing the 3D awareness of these foundation models and fine-tuning them on 3D scene understanding tasks, the OpenSU3D framework aims to enable zero-shot and open-vocabulary 3D scene parsing, object detection, and reasoning. This allows the models to understand and reason about 3D scenes in a more open-set manner, without being limited to a predefined set of object categories or scene configurations.
The key technical components of OpenSU3D include:
- Multimodal foundation model pre-training on diverse internet data
- Probing and fine-tuning the foundation models for 3D scene understanding tasks
- Novel architectural designs and training strategies to leverage the foundation model representations
Through thorough experimentation and evaluation, the authors demonstrate the powerful capabilities of OpenSU3D in handling a wide range of 3D scene understanding challenges, outperforming prior state-of-the-art approaches.
Critical Analysis
While the OpenSU3D framework presents an exciting new direction for 3D scene understanding, the authors acknowledge several limitations and areas for further research. One key concern is the reliance on large-scale foundation models, which can be resource-intensive and challenging to deploy in real-world applications.
Additionally, the paper does not fully address the potential biases and limitations inherent in the foundation models, which may be reflected in the downstream 3D scene understanding capabilities. Further research is needed to better understand and mitigate these issues.
It would also be valuable to explore the robustness and generalization of OpenSU3D to more diverse and challenging 3D environments, beyond the specific benchmarks presented in the paper. Exploring the model's performance on real-world 3D data, as well as its ability to handle dynamic and cluttered scenes, would be important next steps.
Overall, the OpenSU3D framework represents a promising step towards more flexible and open-ended 3D scene understanding, but continued research and development will be necessary to address the remaining challenges and fully realize its potential.
Conclusion
The OpenSU3D framework presents an innovative approach to 3D scene understanding that leverages powerful multimodal foundation models. By probing and fine-tuning these models for 3D scene understanding tasks, OpenSU3D aims to enable more open-vocabulary and unified 3D perception, opening up new possibilities for how AI systems can interact with and reason about the 3D world.
While the framework shows promising results, continued research is needed to address the remaining challenges, such as the resource-intensive nature of foundation models and the potential for biases. Exploring the robustness and generalization of OpenSU3D to diverse real-world 3D environments will also be a crucial next step.
Overall, the OpenSU3D approach represents an exciting step forward in the field of 3D scene understanding, with the potential to unlock new frontiers in how AI systems perceive and interact with the 3D world around them.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
OpenSU3D: Open World 3D Scene Understanding using Foundation Models
Rafay Mohiuddin, Sai Manoj Prakhya, Fiona Collins, Ziyuan Liu, Andr'e Borrmann
In this paper, we present a novel, scalable approach for constructing open set, instance-level 3D scene representations, advancing open world understanding of 3D environments. Existing methods require pre-constructed 3D scenes and face scalability issues due to per-point feature vector learning, limiting their efficacy with complex queries. Our method overcomes these limitations by incrementally building instance-level 3D scene representations using 2D foundation models, efficiently aggregating instance-level details such as masks, feature vectors, names, and captions. We introduce fusion schemes for feature vectors to enhance their contextual knowledge and performance on complex queries. Additionally, we explore large language models for robust automatic annotation and spatial reasoning tasks. We evaluate our proposed approach on multiple scenes from ScanNet and Replica datasets demonstrating zero-shot generalization capabilities, exceeding current state-of-the-art methods in open world 3D scene understanding.
Read more9/17/2024

0
UniM-OV3D: Uni-Modality Open-Vocabulary 3D Scene Understanding with Fine-Grained Feature Representation
Qingdong He, Jinlong Peng, Zhengkai Jiang, Kai Wu, Xiaozhong Ji, Jiangning Zhang, Yabiao Wang, Chengjie Wang, Mingang Chen, Yunsheng Wu
3D open-vocabulary scene understanding aims to recognize arbitrary novel categories beyond the base label space. However, existing works not only fail to fully utilize all the available modal information in the 3D domain but also lack sufficient granularity in representing the features of each modality. In this paper, we propose a unified multimodal 3D open-vocabulary scene understanding network, namely UniM-OV3D, which aligns point clouds with image, language and depth. To better integrate global and local features of the point clouds, we design a hierarchical point cloud feature extraction module that learns comprehensive fine-grained feature representations. Further, to facilitate the learning of coarse-to-fine point-semantic representations from captions, we propose the utilization of hierarchical 3D caption pairs, capitalizing on geometric constraints across various viewpoints of 3D scenes. Extensive experimental results demonstrate the effectiveness and superiority of our method in open-vocabulary semantic and instance segmentation, which achieves state-of-the-art performance on both indoor and outdoor benchmarks such as ScanNet, ScanNet200, S3IDS and nuScenes. Code is available at https://github.com/hithqd/UniM-OV3D.
Read more4/23/2024

0
OpenOcc: Open Vocabulary 3D Scene Reconstruction via Occupancy Representation
Haochen Jiang, Yueming Xu, Yihan Zeng, Hang Xu, Wei Zhang, Jianfeng Feng, Li Zhang
3D reconstruction has been widely used in autonomous navigation fields of mobile robotics. However, the former research can only provide the basic geometry structure without the capability of open-world scene understanding, limiting advanced tasks like human interaction and visual navigation. Moreover, traditional 3D scene understanding approaches rely on expensive labeled 3D datasets to train a model for a single task with supervision. Thus, geometric reconstruction with zero-shot scene understanding i.e. Open vocabulary 3D Understanding and Reconstruction, is crucial for the future development of mobile robots. In this paper, we propose OpenOcc, a novel framework unifying the 3D scene reconstruction and open vocabulary understanding with neural radiance fields. We model the geometric structure of the scene with occupancy representation and distill the pre-trained open vocabulary model into a 3D language field via volume rendering for zero-shot inference. Furthermore, a novel semantic-aware confidence propagation (SCP) method has been proposed to relieve the issue of language field representation degeneracy caused by inconsistent measurements in distilled features. Experimental results show that our approach achieves competitive performance in 3D scene understanding tasks, especially for small and long-tail objects.
Read more8/12/2024
0
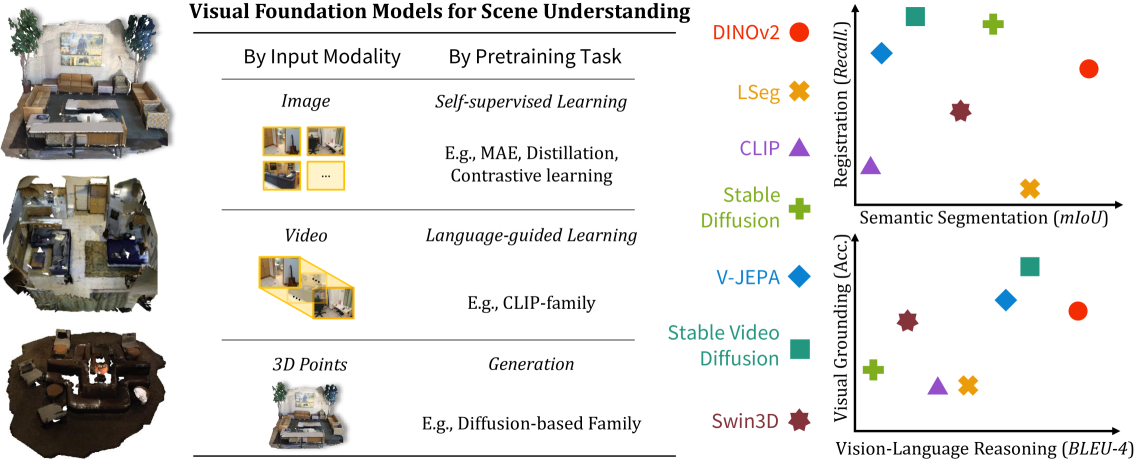
Lexicon3D: Probing Visual Foundation Models for Complex 3D Scene Understanding
Yunze Man, Shuhong Zheng, Zhipeng Bao, Martial Hebert, Liang-Yan Gui, Yu-Xiong Wang
Complex 3D scene understanding has gained increasing attention, with scene encoding strategies playing a crucial role in this success. However, the optimal scene encoding strategies for various scenarios remain unclear, particularly compared to their image-based counterparts. To address this issue, we present a comprehensive study that probes various visual encoding models for 3D scene understanding, identifying the strengths and limitations of each model across different scenarios. Our evaluation spans seven vision foundation encoders, including image-based, video-based, and 3D foundation models. We evaluate these models in four tasks: Vision-Language Scene Reasoning, Visual Grounding, Segmentation, and Registration, each focusing on different aspects of scene understanding. Our evaluations yield key findings: DINOv2 demonstrates superior performance, video models excel in object-level tasks, diffusion models benefit geometric tasks, and language-pretrained models show unexpected limitations in language-related tasks. These insights challenge some conventional understandings, provide novel perspectives on leveraging visual foundation models, and highlight the need for more flexible encoder selection in future vision-language and scene-understanding tasks.
Read more9/6/2024